Aplikasi pemesanan peralatan: cegah konflik dan lacak pengembalian
Rencanakan aplikasi pemesanan peralatan yang mencegah pemesanan ganda, mencatat pengembalian dan kerusakan, serta menahan item bermasalah untuk pemeliharaan.
Pelajari pola praktis untuk tugas latar belakang dengan pembaruan progres: antrean, model status, pesan UI, aksi batal/ulang, dan pelaporan error.
Aksi yang lama tidak boleh memblokir UI. Orang pindah tab, kehilangan koneksi, menutup laptop, atau bertanya-tanya apakah ada yang terjadi. Ketika layar terasa beku, pengguna menebak-nebak, dan menebak berubah menjadi klik berulang, pengiriman ganda, dan tiket dukungan.
Pekerjaan latar belakang yang baik sangat berkaitan dengan kepercayaan. Pengguna ingin tiga hal:
Tanpa itu, pekerjaan mungkin berjalan dengan baik, tetapi pengalamannya terasa rusak.
Satu kebingungan umum adalah memperlakukan request lambat sebagai pekerjaan latar belakang. Request lambat masih satu panggilan web yang membuat pengguna menunggu. Pekerjaan latar belakang berbeda: Anda memulai job, mendapat konfirmasi segera, dan pemrosesan berat terjadi di tempat lain sementara UI tetap bisa dipakai.
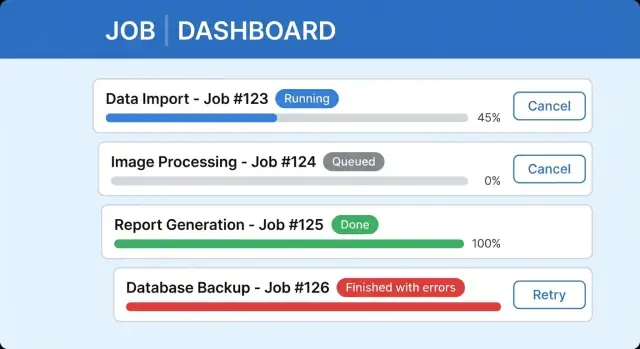
Contoh: pengguna mengunggah CSV untuk mengimpor pelanggan. Jika UI memblokir, mereka mungkin me-refresh, mengunggah lagi, dan membuat duplikasi. Jika impor berjalan di latar belakang dan UI menampilkan kartu job dengan progres dan opsi Cancel yang aman, mereka bisa terus bekerja dan kembali untuk melihat hasil yang jelas.
Ketika orang bicara tentang tugas latar belakang dengan pembaruan progres, biasanya mereka bermaksud empat bagian yang bekerja bersama.
Sebuah job adalah unit kerja: "impor CSV ini," "hasilkan laporan ini," atau "kirim 5.000 email." Sebuah antrean adalah barisan tempat job menunggu sampai bisa diproses. Seorang worker mengambil job dari antrean dan melakukan pekerjaan (satu per satu atau paralel).
Untuk UI, bagian terpenting adalah lifecycle state job. Jaga state sedikit dan dapat diprediksi:
Setiap job butuh job ID (referensi unik). Saat pengguna mengklik tombol, kembalikan ID itu segera dan tunjukkan baris "Task started" di panel tugas.
Kemudian Anda butuh cara untuk menanyakan, "Apa yang terjadi sekarang?" Itu biasanya sebuah endpoint status (atau metode baca apa pun) yang menerima job ID dan mengembalikan state serta detail progres. UI menggunakannya untuk menampilkan persentase selesai, langkah saat ini, dan pesan apa pun.
Akhirnya, status harus disimpan di penyimpanan durable, bukan hanya di memori. Worker bisa crash, aplikasi restart, dan pengguna me-refresh halaman. Penyimpanan durable membuat progres dan hasil dapat diandalkan. Setidaknya, simpan:
Jika Anda membangun di platform seperti AppMaster, perlakukan store status seperti model data lain: UI membacanya berdasarkan job ID, dan worker memperbaruinya saat berpindah melalui job.
Pola antrean yang Anda pilih mengubah seberapa "adil" dan dapat diprediksi aplikasi Anda terasa. Jika sebuah tugas duduk di belakang tumpukan pekerjaan lain, pengguna mengalaminya sebagai penundaan acak, bahkan saat sistem sehat. Itu membuat pilihan antrean menjadi keputusan UX, bukan sekadar infrastruktur.
Antrean berbasis database sederhana sering cukup ketika volume rendah, job singkat, dan Anda dapat mentolerir retry sesekali. Mudah diatur, mudah diperiksa, dan Anda bisa menyimpan semuanya di satu tempat. Contoh: admin menjalankan laporan malam untuk tim kecil. Jika retry satu kali, tidak ada yang panik.
Anda biasanya butuh sistem antrean khusus ketika throughput meningkat, job menjadi berat, atau keandalan menjadi prioritas utama. Impor, pemrosesan video, notifikasi massal, dan workflow yang harus berjalan lintas restart mendapat manfaat dari isolasi, visibilitas, dan perilaku retry yang lebih aman. Ini penting untuk progres yang terlihat pengguna karena orang memperhatikan pembaruan yang hilang dan state yang macet.
Struktur antrean juga memengaruhi prioritas. Satu antrean lebih sederhana, tetapi mencampur pekerjaan cepat dan lambat bisa membuat tindakan cepat terasa lambat. Antrean terpisah membantu ketika Anda memiliki pekerjaan yang dipicu pengguna yang harus terasa instan berdampingan dengan batch terjadwal yang bisa menunggu.
Atur batas concurrency dengan sengaja. Paralelisme berlebih bisa membebani database dan membuat progres terasa lompat-lompat. Terlalu sedikit membuat sistem terasa lambat. Mulailah dengan concurrency kecil dan dapat diprediksi per antrean, lalu tingkatkan hanya jika Anda bisa menjaga waktu penyelesaian tetap stabil.
Jika model progres Anda kabur, UI juga akan terasa kabur. Tentukan apa yang sistem bisa laporkan dengan jujur, seberapa sering berubah, dan apa yang harus dilakukan pengguna dengan informasi itu.
Skema status sederhana yang bisa didukung sebagian besar job tampak seperti ini:
Selanjutnya, definisikan apa arti "progres".
Persen bekerja ketika ada denominator nyata (baris di file, email yang harus dikirim). Itu menyesatkan ketika pekerjaan tidak dapat diprediksi (menunggu pihak ketiga, compute variabel, query mahal). Dalam kasus tersebut, progres berbasis langkah lebih membangun kepercayaan karena bergerak maju dalam potongan yang jelas.
Aturan praktis:
Simpan hasil parsial saat job berjalan. Itu memungkinkan UI menampilkan sesuatu yang berguna sebelum job selesai, seperti hitungan error live atau pratinjau apa yang berubah. Untuk impor CSV, Anda mungkin menyimpan rows_read, rows_created, rows_updated, rows_rejected, plus beberapa pesan error terakhir.
Ini adalah fondasi untuk tugas latar belakang dengan pembaruan progres yang dipercaya pengguna: UI tetap tenang, angka terus bergerak, dan ringkasan "apa yang terjadi" siap saat job berakhir.
Mengirim progres dari backend ke layar adalah tempat banyak implementasi gagal. Pilih metode pengiriman yang sesuai seberapa sering progres berubah dan berapa banyak pengguna yang Anda perkirakan akan memantau.
Polling adalah yang paling sederhana: UI menanyakan status setiap N detik. Default yang baik adalah 2 hingga 5 detik saat pengguna aktif melihat halaman, lalu melambat seiring waktu. Jika tugas berjalan lebih dari satu menit, pindah ke 10–30 detik. Jika tab berada di background, pelankan lagi.
Push (WebSockets, server-sent events, atau notifikasi mobile) membantu ketika progres berubah cepat atau pengguna peduli tentang "sekarang juga." Push bagus untuk immediacy, tetapi Anda tetap perlu fallback saat koneksi putus.
Pendekatan hibrida seringkali terbaik: polling cepat di awal (agar UI cepat melihat antrean berubah jadi berjalan), lalu pelankan setelah job stabil. Jika menambahkan push, tetap jaga polling lambat sebagai jaring pengaman.
Saat pembaruan berhenti, perlakukan itu sebagai state tingkat pertama. Tampilkan "Terakhir diperbarui 2 menit lalu" dan tawarkan refresh. Di backend, tandai job sebagai stale jika tidak ada heartbeat.
Kejelasan datang dari dua hal: seperangkat state yang kecil dan dapat diprediksi, serta copy yang memberi tahu orang apa yang terjadi selanjutnya.
Namakan state di UI, bukan hanya di backend. Sebuah job bisa saja antrean (menunggu giliran), berjalan (sedang dikerjakan), menunggu input (butuh pilihan), selesai, selesai dengan error, atau gagal. Jika pengguna tidak bisa membedakan ini, mereka akan mengira aplikasi macet.
Gunakan copy yang jelas dan berguna di samping indikator progres. "Mengimpor 3.200 baris (1.140 diproses)" lebih baik daripada "Memproses." Tambahkan satu kalimat yang menjawab: bolehkah saya pergi, dan apa yang akan terjadi? Misalnya: "Anda bisa menutup jendela ini. Kami akan terus mengimpor di latar belakang dan memberi tahu Anda saat siap."
Di mana progres ditempatkan harus sesuai konteks pengguna:
Untuk apa pun yang lebih dari satu menit, tambahkan halaman Jobs sederhana (atau panel Activity) agar orang bisa menemukan pekerjaan nanti.
UI tugas panjang yang jelas biasanya mencakup label status dengan waktu terakhir diperbarui, progress bar (atau langkah) dengan satu baris detail, perilaku Cancel yang aman, dan area hasil dengan ringkasan serta aksi berikutnya. Simpan job yang selesai agar dapat ditemukan sehingga pengguna tidak merasa dipaksa menunggu di satu layar.
"Selesai" bukan selalu kemenangan. Ketika job latar belakang memproses 9.500 record dan 120 gagal, pengguna perlu memahami apa yang terjadi tanpa membaca log.
Perlakukan keberhasilan parsial sebagai hasil yang setara. Di baris status utama, tampilkan kedua sisi: "Diimpor 9.380 dari 9.500. 120 gagal." Itu menjaga kepercayaan tinggi karena sistem jujur, dan mengonfirmasi bahwa pekerjaan disimpan.
Lalu tunjukkan ringkasan error kecil yang bisa diambil tindakan: "Field wajib hilang (63)" dan "Format tanggal tidak valid (41)." Dalam state akhir, "Selesai dengan masalah" sering lebih jelas daripada "Gagal," karena tidak memberi kesan bahwa tidak ada yang berhasil.
Laporan error yang bisa diekspor mengubah kebingungan menjadi daftar tugas. Jaga sederhana: nomor baris atau pengenal item, kategori error, pesan yang bisa dimengerti manusia, dan nama field jika relevan.
Buat aksi berikutnya jelas dan dekat dengan ringkasan: perbaiki data dan ulangi item yang gagal, unduh laporan error, atau hubungi dukungan jika terlihat seperti masalah sistem.
Cancel dan retry terlihat sederhana, tapi cepat merusak kepercayaan saat UI mengatakan satu hal dan sistem melakukan hal lain. Definisikan apa arti Cancel untuk tiap tipe job, lalu tampilkan itu dengan jujur di antarmuka.
Biasanya ada dua mode cancel yang valid:
Di UI, tunjukkan state menengah seperti "Permintaan pembatalan" agar pengguna tidak terus mengklik.
Jadikan cancel aman dengan merancang pekerjaan agar bisa diulang. Jika job menulis data, utamakan operasi idempoten (aman dijalankan dua kali) dan lakukan pembersihan jika perlu. Misalnya, jika impor CSV membuat record, simpan job-run ID sehingga Anda bisa meninjau apa yang berubah pada run #123.
Retry butuh kejelasan yang sama. Mengulang instance job yang sama masuk akal jika bisa melanjutkan. Membuat instance job baru lebih aman ketika Anda ingin run bersih dengan timestamp dan jejak audit baru. Jelaskan apa yang akan terjadi dan apa yang tidak akan terjadi.
Guardrail yang menjaga cancel dan retry tetap dapat diprediksi:
Alur end-to-end yang baik dimulai dengan satu aturan: UI tidak boleh menunggu pekerjaan itu sendiri. UI hanya menunggu job ID.
Pengguna memulai tugas, API merespons cepat. Ketika pengguna mengklik Import atau Generate report, server segera membuat record job dan mengembalikan job ID unik.
Masukkan kerja ke antrean dan atur status pertama. Masukkan job ID ke antrean dan set status ke antrean dengan progres 0%. Ini memberi UI sesuatu yang nyata untuk ditampilkan bahkan sebelum worker mengambilnya.
Worker berjalan dan melaporkan progres. Saat worker mulai, set status jadi berjalan, simpan waktu mulai, dan perbarui progres dalam loncatan kecil dan jujur. Jika Anda tidak bisa mengukur persen, tampilkan langkah seperti Parsing, Validating, Saving.
UI menjaga orientasi pengguna. UI mem-poll atau berlangganan pembaruan dan merender state yang jelas. Tampilkan pesan singkat (apa yang sedang terjadi sekarang) dan hanya aksi yang masuk akal untuk saat itu.
Finalisasi dengan hasil yang durable. Saat selesai, simpan waktu selesai, output (referensi unduhan, ID yang dibuat, hitungan ringkasan), dan detail error. Dukung outcome selesai-dengan-error sebagai hasil sendiri, bukan sukses yang samar.
Cancel harus eksplisit: permintaan pembatalan meminta cancel, lalu worker mengakui dan menandai dibatalkan. Retry sebaiknya membuat job ID baru, menjaga asli sebagai riwayat, dan menjelaskan apa yang akan dijalankan ulang.
Tempat umum di mana tugas latar belakang dengan pembaruan progres penting adalah impor CSV. Bayangkan CRM tempat sales ops mengunggah customers.csv dengan 8.420 baris.
Segera setelah unggah, UI harus beralih dari "Saya mengklik tombol" ke "ada job, dan Anda bisa pergi." Kartu job sederhana di halaman Imports bekerja baik:
Saat berjalan, tampilkan satu angka progres yang dapat dipercaya pengguna (baris diproses) dan satu baris status singkat (apa yang sedang dikerjakan sekarang). Jika pengguna bernavigasi pergi, simpan job di area Recent jobs.
Sekarang tambahkan kegagalan parsial. Saat job selesai, hindari banner Failed yang menakutkan jika sebagian besar baris baik. Gunakan Selesai dengan isu plus pembagian yang jelas:
Diimpor 8.102 pelanggan. Dilewati 318 baris.
Jelaskan alasan teratas dengan kata-kata sederhana: format email tidak valid, field wajib seperti company kosong, atau duplikat external ID. Biarkan pengguna mengunduh atau melihat tabel error dengan nomor baris, nama pelanggan, dan field yang perlu diperbaiki.
Retry harus terasa aman dan spesifik. Aksi utama bisa jadi Retry failed rows, yang membuat job baru yang hanya memproses ulang 318 baris yang dilewati setelah pengguna memperbaiki CSV. Simpan job asli dalam mode read-only agar riwayat tetap jujur.
Terakhir, buat hasil mudah ditemukan nanti. Setiap impor harus punya ringkasan stabil: siapa yang menjalankan, kapan, nama file, hitungan (diimpor, dilewati), dan cara membuka laporan error.
Cara tercepat kehilangan kepercayaan adalah menampilkan angka yang tidak nyata. Progress bar yang diam di 0% selama dua menit lalu melonjak ke 90% terasa seperti tebakan. Jika Anda tidak tahu persen yang sebenarnya, tampilkan langkah (Antrean, Memproses, Finalisasi) atau "X dari Y item diproses."
Masalah umum lain adalah progres hanya disimpan di memori. Jika worker restart, UI "lupa" job atau mengatur ulang progres. Simpan state job di storage durable dan buat UI membaca dari satu sumber kebenaran itu.
UX retry juga rusak ketika pengguna bisa memulai job yang sama beberapa kali. Jika tombol Import CSV masih terlihat aktif, seseorang mengklik dua kali dan membuat duplikat. Kini retry menjadi tidak jelas karena tidak terlihat run mana yang harus diperbaiki.
Kesalahan yang sering muncul:
Detail kecil tapi penting: pisahkan pesan pengguna dari detail pengembang. Tampilkan "12 baris gagal validasi" ke pengguna, dan simpan jejak teknis di log.
Sebelum rilis, lakukan pengecekan cepat pada bagian yang diperhatikan pengguna: kejelasan, kepercayaan, dan pemulihan.
Setiap job harus mengekspos snapshot yang bisa Anda tampilkan di mana saja: state (antrean, berjalan, berhasil, gagal, dibatalkan), progres (0-100 atau langkah), pesan singkat, timestamp (dibuat, dimulai, selesai), dan pointer hasil (di mana output atau laporan berada).
Buat state UI jelas dan konsisten. Pengguna butuh satu tempat andal untuk menemukan job saat ini dan yang lampau, plus label yang jelas saat mereka kembali nanti ("Selesai kemarin", "Masih berjalan"). Panel Recent jobs sering mencegah klik ulang dan kerja duplikat.
Tentukan aturan cancel dan retry dalam istilah sederhana. Putuskan apa arti Cancel untuk tiap tipe job, apakah retry diizinkan, dan apa yang akan digunakan kembali (input sama, job ID baru). Lalu uji kasus tepi seperti membatalkan tepat sebelum selesai.
Perlakukan kegagalan parsial sebagai hasil nyata. Tampilkan ringkasan singkat ("Diimpor 97, dilewati 3") dan sediakan laporan yang bisa langsung ditindaklanjuti pengguna.
Rencanakan pemulihan. Job harus bertahan lewat restart, dan job yang macet harus timeout ke state jelas dengan panduan ("Coba lagi" atau "Hubungi support dengan job ID").
Pilih satu workflow yang sering dikeluhkan pengguna: impor CSV, ekspor laporan, pengiriman email massal, atau pemrosesan gambar. Mulai kecil dan buktikan dasar: job dibuat, berjalan, melaporkan status, dan pengguna bisa menemukannya nanti.
Layar riwayat job sederhana sering menjadi lonjakan kualitas terbesar. Itu memberi orang tempat untuk kembali, alih-alih menatap spinner.
Pilih satu metode pengiriman progres terlebih dahulu. Polling cukup untuk versi pertama. Atur interval refresh cukup lambat agar ramah ke backend, tetapi cukup cepat agar terasa hidup.
Urutan pembangunan praktis yang menghindari rewrite:
Jika Anda membangun ini tanpa menulis kode, platform no-code seperti AppMaster dapat membantu dengan memungkinkan Anda memodelkan tabel status job (PostgreSQL) dan memperbaruinya dari workflow, lalu merender status itu di web dan mobile UI. Untuk tim yang ingin satu tempat untuk membangun backend, UI, dan logika latar belakang, AppMaster (appmaster.io) dirancang untuk aplikasi penuh, bukan hanya formulir atau halaman.
Sebuah job latar belakang dibuat dengan cepat dan langsung mengembalikan job ID, sehingga UI tetap bisa dipakai. Permintaan lambat membuat pengguna menunggu hingga panggilan web selesai, yang sering menyebabkan refresh, klik ganda, dan pengiriman duplikat.
Buat sederhana: antrean, berjalan, selesai, dan gagal, plus dibatalkan jika Anda mendukung pembatalan. Tambahkan outcome terpisah seperti “selesai dengan masalah” ketika sebagian besar pekerjaan berhasil tapi ada item yang gagal, agar pengguna tidak mengira semuanya hilang.
Kembalikan job ID unik segera setelah pengguna memulai aksi, lalu render baris atau kartu tugas menggunakan ID itu. UI harus membaca status berdasarkan job ID sehingga pengguna bisa me-refresh, pindah tab, atau kembali nanti tanpa kehilangan jejak.
Simpan status job di tabel database yang durable, jangan hanya di memori. Simpan state saat ini, timestamp, nilai progres, pesan singkat untuk pengguna, dan ringkasan hasil atau error sehingga UI selalu bisa membangun kembali tampilan yang sama setelah restart.
Gunakan persentase hanya ketika Anda jujur bisa melaporkan “X dari Y” item yang diproses. Jika Anda tidak punya denominator nyata, gunakan progres berbasis langkah seperti “Validasi”, “Impor”, dan “Finalisasi”, dan perbarui pesan agar pengguna merasakan ada kemajuan.
Polling adalah yang paling sederhana dan bekerja baik untuk kebanyakan aplikasi; mulai di kisaran setiap 2–5 detik saat pengguna melihat, lalu pelankan untuk job panjang atau tab background. Push terasa lebih instan, tetapi Anda tetap perlu fallback karena koneksi bisa putus dan pengguna berpindah layar.
Tampilkan bahwa pembaruan sudah usang alih-alih pura-pura job masih aktif, misalnya dengan menampilkan “Terakhir diperbarui 2 menit lalu” dan tawarkan refresh manual. Di backend, deteksi heartbeat yang hilang dan masukkan job ke state jelas dengan panduan, seperti coba lagi atau hubungi support dengan job ID.
Buat aksi berikutnya jelas: apakah pengguna bisa terus bekerja, meninggalkan halaman, atau membatalkan dengan aman. Untuk tugas lebih dari satu menit, view Jobs atau Activity yang didedikasikan membantu pengguna menemukan hasil nanti ketimbang menatap spinner.
Perlakukan itu sebagai outcome yang setara dan sebutkan kedua sisi dengan jelas, seperti “Diimpor 9.380 dari 9.500. 120 gagal.” Lalu berikan ringkasan error kecil yang dapat ditindaklanjuti oleh pengguna tanpa membaca log, dan simpan detail teknis di log internal, bukan di layar pengguna.
Tentukan arti Cancel untuk tiap jenis job dan tampilkan dengan jujur, termasuk state tengah seperti “permintaan pembatalan” agar pengguna tidak terus mengklik. Buat pekerjaan idempoten bila mungkin, batasi retry, dan tentukan apakah retry melanjutkan job yang sama atau membuat job baru dengan jejak audit bersih.



Eksperimen dengan AppMaster dengan paket gratis.
Saat Anda siap, Anda dapat memilih langganan yang tepat.


