แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
CI/CD สำหรับ backend Go: ขั้นตอน pipeline ปฏิบัติได้จริงสำหรับการ build, test, migrations และการ deploy ที่ปลอดภัยไปยัง Kubernetes หรือ VMs ด้วยสภาพแวดล้อมที่คาดเดาได้.
การ deploy แบบแมนนวลล้มเหลวด้วยวิธีซ้ำๆ ที่น่าเบื่อ: คนหนึ่ง build บนเครื่องของตัวเองด้วยเวอร์ชัน Go ที่ต่างกัน ลืมตัวแปรสภาพแวดล้อม ข้าม migration หรือ restart service ผิด เวอร์ชันที่ปล่อยออกมา “ใช้ได้บนเครื่องฉัน” แต่ไม่ทำงานใน production และคุณมักรู้เรื่องตอนที่ผู้ใช้เริ่มเจอปัญหา
การมีโค้ดที่สร้างอัตโนมัติไม่ได้ลดความจำเป็นเรื่องวินัยการปล่อย release ลง เมื่อคุณ regenerate backend หลังปรับความต้องการ คุณอาจเพิ่ม endpoints รูปแบบข้อมูลใหม่ หรือ dependency ใหม่ แม้คุณจะไม่ได้แก้โค้ดด้วยมือตรงๆ นั่นคือเวลาที่คุณอยากให้ pipeline ทำหน้าที่เป็นราวกันตก: ทุกการเปลี่ยนแปลงต้องผ่านการตรวจเดิมทุกครั้ง
สภาพแวดล้อมที่คาดเดาได้หมายถึงขั้นตอน build และ deploy ทำงานภายใต้เงื่อนไขที่คุณตั้งชื่อและทำซ้ำได้ กฎไม่กี่ข้อครอบคลุมส่วนใหญ่:
เป้าหมายของ CI/CD สำหรับ backend Go ไม่ใช่แค่การทำให้อัตโนมัติเท่านั้น แต่มันคือการปล่อยที่ทำซ้ำได้ด้วยความเครียดน้อยลง: regenerate, รัน pipeline และเชื่อมั่นว่าสิ่งที่ได้สามารถ deploy ได้
ถ้าคุณใช้ตัวสร้างเช่น AppMaster ที่ผลิต backend Go การ regenerate จะสำคัญยิ่งขึ้น เพราะการ regenerate เป็นฟีเจอร์ แต่จะปลอดภัยก็ต่อเมื่อเส้นทางจากการเปลี่ยนแปลงสู่ production สม่ำเสมอ ได้ทดสอบ และคาดเดาได้
“คาดเดาได้” หมายความว่าอินพุตเดียวกันให้ผลลัพธ์เดียวกันไม่ว่าไปรันที่ไหน สำหรับ CI/CD ของ backend Go นั่นเริ่มจากการตกลงกันว่าอะไรต้องเหมือนกันระหว่าง dev, staging และ prod
สิ่งที่มักไม่ต่อรองได้คือเวอร์ชัน Go, base OS image, build flags และวิธีโหลดค่า config หากส่วนใดเปลี่ยนตาม environment คุณจะเจอเซอร์ไพรส์เช่นพฤติกรรม TLS ต่างกัน แพ็กเกจระบบขาด หรือบั๊กที่โผล่เฉพาะใน production
ความเบี่ยงเบนของ environment มักปรากฏในที่เดียวกัน:
การเลือกระหว่าง Kubernetes และ VMs ไม่ใช่เรื่อง "ดีที่สุด" เสมอไป แต่เป็นเรื่องทีมคุณสามารถรันได้อย่างใจเย็น
Kubernetes เหมาะเมื่อคุณต้องการ autoscaling, rolling updates และวิธีมาตรฐานในการรันบริการจำนวนมาก มันยังช่วยบังคับความสม่ำเสมอเพราะ pods รันจาก image เดียวกัน VMs อาจเหมาะเมื่อคุณมีหนึ่งหรือไม่กี่บริการ ทีมเล็ก และต้องการชิ้นส่วนเคลื่อนไหวน้อยกว่า
คุณยังคงทำให้ pipeline เหมือนกันได้แม้ runtimes ต่างกัน โดยทำให้ artifact และ contract รอบๆ มันเป็นมาตรฐาน ตัวอย่างคือ: เสมอ build image container เดียวกันใน CI, รันขั้นตอนทดสอบเหมือนกัน, และเผยแพร่แพ็กเกจ migration เดียวกัน แล้วเปลี่ยนแค่ขั้นตอน deploy: Kubernetes apply tag ใหม่ ในขณะที่ VMs ดึง image และ restart service
ตัวอย่างเชิงปฏิบัติ: ทีม regenerate backend Go จาก AppMaster และ deploy ไป staging บน Kubernetes แต่ใช้ VM ใน production หากทั้งคู่ดึง image เดียวกันเป๊ะและโหลด config จาก secret store แบบเดียวกัน “runtime ต่างกัน” จะกลายเป็นรายละเอียดการ deploy ไม่ใช่สาเหตุของบั๊ก หากคุณใช้ AppMaster (appmaster.io) โมเดลนี้ก็เข้ากันได้ดีเพราะคุณสามารถ deploy ไปที่ managed cloud หรือ export source code และรัน pipeline เดียวกันบนโครงสร้างพื้นฐานของคุณเอง
Pipeline ที่คาดเดาได้ควรอธิบายง่าย: ตรวจโค้ด, build, พิสูจน์ว่ามันทำงาน, ส่งสิ่งที่คุณทดสอบจริง แล้ว deploy แบบเดิมทุกครั้ง ความชัดเจนนี้สำคัญยิ่งขึ้นเมื่อ backend ของคุณ regenerate (เช่นจาก AppMaster) เพราะการเปลี่ยนแปลงอาจกระทบหลายไฟล์พร้อมกันและคุณต้องการผลตอบรับที่เร็วและสม่ำเสมอ
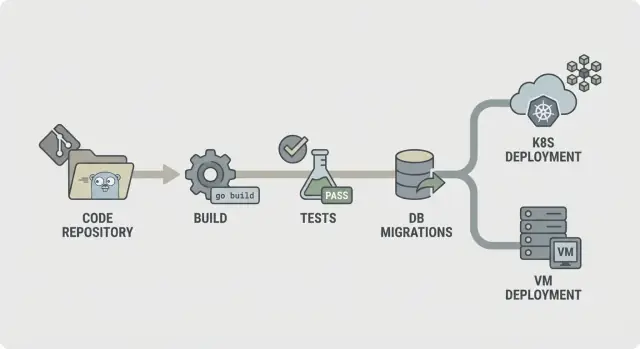
flow CI/CD เบื้องต้นสำหรับ backend Go ดูเหมือน:
จัดโครงสร้างให้ความล้มเหลวหยุดตั้งแต่ต้น หาก lint ล้ม เหลือขั้นตอนอื่นไม่ควรเริ่ม หาก build ล้ม อย่าเสียเวลาเริ่มฐานข้อมูลเพื่อ integration checks นั่นช่วยลดต้นทุนและทำให้ pipeline รู้สึกเร็ว
ไม่ใช่ทุกขั้นตอนต้องรันในทุก commit แบ่งที่พบบ่อยคือ:
ตัดสินใจว่าเก็บอะไรเป็น artifacts ปกติคือ binary คอมไพล์แล้วหรือ container image (สิ่งที่จะ deploy), รวมทั้ง logs ของ migration และรายงานการทดสอบ การเก็บสิ่งเหล่านี้ช่วยให้ rollback และ audit ง่ายขึ้นเพราะคุณชี้ไปยังสิ่งที่ทดสอบและ promote ได้ชัดเจน
build stage ควรตอบคำถามหนึ่งข้อ: เราสามารถผลิตไบนารีเดียวกันวันนี้ พรุ่งนี้ และบน runner อื่นหรือไม่ หากไม่ใช่ ทุกขั้นตอนถัดไป (tests, migrations, deploy) จะยากต่อการเชื่อถือ
เริ่มจากการล็อกสภาพแวดล้อม ใช้เวอร์ชัน Go ตายตัว (เช่น 1.22.x) และ runner image ตายตัว (Linux distro และเวอร์ชันแพ็กเกจ) หลีกเลี่ยง tag แบบ “latest” การเปลี่ยนเล็กน้อยใน libc, Git หรือ Go toolchain อาจสร้างปัญหา "works on my machine" ที่แก้ยาก
การแคชโมดูลช่วยได้ แต่ใช้เป็นการเร่งความเร็วไม่ใช่แหล่งข้อมูลที่ถูกต้อง แคช Go build cache และ module download cache แต่ key ตาม go.sum (หรือเคลียร์มันบน main เมื่อตัว dependency เปลี่ยน) เพื่อให้การดาวน์โหลดสะอาดเมื่อมี dependency ใหม่
เพิ่มประตูตรวจด่วนก่อนการคอมไพล์ ให้มันเร็วพอที่นักพัฒนาจะไม่ข้าม ประกอบด้วย gofmt, go vet และ (ถ้าเร็วพอ) staticcheck ล้มเหลวหากไฟล์ที่ generate หายหรือล้าสมัย ซึ่งเป็นปัญหาทั่วไปในโค้ดเบสที่ regenerate
คอมไพล์แบบ reproducible และฝังข้อมูลเวอร์ชัน flags เช่น -trimpath ช่วย และคุณสามารถตั้ง -ldflags เพื่อฉีด commit SHA และเวลาการ build ผลิต artifact เดียวที่มีชื่อนิ่งสำหรับแต่ละ service นั่นทำให้การหา trace ว่ารันอะไรอยู่ใน Kubernetes หรือ VM ง่ายขึ้น โดยเฉพาะเมื่อ backend ถูก regenerate
การทดสอบช่วยได้ก็ต่อเมื่อมันรันเหมือนเดิมทุกครั้ง เริ่มจาก feedback ที่เร็วก่อน แล้วค่อยเพิ่มการตรวจเชิงลึกที่ยังเสร็จในเวลาที่คาดเดาได้
เริ่มด้วย unit tests ในทุก commit ตั้ง timeout ต่อแพ็กเกจและ timeout งานโดยรวมเพื่อให้การทดสอบที่ค้างล้มเหลวอย่างชัดเจน และตัดสินใจว่าระดับ coverage ที่ “พอ” คือเท่าไรสำหรับทีม Coverage ไม่ใช่ถ้วยรางวัล แต่ระดับขั้นต่ำช่วยป้องกันการไถลของคุณภาพ
stage การทดสอบที่เสถียรมักรวมถึง:
go test ./... พร้อม timeout ต่อแพ็กเกจและ timeout งานรวมrace detector มีประโยชน์แต่ช้าลงมาก ทางออกที่ดีคือรันบน pull requests และ nightly builds หรือเฉพาะบนแพ็กเกจที่เลือก แทนการรันทุก push
การทดสอบ flaky ควรทำให้ build ล้ม หากต้องแยกการทดสอบจริง ให้ย้ายไปเป็น job แยกที่ยังรันและรายงานสถานะแดง พร้อมกำหนด owner และ deadline ในการแก้
เก็บผลการทดสอบไว้เพื่อให้การดีบักไม่ต้องรันซ้ำทั้งชุด บันทึก raw logs และรายงานสรุป (pass/fail, ระยะเวลา, ท็อป slow tests) ช่วยให้เห็น regression ได้ง่ายขึ้น โดยเฉพาะเมื่อการ regenerate กระทบหลายไฟล์
Unit tests บอกว่าโค้ดทำงานแบบแยกส่วน Integration checks บอกว่า service ทำงานถูกต้องเมื่อบูต เชื่อมต่อบริการจริง และตอบคำขอจริง นี่คือตาข่ายความปลอดภัยที่จะจับปัญหาที่โผล่เฉพาะเมื่อทุกอย่างต่อกัน
ใช้ dependency ชั่วคราวเมื่อโค้ดต้องการ เช่น PostgreSQL ชั่วคราว (และ Redis หากใช้) สร้างขึ้นเพื่อ job นั้นมักเพียงพอ เก็บเวอร์ชันให้ใกล้ production แต่ไม่ต้องพยายามคัดลอกทุกรายละเอียด production
integration stage ที่ดีขนาดเล็กโดยตั้งใจ:
สำหรับการตรวจสัญญา API ให้เน้น endpoint ที่พังแล้วส่งผลร้ายแรงที่สุด ไม่ต้องทำชุด end-to-end ทั้งหมด เพียงไม่กี่คำขอที่เป็นความจริง: ฟิลด์ที่จำเป็นถูกปฏิเสธด้วย 400, auth ที่ต้องการคืน 401, และ happy-path คืน 200 พร้อมคีย์ JSON ที่คาดหวัง
เพื่อให้ integration tests เร็วจนนำไปรันบ่อย จำกัดขอบเขตและควบคุมเวลา ใช้ฐานข้อมูลเดียว dataset เล็ก รันเพียงไม่กี่คำขอ และตั้ง timeout ให้ชัดเจนเพื่อให้ boot ที่ติดล้มเหลวในไม่กี่วินาที ไม่ใช่นาที
หากคุณ regenerate backend ของคุณ (เช่นด้วย AppMaster) การตรวจเหล่านี้มีน้ำหนักมากขึ้น เพราะยืนยันว่า service ที่ regenerate ยังคงบูตได้สะอาดและยังสื่อสาร API ที่เว็บหรือแอปมือถือคาดหวัง
เริ่มจากการเลือกว่ารัน migrations ที่ไหน การรันใน CI ดีเพื่อตรวจจับบั๊กแต่โดยปกติ CI ไม่ควรแตะ production ทีมส่วนใหญ่รัน migrations ระหว่าง deploy (เป็นขั้นตอนเฉพาะ) หรือเป็น job “migrate” แยกที่ต้องเสร็จก่อนเวอร์ชันใหม่จะเริ่ม
กฎปฏิบัติคือ: build และทดสอบใน CI แล้วรัน migrations ใกล้ production ที่สุด ด้วยข้อมูลรับรอง production และข้อจำกัดที่คล้าย production ใน Kubernetes นั่นมักเป็น Job แบบ one-off ใน VMs อาจเป็นสคริปต์ในขั้นตอน release
ลำดับสำคัญกว่าที่คนคิด ใช้ไฟล์ที่มี timestamp (หรือหมายเลขต่อเนื่อง) และบังคับ “apply ตามลำดับ, เพียงครั้งเดียว” ทำให้ migration idempotent เมื่อทำได้ เพื่อให้ retry ไม่สร้างซ้ำหรือ crash กลางทาง
กลยุทธ์ migration ที่เรียบง่าย:
เพิ่มเกตความปลอดภัยก่อนรันอะไรเลย อาจเป็นล็อกฐานข้อมูลเพื่อให้มีเพียง migration เดียวรันในครั้งเดียว บวกนโยบายเช่น “ห้าม destructive change โดยไม่มีการอนุมัติ” ตัวอย่างเช่น fail pipeline หาก migration มี DROP TABLE หรือ DROP COLUMN เว้นแต่จะมี gate แบบแมนนวลอนุมัติ
ความจริงเรื่อง rollback: หลายการเปลี่ยน schema ไม่สามารถย้อนกลับได้ หากคุณ drop คอลัมน์ คุณไม่สามารถเอาข้อมูลกลับได้ วางแผน rollback โดยรอบแก้ไปข้างหน้า: เก็บ down migration เมื่อปลอดภัยจริง ๆ และพึ่งพา backup บวก forward migration เมื่อไม่ปลอดภัย
จับคู่แต่ละ migration กับแผนกู้คืน: จะทำอย่างไรหากมันล้มกลางทาง และจะทำอย่างไรหากต้อง rollback แอป หากคุณ generate backend Go (เช่นด้วย AppMaster) ปฏิบัติต่อ migrations เป็นส่วนของสัญญาการปล่อยเพื่อให้โค้ดที่ regenerate และ schema อยู่ในจังหวะเดียวกัน
Pipeline จะรู้สึกคาดเดาได้เมื่อสิ่งที่คุณ deploy คือสิ่งที่คุณทดสอบเสมอ นั่นคือเรื่องของการแพ็กเกจและคอนฟิก ปฏิบัติต่อผลลัพธ์การ build เป็น artifact ปิดผนึกและเก็บความต่างของ environment ไว้นอกมัน
การแพ็กเกจมักมีสองทางเลือก หนึ่งคือ container image ซึ่งเป็นค่าเริ่มต้นถ้าคุณ deploy ไป Kubernetes เพราะมันล็อก OS layer และทำให้ rollout สม่ำเสมอ bundle สำหรับ VM ก็เชื่อถือได้เมื่อต้องใช้ VM ตราบใดที่รวม binary คอมไพล์แล้วและไฟล์รันไทม์จำเป็น (เช่น: CA certs, เทมเพลต, หรือ static assets) และคุณ deploy แบบเดิมทุกครั้ง
config ควรเป็นภายนอก ไม่ใช่ฝังในไบนารี ใช้ environment variables สำหรับการตั้งค่าส่วนใหญ่ (ports, DB host, feature flags) ใช้ไฟล์ config เมื่อต้องการค่าที่ยาวหรือมีโครงสร้าง และเก็บแยกตาม environment หากใช้ config service ปฏิบัติต่อมันเป็น dependency: สิทธิ์ล็อก, audit logs, และแผน fallback ชัดเจน
ความลับคือเส้นที่ห้ามข้าม อย่าเก็บใน repo, image, หรือ logs หลีกเลี่ยงการพิมพ์ connection strings ตอน startup เก็บ secrets ใน secret store ของ CI และฉีดตอน deploy
เพื่อให้ artifact ติดตามได้ ฝังตัวตนในทุก build: tag artifact ด้วยเวอร์ชันบวก commit hash, ใส่ metadata (version, commit, build time) ใน info endpoint, และบันทึก tag ของ artifact ใน log การ deploy ทำให้ง่ายต่อการตอบว่า "ตอนนี้รันอะไรอยู่" ด้วยคำสั่งเดียวหรือแดชบอร์ด
ถ้าคุณ generate backend Go (เช่นกับ AppMaster) วินัยนี้ยิ่งสำคัญ: regeneration ปลอดภัยเมื่อการตั้งชื่อ artifact และกฎ config ทำให้การปล่อยทุกครั้งทำซ้ำได้ง่าย
ความล้มเหลวส่วนใหญ่ในการ deploy ไม่ใช่ "โค้ดไม่ดี" แต่เป็น environment ที่ไม่ตรงกัน: config ต่าง, secrets หาย, หรือ service ที่สตาร์ทได้แต่ยังไม่พร้อม เป้าหมายคือ: deploy artifact เดียวกันทุกที่ และเปลี่ยนแค่คอนฟิก
บน Kubernetes ตั้งใจทำ controlled rollout ใช้ rolling updates เพื่อเปลี่ยน pods ทีละส่วน และเพิ่ม readiness/liveness checks เพื่อให้แพลตฟอร์มรู้เมื่อส่งทราฟฟิกและเมื่อ restart container ที่ค้าง resource requests และ limits ก็สำคัญ เพราะ service Go ที่ทำงานบน runner ใหญ่ใน CI อาจถูก OOM-kill บน node เล็ก
เก็บ config และ secrets ให้ออกจาก image สร้าง image ต่อ commit แล้วฉีดการตั้งค่าเฉพาะ environment ตอน deploy (ConfigMaps, Secrets, หรือ secret manager ของคุณ) ด้วยวิธีนี้ staging และ production รันบิตเดียวกัน
ถ้า deploy ไป VM, systemd สามารถเป็น “mini orchestrator” ของคุณ สร้าง unit file ที่มี working directory ชัดเจน, ไฟล์ environment, และนโยบาย restart ทำให้ logs คาดเดาได้โดยส่ง stdout/stderr ไปที่ log collector หรือ journald เพื่อไม่ให้เหตุการณ์ลงท้ายด้วยการต้อง SSH หาคน
คุณยังทำ safe rollout ได้โดยไม่ต้องใช้ cluster เช่น blue/green เรียบง่าย: เก็บสองไดเรกทอรี (หรือสอง VM), สลับ load balancer, และเก็บเวอร์ชันก่อนหน้าไว้พร้อมสำหรับ rollback ด่วน Canary ก็คล้ายกัน: ส่งส่วนน้อยของทราฟฟิกไปที่เวอร์ชันใหม่ก่อนยืนยัน
ก่อนจะมาร์ค deploy ว่า “เสร็จ” ให้รัน smoke check เดียวกันในทุกที่:
หากคุณ regenerate backends (เช่น backend Go จาก AppMaster) วิธีนี้ยังคงเสถียร: build ครั้งเดียว, deploy artifact, และให้การตั้งค่า environment ขับเคลื่อนความแตกต่าง ไม่ใช่สคริปต์ ad-hoc
การปล่อยที่พังส่วนใหญ่ไม่ใช่เพราะ "โค้ดไม่ดี" แต่เกิดเมื่อ pipeline ทำงานต่างกันในแต่ละครั้ง หากคุณอยากให้ CI/CD สำหรับ backend Go รู้สึกสงบและคาดเดาได้ ให้จับตารูปแบบเหล่านี้
การรัน database migrations อัตโนมัติบนทุก deploy โดยไม่มี guardrails เป็นเรื่องคลาสสิก Migration ที่ล็อกตารางอาจทำให้บริการที่มีโหลดสูงหยุดทำงาน ตั้ง migrations ไว้ข้างหลังขั้นตอนชัดเจน, ขออนุมัติสำหรับ production, และมั่นใจว่าสามารถรันซ้ำได้อย่างปลอดภัย
การใช้ tag แบบ latest หรือ base images ที่ไม่ล็อกเป็นอีกวิธีสร้างความลึกลับให้เกิดข้อผิดพลาด ให้ pin Docker images และเวอร์ชัน Go เพื่อไม่ให้สภาพแวดล้อม build drift
การแชร์ฐานข้อมูลเดียวกันข้าม environment “ชั่วคราว” มักกลายเป็นถาวร และเป็นสาเหตุให้ข้อมูลทดสอบรั่วสู่ staging และสคริปต์ staging กระทบทดสอบ production แยกฐานข้อมูลและ credentials ต่อ environment แม้ schema จะเหมือนกัน
ขาด health checks และ readiness checks ทำให้ deploy “สำเร็จ” แต่ service ยังพัง และทราฟฟิกถูกส่งไปก่อนเวลา ให้เพิ่ม checks ที่สะท้อนพฤติกรรมจริง: app สตาร์ทได้ เชื่อม DB ได้ และให้บริการคำขอได้
สุดท้าย ความเป็นเจ้าของที่ไม่ชัดเจนสำหรับ secrets, config, และการเข้าถึง ทำให้การปล่อยกลายเป็นการเดา ใครสักคนต้องรับผิดชอบในการสร้าง, หมุน, และฉีด secrets
ความล้มเหลวที่สมจริง: ทีม merge การเปลี่ยนแปลง pipeline deploy และ migration อัตโนมัติรันก่อน มันเสร็จใน staging (ข้อมูลน้อย) แต่ timeout ใน production (ข้อมูลมาก) หากมีการ pin image, แยก environment, และมี gated migration การ deploy จะหยุดอย่างปลอดภัย
หากคุณ generate Go backends (เช่นกับ AppMaster) กฎเหล่านี้ยิ่งสำคัญเพราะการ regenerate อาจกระทบหลายไฟล์ อินพุตที่คาดเดาได้และเกตที่ชัดเจนช่วยให้การเปลี่ยนแปลงครั้งใหญ่ไม่กลายเป็น release ที่เสี่ยง
ใช้เป็นจุดตรวจสัญชาตญาณสำหรับ CI/CD ของ backend Go ถ้าคุณตอบแต่ละข้อได้ว่า “ใช่” การปล่อยจะง่ายขึ้น
จำกัดการเข้าถึง production และทำให้อ่านย้อนหลังได้ CI ควร deploy โดยบัญชีเซอร์วิสเฉพาะ, secrets จัดการศูนย์กลาง, และการกระทำแมนนวลใน production ควรทิ้งร่องรอยชัดเจน (ใคร, ทำอะไร, เมื่อไร)
ทีมปฏิบัติการเล็ก ๆ สี่คนปล่อยสัปดาห์ละครั้ง พวกเขามัก regenerate backend Go เพราะทีมผลิตภัณฑ์ปรับ workflow บ่อย เป้าหมายคือ: คืนที่นอนน้อยลงและการปล่อยที่ไม่เซอร์ไพรส์ใคร
การเปลี่ยนปกติวันศุกร์: เพิ่มฟิลด์ใหม่ให้ customers (schema change) และอัปเดต API ที่เขียนมัน (code change) pipeline จะถือเป็น release เดียว มัน build artifact เดียว รัน tests กับ artifact นั้นเป๊ะ และจากนั้นจึง apply migrations และ deploy แบบนั้นฐานข้อมูลจะไม่อยู่หน้ากว่าโค้ดที่คาดหวัง และโค้ดจะไม่ถูก deploy โดยไม่มี schema ที่ตรงกัน
เมื่อมี schema change pipeline จะเพิ่ม safety gate ตรวจว่า migration เป็นแบบ additive (เช่นเพิ่มคอลัมน์ nullable) และทำเครื่องหมายการกระทำที่เสี่ยง (เช่น drop column หรือ rewrite ตารางใหญ่) หาก migration เสี่ยง การปล่อยจะหยุดก่อน production ทีมจะเขียน migration ให้ปลอดภัยขึ้นหรือกำหนดเวลากลางเพื่อทำ
หากการทดสอบล้ม ไม่มีอะไรเดินหน้า เช่นเดียวกันหาก migrations ล้มใน pre-production pipeline ไม่ควรพยายามผลักการเปลี่ยนแปลงผ่าน “ครั้งนี้ครั้งเดียว”
ชุดขั้นตอนถัดไปที่เรียบง่ายและใช้ได้กับทีมส่วนใหญ่:
ถ้าคุณ generate backend ด้วย AppMaster ให้เก็บการ regenerate ไว้ในขั้นตอน pipeline เดิม: regenerate, build, test, migrate ใน environment ปลอดภัย แล้วค่อย deploy ปฏิบัติต่อซอร์สที่ generate เหมือนซอร์สอื่น ๆ ทุก release ควรทำซ้ำได้จากเวอร์ชันที่ติด tag ด้วยขั้นตอนเดียวกันทุกครั้ง.
ล็อกเวอร์ชันของ Go และสภาพแวดล้อมการ build ให้แน่น เพื่อให้อินพุตเดิมให้ผลลัพธ์เดิมเสมอ ไม่ว่าจะ build ที่ไหน วิธีนี้จะตัดปัญหา “works on my machine” และทำให้การแก้บั๊กทำได้ง่ายขึ้น.
การ regenerate อาจเปลี่ยน endpoints, แบบข้อมูลในฐานข้อมูล และ dependency แม้ไม่มีการแก้โค้ดด้วยมือ pipeline จะทำให้การเปลี่ยนแปลงเหล่านั้นต้องผ่านการตรวจเหมือนกันทุกครั้ง ดังนั้นการ regenerate จะปลอดภัย ไม่ใช่เสี่ยง.
Build ครั้งเดียวแล้ว promote artifact เดียวกันผ่าน dev, staging, และ prod หากคุณ rebuild แยกแต่ละ environment อาจเผลอส่งสิ่งที่คุณไม่ได้ทดสอบจริง แม้จะมาจาก commit เดียวกัน.
รันเกตที่เร็วบนทุก PR: การจัดรูปแบบ, การตรวจแบบ static พื้นฐาน, build, และ unit tests ที่มี timeout ตั้งค่าให้เร็วพอที่คนจะไม่ข้ามมัน และเข้มงวดพอที่การเปลี่ยนแปลงผิดพลาดจะหยุดตั้งแต่ต้น.
มี integration stage เล็ก ๆ ที่บูต service ด้วย config ที่ใกล้เคียง production และเชื่อมต่อกับ dependency จริงเช่น PostgreSQL เป้าหมายคือจับปัญหา "compile ผ่านแต่ไม่สามารถเริ่มได้" หรือผิดสัญญาของ API โดยไม่ทำให้ CI ช้าเป็นชั่วโมง.
ปฏิบัติต่อ migrations เป็นขั้นตอน release ที่ควบคุมได้ อย่าให้รันโดยอัตโนมัติทุกครั้งที่ deploy รันแบบมีล็อกหนึ่งครั้งและบันทึกอย่างชัดเจน ยอมรับความจริงเรื่อง rollback: การเปลี่ยนแปลงหลายอย่างใน schema ไม่สามารถย้อนกลับได้ง่าย.
เพิ่ม readiness checks เพื่อให้ traffic เข้าถึง pods ใหม่ก็ต่อเมื่อ service พร้อมจริง และ liveness checks เพื่อ restart container ที่ค้างได้ นอกจากนี้ตั้ง resource requests/limits ให้สมจริงเพื่อไม่ให้ service ถูก OOM-kill ใน production.
unit systemd ที่ชัดเจนพร้อม working directory, ไฟล์ environment และนโยบาย restart มักเพียงพอสำหรับการ deploy บน VM เก็บ artifact แบบเดียวกับ containers เมื่อต้องการ และเพิ่ม smoke check หลัง deploy เล็ก ๆ เพื่อตรวจสอบว่า restart ที่ดู "สำเร็จ" ไม่ได้ซ่อนปัญหา.
อย่าใส่ความลับลงใน repo, image หรือ logs ฉีด secrets ตอน deploy จาก secret store ที่จัดการได้ จำกัดผู้ที่อ่านได้ และทำให้การหมุนเวียนเป็นกระบวนการปกติ ไม่ใช่วิกฤตเมื่อเกิดเหตุ.
เอาการ regenerate เข้าไปใน pipeline ตามขั้นตอนปกติ: regenerate, build, test, package แล้วค่อย migrate และ deploy พร้อม gates หากคุณใช้ AppMaster เพื่อ generate backend Go วิธีนี้ช่วยให้คุณเร่งได้โดยไม่เดาได้ว่ามีอะไรเปลี่ยน.



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


