แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
เรียนรู้วิธีดีบักการเชื่อมต่อเว็บฮุคด้วยการมาตรฐานลายเซ็น จัดการรีไทรอย่างปลอดภัย เปิดใช้งานรีเพลย์ และเก็บบันทึกเหตุการณ์ที่ค้นหาได้ง่าย
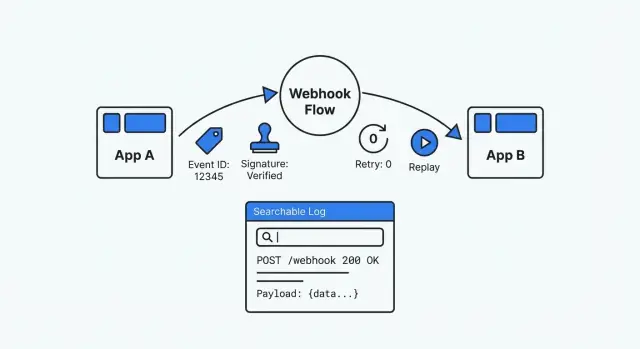
เว็บฮุคคือแอปหนึ่งเรียกแอปของคุณเมื่อมีบางอย่างเกิดขึ้น — ผู้ให้บริการการชำระเงินบอกว่า “การชำระเงินสำเร็จ” เครื่องมือฟอร์มแจ้งว่า “มีการส่งใหม่” หรือ CRM รายงานว่า “ดีลอัปเดตแล้ว” มันดูเรียบง่ายจนกว่าจะมีบางอย่างพังแล้วคุณพบว่าไม่มีหน้าจอจะเปิด ไม่มีประวัติชัดเจน และไม่มีวิธีปลอดภัยในการรีเพลย์สิ่งที่เกิดขึ้น
นั่นคือเหตุผลที่ปัญหาเว็บฮุคทำให้หงุดหงิด คำขออาจมาถึง (หรือไม่มาถึง) ระบบของคุณประมวลผลมัน (หรือไม่สำเร็จ) สัญญาณแรกมักเป็นตั๋วคลุมเครืออย่าง “ลูกค้าไม่สามารถชำระเงินได้” หรือ “สถานะไม่อัปเดต” หากผู้ให้บริการรีไทร คุณอาจได้รับการส่งซ้ำ หากพวกเขาเปลี่ยนฟิลด์ของ payload ตัวแยกวิเคราะห์อาจพังเฉพาะบางบัญชี
อาการทั่วไป:
การตั้งค่าที่ดีสำหรับการดีบักเว็บฮุคเป็นตรงกันข้ามกับการเดา — ต้องตรวจสอบย้อนกลับได้ (คุณหาการส่งแต่ละครั้งและสิ่งที่คุณทำกับมันได้), ทำซ้ำได้อย่างปลอดภัย (คุณสามารถรีเพลย์เหตุการณ์ที่ผ่านมาได้), และตรวจสอบได้ (คุณพิสูจน์ความแท้และผลการประมวลผลได้) เมื่อมีคนถามว่า “เกิดอะไรกับเหตุการณ์นี้?” คุณควรตอบด้วยหลักฐานในไม่กี่นาที
ถ้าคุณสร้างแอปบนแพลตฟอร์มอย่าง AppMaster, แนวคิดนี้ยิ่งสำคัญขึ้นอีก ตรรกะแบบภาพเปลี่ยนเร็ว แต่คุณยังต้องมีประวัติเหตุการณ์ที่ชัดและรีเพลย์ที่ปลอดภัยเพื่อไม่ให้ระบบภายนอกกลายเป็นกล่องดำ
เมื่อคุณกำลังดีบักภายใต้ความกดดัน คุณต้องมีพื้นฐานเดียวกันทุกครั้ง: ระเบียนที่เชื่อถือได้ ค้นหาได้ และรีเพลย์ได้ หากไม่มีสิ่งนี้ เว็บฮุคแต่ละรายการจะเป็นปริศนาแบบครั้งเดียว
กำหนดความหมายของ “เหตุการณ์” เว็บฮุคเดียวในระบบของคุณ ปฏิบัติเหมือนใบเสร็จ: คำขอขาเข้าหนึ่งรายการเท่ากับเหตุการณ์ที่เก็บไว้หนึ่งรายการ แม้ว่าการประมวลผลจะเกิดขึ้นภายหลัง
อย่างน้อย ให้บันทึก:
received_at แยกจาก timestamp ใน payloadตัวอย่าง: ผู้ให้บริการการชำระเงินส่งเหตุการณ์ “payment_succeeded” แต่ลูกค้าของคุณยังแสดงว่ายังไม่ได้จ่าย ถ้าบันทึกเหตุการณ์ของคุณมีคำขอดิบ คุณยืนยันลายเซ็นและเห็นจำนวนเงินและสกุลเงินที่แน่นอนได้ หากมันยังรวม invoice_id ฝ่ายสนับสนุนสามารถหาเหตุการณ์จาก invoice เห็นว่าติดอยู่ในสถานะ “failed” และส่งต่อให้วิศวกรรมพร้อมเหตุผลข้อผิดพลาดที่ชัดเจน
ใน AppMaster วิธีปฏิบัติหนึ่งคือมีตาราง “WebhookEvent” ใน Data Designer โดยมี Business Process อัปเดตสถานะเมื่อแต่ละขั้นตอนเสร็จ เครื่องมือไม่ใช่ประเด็น สิ่งสำคัญคือระเบียนที่สม่ำเสมอ
ถ้าผู้ให้บริการแต่ละรายส่งรูปแบบ payload ต่างกัน ล็อกของคุณจะวุ่นเสมอ ซองเหตุการณ์ที่มั่นคงช่วยให้การดีบักเร็วขึ้นเพราะคุณสามารถมองหาฟิลด์เดิม ๆ ทุกครั้ง แม้ว่าข้อมูลจะเปลี่ยน
ซองที่มีประโยชน์มักรวม:
id (unique event id)type (ชื่อเหตุการณ์ชัดเจน เช่น invoice.paid)created_at (เมื่อเหตุการณ์เกิดขึ้น ไม่ใช่เมื่อคุณได้รับ)data (payload ทางธุรกิจ)version (เช่น v1)นี่คือตัวอย่างง่าย ๆ ที่คุณสามารถบันทึกและเก็บตามที่เป็น:
{
"id": "evt_01H...",
"type": "payment.failed",
"created_at": "2026-01-25T10:12:30Z",
"version": "v1",
"correlation": {"order_id": "A-10492", "customer_id": "C-883"},
"data": {"amount": 4990, "currency": "USD", "reason": "insufficient_funds"}
}
เลือกสไตล์การตั้งชื่อเดียว (snake_case หรือ camelCase) และยึดมั่นกับมัน เข้มงวดเรื่องชนิดข้อมูลด้วย: อย่าให้ amount เป็นสตริงบางครั้งและเป็นตัวเลขบางครั้ง
การเวอร์ชันเป็นตาข่ายนิรภัยของคุณ เมื่อต้องการเปลี่ยนฟิลด์ ให้เผยแพร่ v2 ในขณะที่ยังคง v1 ทำงานได้สักพัก มันป้องกันเหตุการณ์ฝ่ายสนับสนุนและช่วยให้การอัปเกรดดีบักง่ายขึ้น
ลายเซ็นช่วยป้องกันไม่ให้ endpoint ของคุณกลายเป็นประตูเปิด ถ้าไม่มีการตรวจสอบ ใครก็ได้ที่รู้ URL สามารถส่งเหตุการณ์ปลอมได้ และผู้โจมตีอาจพยายามดัดแปลงคำขอจริง
รูปแบบที่พบบ่อยที่สุดคือ HMAC พร้อมความลับร่วม ผู้ส่งลงลายเซ็นกับ raw request body (ดีที่สุด) หรือสตริง canonical คุณคำนวณ HMAC ใหม่และเปรียบเทียบ ผู้ให้บริการหลายรายรวม timestamp ในสิ่งที่ลงนามเพื่อไม่ให้คำขอที่จับได้ถูกรีเพลย์หลังจากนั้น
รูทีนการยืนยันควรน่าเบื่อและสม่ำเสมอ:
ทำให้มันทดสอบได้ ใส่การยืนยันไว้ในฟังก์ชันเล็ก ๆ และเขียนเทสต์ด้วยตัวอย่างที่รู้ว่าถูกและผิด เวลาเสียไปมากมักมาจากการลงลายเซ็นกับ JSON ที่แปลงแล้วแทนที่จะเป็นไบต์ดิบ
วางแผนการหมุนความลับตั้งแต่วันแรก รองรับความลับสองชุดที่ใช้งานได้พร้อมกันในช่วงเปลี่ยน: ลองอันใหม่ก่อน แล้วถ้าล้มเหลวให้ย้อนกลับไปอันก่อนหน้า
เมื่อการยืนยันล้มเหลว ให้บันทึกข้อมูลพอสำหรับดีบักโดยไม่รั่วไหลความลับ: ชื่อผู้ให้บริการ timestamp (และว่ามันเก่าหรือไม่) เวอร์ชันลายเซ็น request/correlation ID และ hash สั้นของ raw body (ไม่ใช่ตัวเนื้อหา)
รีไทรเป็นเรื่องปกติ ผู้ให้บริการจะรีไทรเมื่อเกิด timeout, ปัญหาเครือข่าย หรือการตอบกลับ 5xx แม้ว่าระบบของคุณจะทำงานเสร็จแล้ว ผู้ให้บริการอาจไม่ได้รับการตอบกลับของคุณทันเวลา ดังนั้นเหตุการณ์เดียวกันอาจถูกส่งมาอีกครั้ง
กำหนดล่วงหน้าว่าการตอบกลับแบบใดหมายความว่า “ให้รีไทร” กับ “หยุด” ทีมหลายทีมใช้กฎเช่น:
Idempotency หมายความว่าคุณรับมือเหตุการณ์เดิมได้มากกว่าหนึ่งครั้งโดยไม่ทำผลข้างเคียงซ้ำ (ไม่เรียกเก็บซ้ำ ไม่สร้างคำสั่งซื้อซ้ำ ไม่ส่งอีเมลซ้ำ) ปฏิบัติเว็บฮุคเหมือน at-least-once delivery
รูปแบบปฏิบัติได้คือเก็บ ID เหตุการณ์ที่เข้ามาพร้อมผลลัพธ์ของการประมวลผล เมื่อรับส่งซ้ำ:
สำหรับการรีไทรภายใน ให้ใช้ exponential backoff และจำกัดจำนวนครั้ง หลังจากเกินขีดจำกัด ให้ย้ายเหตุการณ์ไปสถานะ “ต้องการการตรวจสอบ” พร้อมข้อผิดพลาดสุดท้าย ใน AppMaster สิ่งนี้สอดคล้องกับตารางขนาดเล็กสำหรับ event IDs และสถานะ บวก Business Process ที่ตารางเวลาการรีไทรและจัดการความล้มเหลวซ้ำ
รีไทรเป็นอัตโนมัติ รีเพลย์เป็นความตั้งใจ
เครื่องมือรีเพลย์เปลี่ยนจาก “คิดว่ามันส่งแล้ว” เป็นการทดสอบที่ทำซ้ำได้ด้วย payload เดิมเป๊ะ มันปลอดภัยเฉพาะเมื่อสองสิ่งเป็นจริง: idempotency และร่องรอยตรวจสอบ (audit trail) Idempotency ป้องกันการเรียกเก็บซ้ำ การส่งซ้ำ หรือการส่งอีเมลซ้ำ ร่องรอยตรวจสอบแสดงว่าใครรีเพลย์ อะไรถูกรีเพลย์ และผลลัพธ์เป็นอย่างไร
รีเพลย์เหตุการณ์เดี่ยวเป็นกรณีสนับสนุนทั่วไป: ลูกค้าคนเดียว เหตุการณ์หนึ่งล้มเหลว ส่งใหม่หลังแก้ไข รีเพลย์ช่วงเวลาเหมาะกับเหตุการณ์ใหญ่: เมื่อผู้ให้บริการมีปัญหาในหน้าต่างเวลาหนึ่งและคุณต้องส่งใหม่ทุกสิ่งที่ล้มเหลว
เก็บการเลือกให้เรียบง่าย: กรองตามประเภทเหตุการณ์ ช่วงเวลา และสถานะ (failed, timed out, หรือ delivered แต่ไม่ได้รับการยืนยัน) แล้วรีเพลย์ทีละเหตุการณ์หรือแบบเป็นชุด
รีเพลย์ควรทรงพลัง แต่ไม่อันตราย มาตรการป้องกันบางอย่างช่วยได้:
หลังรีเพลย์ ให้แสดงผลถัดจากเหตุการณ์ต้นฉบับ: สำเร็จ, ยังคงล้มเหลว (พร้อมข้อผิดพลาดล่าสุด), หรือถูกละไว้ (ตรวจพบซ้ำผ่าน idempotency)
เมื่อเว็บฮุคพังในเหตุการณ์ฉุกเฉิน คุณต้องการคำตอบในไม่กี่นาที ล็อกที่ดีเล่าเรื่องชัดเจน: อะไรเข้ามา คุณทำอะไรกับมัน และมันหยุดที่ไหน
เก็บคำขอดิบตามที่ได้รับ: timestamp, path, method, headers, และ raw body ข้อมูลดิบนี้คือต้นทางความจริงเมื่อผู้ขายเปลี่ยนฟิลด์หรือ parser ของคุณอ่านข้อมูลผิด ให้ปิดบังค่าที่ละเอียดอ่อนก่อนบันทึก (authorization headers, tokens และข้อมูลส่วนบุคคลหรือข้อมูลการชำระเงินที่คุณไม่จำเป็นต้องเก็บ)
ข้อมูลดิบอย่างเดียวไม่พอ เก็บมุมมองที่แยกวิเคราะห์และค้นหาได้ด้วย: ประเภทเหตุการณ์, external event ID, ตัวระบุลูกค้า/บัญชี, ID ของวัตถุที่เกี่ยวข้อง (invoice_id, order_id) และ internal correlation ID ของคุณ สิ่งนี้ช่วยให้ฝ่ายสนับสนุนค้นหา “เหตุการณ์ทั้งหมดของลูกค้า 8142” โดยไม่ต้องเปิด payload ทุกชิ้น
ระหว่างการประมวลผล เก็บไทม์ไลน์สั้น ๆ ของแต่ละขั้นตอนด้วยคำศัพท์ที่สม่ำเสมอ เช่น: “validated signature”, “mapped fields”, “checked idempotency”, “updated records”, “queued follow-ups”
การเก็บรักษาข้อมูลสำคัญ เก็บประวัติพอครอบคลุมความล่าช้าจริงและข้อพิพาท แต่ไม่ควรเก็บถาวรโดยไม่จำเป็น พิจารณาลบหรือทำให้เป็นนิรนาม payload ดิบก่อนในขณะที่เก็บเมตาดาต้าขนาดเล็กไว้นานกว่า
สร้างตัวรับเหมือนท่อเล็ก ๆ ที่มีจุดตรวจชัดเจน ทุกคำขอกลายเป็นเหตุการณ์ที่เก็บไว้ ทุกการรันประมวลผลเป็นความพยายามหนึ่งครั้ง และทุกความล้มเหลวต้องค้นหาได้
ปฏิบัติต่อ endpoint HTTP เป็นการรับเข้าเท่านั้น ทำงานขั้นต่ำที่จุดรับ แล้วย้ายการประมวลผลไปยัง worker เพื่อให้ timeout ไม่กลายเป็นพฤติกรรมปริศนา
ในทางปฏิบัติ คุณจะต้องการระเบียนหลักสองอัน: แถวหนึ่งต่อเหตุการณ์เว็บฮุค และแถวหนึ่งต่อความพยายามในการประมวลผล
โมเดลเหตุการณ์ที่มั่นคงรวม: event_id, provider, received_at, signature_status, payload_hash, payload_json (หรือ raw payload), current_status, last_error, next_retry_at ระเบียนความพยายามเก็บ: attempt_number, started_at, finished_at, http_status (ถ้ามี), error_code, error_text
เมื่อข้อมูลอยู่แล้ว เพิ่มหน้าแอดมินเล็ก ๆ เพื่อให้ฝ่ายสนับสนุนค้นหาตาม event ID, customer ID หรือช่วงเวลา และกรองตามสถานะ เก็บให้เรียบง่ายและเร็ว
ตั้งการแจ้งเตือนตามรูปแบบ ไม่ใช่ความล้มเหลวแบบครั้งเดียว ตัวอย่าง: “ผู้ให้บริการล้มเหลว 10 ครั้งใน 5 นาที” หรือ “เหตุการณ์ติดอยู่ในสถานะ failed”
ถ้าคุณควบคุมฝั่งส่ง ให้มาตรฐานสามสิ่งเสมอ: ใส่ event ID เสมอ, ลงลายเซ็น payload แบบเดียวเสมอ, และเผยแพร่นโยบายรีไทรเป็นภาษาธรรมดา มันป้องกันการเถียงไปมาเมื่อพันธมิตรบอกว่า “เราส่งแล้ว” แต่ระบบของคุณไม่มีอะไรแสดง
รูปแบบทั่วไปคือเว็บฮุคของ Stripe ที่ทำสองอย่าง: สร้างเรคอร์ด Order แล้วส่งใบเสร็จทางอีเมล/SMS ฟังดูเรียบง่ายจนกว่าเหตุการณ์หนึ่งจะล้มเหลวและไม่มีใครรู้ว่าลูกค้าถูกเรียกเก็บเงินหรือไม่ คำสั่งซื้อมีหรือยัง หรือใบเสร็จส่งออกไปหรือยัง
นี่คือลักษณะความล้มเหลวที่สมจริง: คุณหมุนความลับการลงลายเซ็นของ Stripe ในช่วงเวลาสั้น ๆ endpoint ของคุณยังยืนยันด้วยความลับเดิมอยู่ ดังนั้น Stripe ส่งเหตุการณ์ แต่เซิร์ฟเวอร์ของคุณปฏิเสธด้วย 401/400 แดชบอร์ดแสดง “webhook failed” ในขณะที่ล็อกแอปของคุณบอกแค่ว่า “invalid signature”
ล็อกที่ดีย่อมทำให้สาเหตุชัดเจน สำหรับเหตุการณ์ที่ล้มเหลว ระเบียนควรแสดง event ID ที่มั่นคงพร้อมรายละเอียดการยืนยันพอที่จะระบุความไม่ตรงกัน: เวอร์ชันลายเซ็น, timestamp ของลายเซ็น, ผลการยืนยัน และเหตุผลการปฏิเสธชัดเจน (ความลับผิด vs ความเบี่ยงของ timestamp) ในช่วงการหมุน ความช่วยเหลือคือการบันทึกว่าทดลองความลับใด (เช่น "current" กับ "previous") ไม่ใช่ความลับดิบ
เมื่อความลับถูกแก้และทั้ง "current" และ "previous" ยอมรับได้ในช่วงสั้น ๆ คุณยังต้องจัดการแบ็กล็อก เครื่องมือรีเพลย์เปลี่ยนงานนั้นเป็นงานด่วน:
ปัญหาเว็บฮุคส่วนใหญ่ดูเป็นปริศนาเพราะระบบบันทึกแค่ข้อผิดพลาดสุดท้าย ปฏิบัติให้ทุกการส่งเหมือนรายงานเหตุการณ์เล็ก ๆ: อะไรเข้ามา คุณตัดสินใจอย่างไร และเกิดอะไรขึ้นต่อ
ความผิดพลาดซ้ำ ๆ ที่พบบ่อย:
การแก้ไขเชิงปฏิบัติ:
ถ้าคุณใช้ AppMaster, ส่วนประกอบเหล่านี้เข้ากันได้อย่างเป็นธรรมชาติบนแพลตฟอร์ม: ตารางเหตุการณ์ใน Data Designer, Business Process ขับเคลื่อนสถานะสำหรับการยืนยันและประมวลผล, และ UI แอดมินสำหรับการค้นหาและรีเพลย์
ตั้งเป้าหมายให้ได้พื้นฐานเดียวกันทุกครั้ง:
การขาดเพียงข้อเดียวก็อาจทำให้การผสานกลับเป็นกล่องดำได้ หากคุณไม่เก็บ payload ดิบ คุณพิสูจน์ไม่ได้ว่าผู้ให้บริการส่งอะไรมา หากการล้มเหลวของลายเซ็นไม่ชัด คุณจะเสียเวลาหลายชั่วโมงโต้เถียงว่าเป็นความผิดของใคร
ถ้าคุณต้องการสร้างสิ่งนี้อย่างรวดเร็วโดยไม่เขียนโค้ดทุกส่วนด้วยมือ AppMaster (appmaster.io) สามารถช่วยรวมโมเดลข้อมูล กระบวนการประมวลผล และ UI ผู้ดูแลไว้ในที่เดียว ในขณะที่ยังสร้างซอร์สโค้ดจริงสำหรับแอปสุดท้ายของคุณ



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


