แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
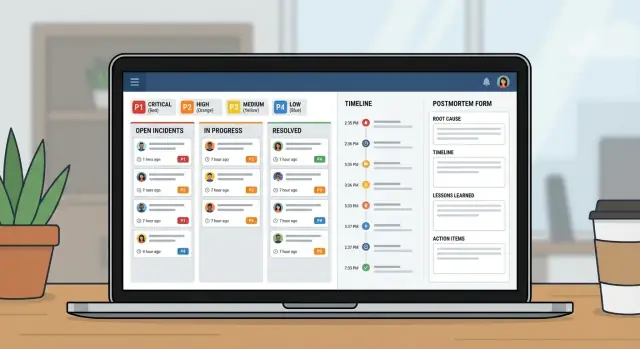
วางแผนและสร้างแอปจัดการเหตุการณ์สำหรับทีมไอทีด้วยเวิร์กโฟลว์ความรุนแรง เจ้าของชัดเจน ไทม์ไลน์ และรายงานหลังเหตุการณ์ในเครื่องมือภายในเดียว
เมื่อเกิดการล่ม ทีมมักหยิบสิ่งที่เปิดอยู่: ดิสคัสชันในแชท, อีเมล, หรือสเปรดชีตที่ใครสักคนอัปเดตเมื่อมีเวลาว่าง ภายใต้ความกดดัน การจัดการแบบนี้จะพังด้วยเหตุผลเดิม ๆ เสมอ: เจ้าของไม่ชัดเจน ประทับเวลาหายไป และการตัดสินใจจมอยู่ในสกรอลล์
แอปจัดการเหตุการณ์อย่างง่ายจะแก้พื้นฐานได้ มันให้ที่เดียวที่เหตุการณ์อยู่อย่างเป็นระเบียน พร้อมเจ้าของชัดเจน ระดับความรุนแรงที่ทุกคนเห็นตรงกัน และไทม์ไลน์ของสิ่งที่เกิดขึ้นและเวลา บันทึกเดียวนี้สำคัญเพราะคำถามเดิม ๆ จะถูกยกขึ้นในทุกเหตุการณ์: ใครเป็นผู้นำ? เริ่มเมื่อไหร่? สถานะปัจจุบันคืออะไร? อะไรที่ลองไปแล้ว?
ถ้าไม่มีบันทึกร่วม การส่งมอบงานจะเสียเวลา ฝ่ายซัพพอร์ตบอกลูกค้าอย่างหนึ่ง ในขณะที่วิศวกรรมกำลังทำอีกอย่าง ผู้จัดการขออัปเดตซึ่งดึงผู้ตอบเหตุการณ์ออกจากการแก้ไข หลังเหตุการณ์ ไม่มีใครสร้างไทม์ไลน์ได้อย่างมั่นใจ รายงานหลังเหตุการณ์ก็กลายเป็นการคาดเดา
เป้าหมายไม่ใช่การแทนที่การมอนิเตอร์ แชท หรือระบบตั๋ว เตือนภัยยังคงเริ่มจากที่อื่นได้ จุดประสงค์คือจับร่องรอยการตัดสินใจและทำให้คนอยู่ในแนวเดียวกัน
งานปฏิบัติการไอทีและวิศวกร on-call ใช้เพื่อประสานการตอบสนอง ฝ่ายซัพพอร์ตใช้เพื่อให้การอัปเดตที่ถูกต้องอย่างรวดเร็ว ผู้จัดการใช้เพื่อดูความคืบหน้าโดยไม่รบกวนผู้ตอบเหตุการณ์
เวลา 9:12 น. ระบบมอนิเตอร์เตือนการพุ่งของข้อผิดพลาด 500 บนพอร์ทัลลูกค้า เจ้าหน้าที่ซัพพอร์ตก็รายงานว่า “ล็อกอินล้มเหลวสำหรับผู้ใช้ส่วนใหญ่” หัวหน้าไอทีที่ on-call เปิดเหตุการณ์ P1 ในแอปและแนบการเตือนครั้งแรกพร้อมสกรีนช็อตจากซัพพอร์ต
กับ P1 พฤติกรรมต้องเปลี่ยนเร็ว เจ้าของเหตุการณ์ดึงเจ้าของแบ็กเอนด์ เจ้าของฐานข้อมูล และผู้ประสานงานซัพพอร์ตเข้ามา งานที่ไม่จำเป็นหยุด ชุดดีพลอยที่วางแผนไว้หยุด ทีมตกลงความถี่การอัปเดต (เช่น ทุก 15 นาที) เริ่มการประชุมร่วม แต่บันทึกเหตุการณ์ยังคงเป็นแหล่งข้อมูลที่เชื่อถือได้
เวลา 9:18 น. มีคนถามว่า “มีอะไรเปลี่ยนแปลง?” ไทม์ไลน์แสดงการดีพลอยตอน 8:57 น. แต่ไม่ได้บอกว่าอะไรถูกดีพลอย เจ้าของแบ็กเอนด์จึงม้วนกลับ (rollback) ข้อผิดพลาดลดลง แล้วกลับมาอีก คราวนี้ทีมสงสัยฐานข้อมูล
ความล่าช้าที่พบได้บ่อยปรากฏในไม่กี่จุดที่คาดไว้: การส่งมอบงานไม่ชัดเจน (“ฉันคิดว่าเธอกำลังเช็กอยู่นะ”), ขาดบริบท (การเปลี่ยนแปลงล่าสุด ความเสี่ยงที่รู้แล้ว เจ้าของปัจจุบัน), และการอัปเดตกระจัดกระจายในแชท ตั๋ว และอีเมล
เวลา 9:41 น. เจ้าของฐานข้อมูลพบคิวที่วิ่งล้นซึ่งเริ่มโดยงานตามตาราง พวกเขาปิดงานนั้น รีสตาร์ทบริการที่ได้รับผลกระทบ และยืนยันการกู้คืน ความรุนแรงลดเป็น P2 เพื่อเฝ้าดู
การปิดเหตุการณ์ที่ดีไม่ใช่แค่ “มันใช้ได้อีกครั้ง” แต่เป็นบันทึกที่สะอาด: ไทม์ไลน์แบบนาทีต่อ นาที สาเหตุสุดท้าย ใครตัดสินใจอะไร อะไรถูกหยุด และงานติดตามพร้อมเจ้าของและวันที่ครบกำหนด นั่นคือวิธีที่ P1 ที่เครียดกลายเป็นบทเรียนแทนที่จะเป็นความเจ็บปวดซ้ำ ๆ
เครื่องมือเหตุการณ์ที่ดีส่วนใหญ่คือโมเดลข้อมูลที่ดี ถ้าบันทึกคลุมเครือ คนจะถกเถียงว่าเหตุการณ์คืออะไร เริ่มเมื่อไหร่ และอะไรยังเปิดอยู่
เก็บเอนทิตีหลักให้ใกล้กับภาษาที่ทีมไอทีใช้กันอยู่แล้ว:
เพื่อป้องกันความสับสนภายหลัง ให้ Incident มีฟิลด์ที่มีโครงสร้างไม่กี่อย่างที่ต้องกรอกเสมอ ข้อความอิสระช่วยได้ แต่ไม่ควรเป็นแหล่งความจริงเพียงอย่างเดียว ข้อขั้นต่ำที่ปฏิบัติได้คือ: ชื่อชัดเจน ผลกระทบ (ผู้ใช้ประสบอะไร) บริการที่ได้รับผล เวลาเริ่ม สถานะปัจจุบัน และความรุนแรง
ความสัมพันธ์สำคัญมากกว่าฟิลด์เสริม หนึ่งเหตุการณ์ควรมีหลายอัปเดตและหลายงาน พร้อมลิงก์หลายต่อหลายไปยังบริการ (เพราะการล่มมักกระทบหลายระบบ) รายงานหลังเหตุการณ์ควรเป็นหนึ่งต่อหนึ่งกับเหตุการณ์ เพื่อให้มีเรื่องราวสุดท้ายเพียงหนึ่งเดียว
ตัวอย่าง: เหตุการณ์ “ข้อผิดพลาดที่หน้าชำระเงิน” ลิงก์ไปยัง Services “Payments API” และ “PostgreSQL,” มีการอัปเดตทุก 15 นาที และงานเช่น “ม้วนกลับดีพลอย” และ “เพิ่มเกราะป้องกันการ retry” ต่อมา postmortem บันทึกสาเหตุรากและสร้างงานระยะยาว
เมื่อคนเครียด พวกเขาต้องการป้ายง่าย ๆ ที่มีความหมายเหมือนกันสำหรับทุกคน กำหนด P1 ถึง P4 เป็นภาษาธรรมดาและแสดงคำนิยามข้างฟิลด์ความรุนแรง
เป้าหมายการตอบสนองควรอ่านเหมือนคำมั่นสัญญา ตัวอย่างฐานที่เรียบง่าย (ปรับให้เหมาะกับความเป็นจริงของคุณ):
| ความรุนแรง | การตอบสนองครั้งแรก (ack) | การอัปเดตครั้งแรก | ความถี่การอัปเดต |
|---|---|---|---|
| P1 | 5 min | 15 min | every 30 min |
| P2 | 15 min | 30 min | every 60 min |
| P3 | 4 hours | 1 business day | daily |
| P4 | 2 business days | 1 week | weekly |
เก็บกฎการยกระดับให้เป็นเชิงกลไก ถ้า P2 พลาดความถี่การอัปเดต ระบบควรเตือนรีวิวความรุนแรง เพื่อหลีกเลี่ยงการแกว่ง จำกัดคนที่สามารถเปลี่ยนความรุนแรง (มักเป็นเจ้าของเหตุการณ์หรือ incident commander) แต่ยังอนุญาตให้ใครก็ตามขอรีวิวได้ในคอมเมนต์
เมตริกซ์ผลกระทบสั้น ๆ ช่วยให้ทีมเลือกความรุนแรงได้เร็ว บันทึกเป็นฟิลด์บังคับไม่กี่อย่าง: ผู้ใช้ที่ได้รับผล, ความเสี่ยงต่อรายได้, ความปลอดภัย/การปฏิบัติตาม, และว่าแถบทางแก้มีหรือไม่
ระหว่างเหตุการณ์ คนไม่ต้องการตัวเลือกมากขึ้น พวกเขาต้องการชุดสถานะสั้น ๆ ที่ชัดเจนว่าขั้นตอนถัดไปคืออะไร
เริ่มจากขั้นตอนที่คุณทำในวันที่ปกติดี แล้วเก็บรายการให้สั้น ถ้ามีมากกว่า 6–7 สถานะ ทีมจะถกเถียงเรื่องคำศัพท์แทนที่จะแก้ปัญหา
ชุดที่ใช้งานได้จริง:
แต่ละสถานะต้องมีเกณฑ์เข้าออกชัดเจน ตัวอย่าง:
ใช้การเปลี่ยนสถานะเพื่อบังคับฟิลด์ที่คนมักลืม กฎทั่วไป: ไม่สามารถปิดเหตุการณ์ได้หากไม่มีสรุปสาเหตุสั้น ๆ และงานติดตามอย่างน้อยหนึ่งงาน ถ้าอนุญาตให้ “RCA: TBD” มันมักจะยังคงเป็นแบบนั้น
หน้าของเหตุการณ์ควรตอบสามคำถามในที่เดียว: ใครเป็นเจ้าของ, การกระทำถัดไปคืออะไร, และอัปเดตล่าสุดเมื่อไหร่
เมื่อเหตุการณ์วุ่นวาย วิธีที่เร็วที่สุดในการเสียเวลาคือความเป็นเจ้าของที่ไม่ชัดเจน แอปของคุณควรทำให้คนคนเดียวรับผิดชอบอย่างชัดเจน ขณะเดียวกันก็ทำให้ง่ายสำหรับคนอื่นที่จะช่วย
รูปแบบง่าย ๆ ที่ใช้งานได้:
การมอบหมายควรชัดเจนและตรวจสอบได้ ติดตามว่าใครตั้งเจ้าของ ใครยอมรับ และการเปลี่ยนแปลงทุกครั้งหลังจากนั้น การ “ยอมรับ” สำคัญ เพราะการมอบหมายให้คนที่หลับหรือออฟไลน์ไม่ใช่เจ้าของจริง
การมอบหมายตาม on-call vs ทีมมักขึ้นกับความรุนแรง สำหรับ P1/P2 ให้ใช้รอบ on-call เป็นค่าเริ่มต้นเพื่อให้มีเจ้าของชื่อชัดเจนเสมอ สำหรับความรุนแรงต่ำกว่า การมอบหมายแบบทีมอาจใช้ได้ แต่ยังต้องการเจ้าของหลักภายในช่วงเวลาสั้น ๆ
วางแผนสำหรับวันลาหรือการขาดงานในกระบวนการมนุษย์ของคุณ ไม่ใช่แค่ในระบบ ถ้าคนที่มอบหมายถูกตั้งเป็นไม่ว่าง ให้ส่งต่อไปยัง on-call สำรองหรือหัวหน้าทีม ทำให้อัตโนมัติแต่เห็นได้ชัดเจนเพื่อแก้ไขได้เร็ว
การยกระดับควรทริกเกอร์ทั้งจากความรุนแรงและความเงียบ ตัวอย่างเริ่มต้นที่มีประโยชน์:
ไทม์ไลน์ที่ดีคือความทรงจำร่วม ระหว่างเหตุการณ์ บริบทหายไปเร็ว ถ้าคุณจับช่วงเวลาที่ถูกต้องไว้ในที่เดียว การส่งมอบงานจะง่ายขึ้นและ postmortem ก็แทบจะเขียนเสร็จก่อนใครจะเปิดเอกสาร
ทำให้ไทม์ไลน์มีความเห็นพ้อง อย่าเปลี่ยนมันเป็นบันทึกแชท ทีมส่วนใหญ่พึ่งพารายการสั้น ๆ: การตรวจจับ การรับทราบ ขั้นตอนบรรเทาสำคัญ การกู้คืน และการปิด
แต่ละรายการต้องมีประทับเวลา ผู้เขียน และคำอธิบายสั้น ๆ เป็นภาษาธรรมดา คนที่เข้ามาทีหลังควรอ่านห้ารายการแล้วเข้าใจสถานการณ์ได้
การอัปเดตต่างชนิดใช้กับผู้ชมต่างกัน จะช่วยได้เมื่อระบุประเภท เช่น internal note (รายละเอียดดิบ), customer-facing update (คำพูดปลอดภัย), decision (ทำไมเลือกตัวเลือก A), และ handoff (สิ่งที่คนถัดไปต้องรู้)
เตือนควรตามความรุนแรง ไม่ใช่ความชอบส่วนตัว ถ้าเวลาถึงให้เตือนเจ้าของปัจจุบันก่อน แล้วค่อยยกระดับถ้าพลาดซ้ำ ๆ
การแจ้งเตือนควรเป็นเป้าหมายและคาดเดาได้ กฎเล็ก ๆ มักพอเพียง: แจ้งเมื่อสร้าง, เปลี่ยนความรุนแรง, กู้คืน, และอัปเดตเกินเวลา หลีกเลี่ยงการแจ้งทั้งบริษัทสำหรับทุกการเปลี่ยนแปลง
postmortem ควรทำงานสองอย่าง: อธิบายเหตุการณ์เป็นภาษาที่เข้าใจได้ และทำให้ความล้มเหลวนั้นเกิดขึ้นอีกได้ยากขึ้น
เก็บรายงานให้สั้น และบังคับให้เปลี่ยนเป็นงาน ปรับโครงสร้างปฏิบัติได้เช่น: สรุป, ผลกระทบต่อลูกค้า, สาเหตุราก, การแก้ชั่วคราวที่ใช้, และงานติดตาม
งานติดตามเป็นหัวใจของเรื่อง อย่าทิ้งไว้เป็นย่อหน้าสุดท้าย เปลี่ยนแต่ละงานติดตามเป็นงานที่ติดตามได้พร้อมเจ้าของและวันที่ครบกำหนด แม้วันที่จะเป็น “สปรินต์ถัดไป” นั่นคือความแตกต่างระหว่าง “เราควรปรับการมอนิเตอร์” กับ “Alex เพิ่มการเตือนการอิ่มตัวการเชื่อมต่อ DB ภายในวันศุกร์”
แท็กทำให้ postmortem มีประโยชน์ในภายหลัง ใส่ธีม 1–3 อย่างในแต่ละเหตุการณ์ (ช่องว่างมอนิเตอร์, การปล่อย, ความจุ, กระบวนการ) หลังหนึ่งเดือน คุณจะตอบคำถามพื้นฐานได้ว่า P1 ส่วนใหญ่เกิดจากการปล่อยหรือการเตือนที่ขาดหาย
หลักฐานควรแนบได้ง่ายแต่ไม่บังคับ สนับสนุนฟิลด์ตัวเลือกสำหรับสกรีนช็อต, ชิ้นส่วนล็อก, และการอ้างอิงถึงระบบภายนอก (หมายเลขตั๋ว, เธรดแชท, เคสผู้ขาย) ทำให้เบาเพื่อให้คนยอมกรอกจริง
มองว่ามันเป็นผลิตภัณฑ์เล็ก ๆ ไม่ใช่สเปรดชีตที่ใส่คอลัมน์เพิ่ม แอปเหตุการณ์ที่ดีคือสามมุมมอง: สิ่งที่เกิดขึ้นตอนนี้, สิ่งที่ต้องทำถัดไป, และสิ่งที่จะเรียนรู้หลังจากนั้น
เริ่มจากร่างหน้าจอที่คนจะเปิดในความกดดัน:
สร้างโมเดลข้อมูลและสิทธิ์พร้อมกัน ถ้าทุกคนแก้ได้หมด ประวัติจะยุ่งเหยิง แนวทางทั่วไป: มุมมองกว้างสำหรับไอที, การเปลี่ยนสถานะ/ความรุนแรงควบคุมได้, ผู้ตอบสามารถเพิ่มอัปเดต, และเจ้าของชัดเจนสำหรับการอนุมัติ postmortem
แล้วเพิ่มกฎเวิร์กโฟลว์ที่กันเหตุการณ์ครึ่ง ๆ ครึ่ง ๆ ฟิลด์ที่บังคับควรขึ้นกับสถานะ อาจอนุญาต “New” เฉพาะชื่อและผู้รายงาน แต่บังคับให้ “Mitigating” มีสรุปผลกระทบ และบังคับให้ “Resolved” มีสรุปสาเหตุและอย่างน้อยงานติดตามหนึ่งงาน
สุดท้าย ทดสอบโดยเล่นซ้ำ 2–3 เหตุการณ์ในอดีต ให้คนหนึ่งเป็น incident commander และคนหนึ่งเป็นผู้ตอบ คุณจะเห็นเร็วว่าคำสถานะไหนไม่ชัด ฟิลด์ไหนคนมักข้าม และที่ไหนต้องมีค่าเริ่มต้นที่ดีกว่า
ระบบเหตุการณ์ส่วนใหญ่ล้มเหลวด้วยเหตุผลเรียบง่าย: คนจำกฎไม่ได้เมื่อเครียด และแอปไม่จับข้อเท็จจริงที่คุณต้องใช้ภายหลัง
ถ้ามีระดับความรุนแรงหกระดับและสถานะสิบสถานะ คนจะเดา เก็บความรุนแรง 3–4 ระดับและสถานะให้มุ่งไปที่สิ่งที่ใครสักคนควรทำต่อไป
เมื่อทุกคน “กำลังดู” ไม่มีใครขับเคลื่อน สั่งให้มีเจ้าของคนเดียวก่อนเหตุการณ์จะเดินหน้าต่อ และทำให้การส่งมอบงานชัดเจน
ถ้า "เกิดอะไรขึ้นเมื่อไหร่" พึ่งประวัติแชท รายงานหลังเหตุการณ์จะกลายเป็นการถกเถียง จับเวลาเปิด รับทราบ บรรเทา และปิดอัตโนมัติ และเก็บรายการไทม์ไลน์สั้น ๆ
นอกจากนี้ หลีกเลี่ยงการปิดด้วยบันทึกสาเหตุคลุมเครือเช่น “ปัญหาเครือข่าย” บังคับให้มีสรุปสาเหตุชัดเจนและอย่างน้อยหนึ่งขั้นตอนถัดไปที่จับต้องได้
ก่อนเปิดให้ทั้งองค์กรไอที ทดสอบพื้นฐานภายใต้ความกดดัน ถ้าคนหาเมนูไม่เจอในสองนาทีแรก พวกเขาจะกลับไปใช้แชทและสเปรดชีต
มุ่งที่เช็คลิสต์เปิดตัวสั้น ๆ: บทบาทและสิทธิ์, คำนิยามความรุนแรงชัดเจน, การบังคับเจ้าของ, กฎเตือนความจำ, และเส้นทางการยกระดับเมื่อพลาดเป้าหมายการตอบสนอง
นำร่องกับทีมหนึ่งและบริการไม่กี่ตัวที่สร้างการเตือนบ่อย ใช้สองสัปดาห์ แล้วปรับตามเหตุการณ์จริง
ถ้าคุณต้องการสร้างสิ่งนี้เป็นเครื่องมือภายในเดียวโดยไม่ต้องเย็บหลายระบบเข้าด้วยกัน AppMaster (appmaster.io) เป็นตัวเลือกหนึ่ง มันให้คุณสร้างโมเดลข้อมูล กฎเวิร์กโฟลว์ และอินเตอร์เฟซเว็บ/มือถือในที่เดียว ซึ่งเหมาะกับคิวเหตุการณ์ หน้าเหตุการณ์ และการติดตาม postmortem
มันแทนที่การอัปเดตกระจัดกระจายด้วยบันทึกเดียวที่ทุกคนเข้าถึงได้ ซึ่งตอบคำถามพื้นฐานอย่างรวดเร็ว: ใครเป็นผู้รับผิดชอบ, ผู้ใช้เห็นอะไร, อะไรถูกลองแล้ว, และขั้นตอนถัดไปคืออะไร การมีบันทึกร่วมลดเวลาที่เสียไปกับการส่งต่อ ข้อความขัดแย้ง และคำขอ "สรุปให้หน่อย" ที่ดึงตัวตอบเหตุการณ์ออกจากงานแก้ปัญหา
เปิดเหตุการณ์ทันทีเมื่อคุณเชื่อว่ามีผลกระทบต่อผู้ใช้หรือธุรกิจจริง แม้ว่าสาเหตุจะยังไม่ชัดเจน คุณสามารถเปิดด้วยชื่อลงร่างและระบุว่า “ผลกระทบไม่ทราบ” แล้วค่อยปรับรายละเอียดเมื่อยืนยันความรุนแรงและขอบเขตได้
เก็บให้เล็กและมีโครงสร้าง: ชื่อชัดเจน, สรุปผลกระทบ, บริการที่ได้รับผล, เวลาที่เริ่ม, สถานะปัจจุบัน, ความรุนแรง และเจ้าของคนเดียว เพิ่มอัปเดตและงานตามสถานการณ์ แต่อย่าใช้ข้อความอิสระเป็นแหล่งความจริงเพียงแหล่งเดียว
ใช้ 3–4 ระดับที่มีความหมายชัดเจนและไม่ต้องถกเถียง ค่าตั้งต้นที่ดีคือ P1 สำหรับการล่มของบริการหลักหรือความเสี่ยงข้อมูลสูญหาย, P2 สำหรับฟีเจอร์สำคัญที่มีวิธีแก้ชั่วคราวหรือผลกระทบน้อยลง, P3 สำหรับปัญหาที่ผลกระทบน้อยกว่า, และ P4 สำหรับปัญหาเล็กน้อยหรือความงาม
ตั้งเป้าให้เป็นพันธสัญญาไม่ใช่การเดา: เวลาตอบรับ, เวลาอัปเดตครั้งแรก, และความถี่การอัปเดต แล้วตั้งเตือนและการยกระดับเมื่อความถี่นั้นถูกละเลย เพราะ “ความเงียบ” มักเป็นความล้มเหลวสำคัญในเหตุการณ์
ประมาณหกสถานะ: New, Acknowledged, Investigating, Mitigating, Monitoring, Resolved แต่ละสถานะต้องชัดเจนว่าอะไรควรเป็นขั้นตอนถัดไป และการเปลี่ยนสถานะควรกำหนดฟิลด์ที่มักถูกลืม เช่น ต้องมีเจ้าของก่อนไป Acknowledged หรือสรุปสาเหตุก่อนปิด
บังคับให้มีเจ้าของหลักคนเดียวที่รับผิดชอบขับเคลื่อนการตอบสนองและโพสต์อัปเดต ติดตามการยอมรับเพื่อหลีกเลี่ยงการมอบหมายให้คนที่ออฟไลน์ และทำให้การส่งมอบงานเป็นเหตุการณ์ที่บันทึกได้ เพื่อให้คนถัดไปไม่ต้องเริ่มสืบสวนใหม่หมด
บันทึกเฉพาะช่วงเวลาที่สำคัญ: การตรวจจับ, การรับทราบ, การตัดสินใจสำคัญ, ขั้นตอนบรรเทา, การกู้คืน, และการปิด แต่ละรายการต้องมีประทับเวลาและผู้เขียน เพื่อให้คนที่เข้ามาทีหลังอ่านห้ารายการแล้วเข้าใจสถานะได้
สั้นและมุ่งไปที่การปฏิบัติ: เกิดอะไรขึ้น, ผลกระทบต่อผู้ใช้, สาเหตุสุดท้าย, สิ่งที่เปลี่ยนระหว่างการบรรเทา, และรายการติดตามที่มีเจ้าของและวันที่ครบกำหนด งานติดตามเป็นสิ่งสำคัญ — เปลี่ยนให้เป็นงานที่ติดตามได้แทนที่จะปล่อยไว้เป็นย่อหน้าปลายเอกสาร
ได้ ถ้าคุณออกแบบ incidents, updates, tasks, services และ postmortems เป็นข้อมูลจริงและบังคับใช้กฎเวิร์กโฟลว์ในแอป ตัวอย่างเช่น AppMaster (appmaster.io) ช่วยให้ทีมสร้างโมเดลข้อมูล หน้าจอเว็บ/มือถือ และการตรวจสอบสถานะในที่เดียว ทำให้กระบวนการไม่ถอยกลับไปใช้สเปรดชีตภายใต้ความกดดัน



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


