Aplikasi pemesanan peralatan: cegah konflik dan lacak pengembalian
Rencanakan aplikasi pemesanan peralatan yang mencegah pemesanan ganda, mencatat pengembalian dan kerusakan, serta menahan item bermasalah untuk pemeliharaan.
Pelajari cara memodelkan timer SLA dan eskalasi dengan status jelas, aturan yang mudah dipelihara, dan jalur eskalasi sederhana agar aplikasi workflow tetap mudah diubah.
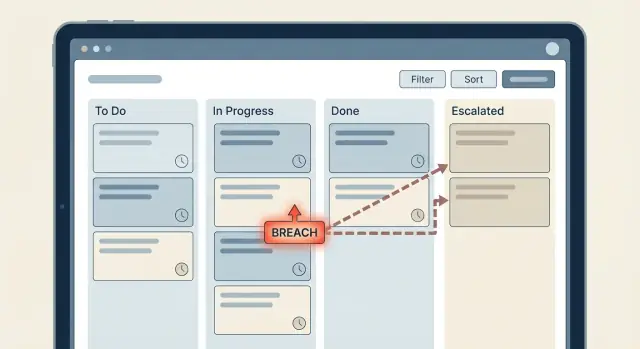
Aturan berbasis waktu biasanya dimulai sederhana: “Jika tiket tidak dibalas dalam 2 jam, beri tahu seseorang.” Lalu workflow tumbuh, tim menambahkan pengecualian, dan tiba-tiba tidak ada yang yakin apa yang terjadi. Begitulah timer SLA dan eskalasi berubah menjadi labirin.
Membantu jika komponen yang bergerak diberi nama dengan jelas.
Sebuah timer adalah jam yang Anda mulai (atau jadwalkan) setelah suatu peristiwa, seperti “tiket dipindah ke Waiting for Agent.” Sebuah escalation adalah apa yang Anda lakukan ketika jam itu mencapai ambang, seperti memberi tahu lead, mengubah prioritas, atau menetapkan ulang pekerjaan. Sebuah breach adalah fakta yang dicatat yang mengatakan, “Kita melewatkan SLA,” yang Anda gunakan untuk pelaporan, peringatan, dan tindak lanjut.
Masalah muncul ketika logika waktu tersebar di seluruh aplikasi: beberapa pengecekan di alur “update ticket”, lebih banyak pengecekan dalam job malam, dan aturan satu-kali ditambahkan nanti untuk pelanggan khusus. Setiap bagian masuk akal sendiri, tetapi bersama-sama mereka menciptakan kejutan.
Gejala khas:
Tujuannya adalah perilaku yang dapat diprediksi dan tetap mudah diubah nanti: satu sumber kebenaran yang jelas untuk penjadwalan SLA, state pelanggaran eksplisit yang bisa Anda laporkan, dan langkah eskalasi yang bisa Anda sesuaikan tanpa berburu melalui logika visual.
Sebelum membuat timer apa pun, tuliskan janji tepat yang Anda ukur. Banyak logika berantakan muncul dari upaya menutup setiap kemungkinan aturan waktu sejak hari pertama.
Jenis SLA umum terdengar mirip tetapi mengukur hal berbeda:
Selanjutnya, tentukan apa arti “waktu”. Waktu kalender menghitung 24/7. Waktu kerja hanya menghitung jam kerja yang didefinisikan (misalnya Senin-Jumat, 9-6). Jika Anda tidak benar-benar perlu waktu kerja, hindari sejak awal. Itu menambah kasus tepi seperti hari libur, zona waktu, dan hari sebagian.
Lalu tentukan jeda dengan spesifik. Jeda bukan sekadar “status berubah.” Itu aturan dengan pemilik. Siapa yang bisa menjeda (hanya agen, hanya sistem, tindakan pelanggan)? Status mana yang menjeda (Waiting on Customer, On Hold, Pending Approval)? Apa yang melanjutkannya? Saat dilanjutkan, apakah Anda melanjutkan dari sisa waktu atau memulai ulang timer?
Akhirnya, definisikan apa arti breach dalam istilah produk. Sebuah breach harus menjadi hal konkret yang bisa Anda simpan dan query, seperti:
breached_at) (kapan tenggat terlewat)Contoh: “First response SLA breached” bisa berarti tiket mendapat state Breached, cap waktu breached_at, dan level eskalasi diset ke 1.
Jika Anda ingin timer SLA dan eskalasi tetap mudah dibaca, perlakukan SLA seperti mesin status kecil. Ketika “kebenaran” tersebar di cek-cek kecil (if now > due, if priority is high, if last reply is empty), logika visual cepat menjadi berantakan dan perubahan kecil merusak banyak hal.
Mulailah dengan sekumpulan state SLA singkat dan disetujui yang bisa dimengerti setiap langkah workflow. Bagi banyak tim, ini sudah mencakup sebagian besar kasus:
Satu flag breached = true/false jarang cukup. Anda masih perlu tahu SLA mana yang breached (first response vs resolution), apakah sedang dijeda, dan apakah Anda sudah melakukan eskalasi. Tanpa konteks itu, orang mulai menurunkan makna dari komentar, cap waktu, dan nama status. Di situ logika menjadi rapuh.
Jadikan state eksplisit dan simpan cap waktu yang menjelaskannya. Lalu keputusan jadi sederhana: evaluator membaca record, menentukan state berikutnya, dan semua hal lain bereaksi terhadap state itu.
Field yang berguna untuk disimpan bersama state:
started_at dan due_at (jam apa yang kita jalankan, dan kapan jatuh tempo?)breached_at (kapan sebenarnya melewati batas?)paused_at dan paused_reason (mengapa jam berhenti?)breach_reason (aturan mana yang memicu breach, dengan kata-kata biasa)last_escalation_level (agar Anda tidak memberi notifikasi level yang sama dua kali)Contoh: sebuah tiket pindah ke “Waiting on customer.” Set state SLA ke Paused, catat paused_reason = "waiting_on_customer", dan hentikan timer. Saat pelanggan membalas, lanjutkan dengan mengatur started_at baru (atau unpause dan hitung ulang due_at). Tidak perlu mencari di banyak kondisi.
Ladder eskalasi adalah rencana jelas untuk apa yang terjadi saat timer SLA mendekati pelanggaran atau sudah breached. Kesalahan umum adalah menyalin bagan organisasi ke workflow. Anda ingin set langkah terkecil yang membuat item yang macet bergerak lagi.
Ladder sederhana yang banyak tim gunakan: agen yang ditugaskan (Level 0) mendapat dorongan pertama, lalu team lead (Level 1) dilibatkan, dan baru setelah itu naik ke manager (Level 2). Ini efektif karena dimulai di tempat pekerjaan sebenarnya bisa diselesaikan, dan meningkatkan otoritas hanya saat diperlukan.
Untuk menjaga aturan eskalasi tetap mudah dipelihara, simpan ambang eskalasi sebagai data, bukan kondisi yang di-hardcode. Letakkan dalam tabel atau objek pengaturan: “pengingat pertama setelah 30 menit” atau “escalate ke lead setelah 2 jam.” Saat kebijakan berubah, Anda memperbarui satu tempat alih-alih mengedit banyak workflow.
Eskalasi berubah menjadi spam ketika sering menyala. Tambahkan guardrail sehingga setiap langkah punya tujuan:
Notifikasi saja tidak menyelesaikan pekerjaan yang macet jika tanggung jawab tetap kabur. Definisikan aturan kepemilikan sejak awal: apakah tiket tetap ditugaskan ke agen, dialihkan ke lead, atau pindah ke antrean bersama?
Contoh: setelah eskalasi Level 1, tugaskan ulang ke team lead dan jadikan agen asli sebagai watcher. Itu membuat jelas siapa yang harus bertindak selanjutnya dan mencegah ladder memantulkan item yang sama antar orang.
Cara termudah menjaga timer SLA dan eskalasi agar mudah dipelihara adalah memperlakukannya seperti sistem kecil dengan tiga bagian: events, evaluator, dan actions. Ini mencegah logika waktu menyebar ke puluhan cek “if time > X”.
Events adalah fakta sederhana yang tidak boleh mengandung matematika timer. Mereka menjawab “apa yang berubah?” bukan “apa yang harus kita lakukan tentangnya?” Events tipikal termasuk ticket created, agent replied, customer replied, status changed, atau manual pause/resume.
Simpan ini sebagai cap waktu dan field status (misalnya: created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
Buat satu langkah “SLA evaluator” yang berjalan setelah setiap event dan pada jadwal periodik. Evaluator ini adalah satu-satunya tempat yang menghitung due_at dan sisa waktu. Ia membaca fakta saat ini, menghitung ulang tenggat, dan menulis field state SLA eksplisit seperti sla_response_state dan sla_resolution_state.
Di sinilah pemodelan state breach tetap bersih: evaluator menetapkan status seperti OK, AtRisk, Breached, alih-alih menyembunyikan logika di notifikasi.
Notifikasi, penugasan, dan eskalasi sebaiknya hanya memicu ketika sebuah state berubah (misalnya: OK -> AtRisk). Pisahkan pengiriman pesan dari pembaruan state. Dengan begitu Anda bisa mengubah siapa yang diberi tahu tanpa menyentuh perhitungan.
Setup yang dapat dipelihara biasanya terlihat seperti ini: beberapa field pada record, tabel kebijakan kecil, dan satu evaluator yang memutuskan apa yang terjadi selanjutnya.
Mulai dengan entitas yang memiliki SLA (ticket, order, request). Tambahkan cap waktu eksplisit dan satu field “current SLA state”. Jaga agar sederhana dan dapat diprediksi.
Lalu tambahkan tabel kebijakan kecil yang menjelaskan aturan alih-alih meng-hardcode mereka ke banyak flow. Versi sederhana adalah satu baris per prioritas (P1, P2, P3) dengan kolom target menit dan ambang eskalasi (misalnya: warning di 80%, breach di 100%). Ini membedakan antara mengubah satu record versus mengedit lima workflow.
Alih-alih membuat timer terpisah di banyak tempat, gunakan satu proses terjadwal yang memeriksa item secara berkala (setiap menit untuk SLA ketat, setiap 5 menit untuk banyak tim). Jadwal memanggil satu evaluator yang:
sla_state dan next_check_atIni membuat timer SLA dan eskalasi lebih mudah dipahami karena Anda men-debug satu evaluator, bukan banyak timer.
Evaluator harus mengeluarkan state baru dan apakah itu berubah. Hanya kirim pesan atau buat tugas saat state berpindah (misalnya ok -> warning, warning -> breached). Jika record tetap breached selama satu jam, Anda tidak ingin 12 notifikasi berulang.
Pola praktis: simpan sla_state dan last_escalation_level, bandingkan dengan nilai yang baru dihitung, dan hanya kemudian panggil messaging (email/SMS/Telegram) atau buat tugas internal.
Jeda adalah tempat aturan waktu biasanya kacau. Jika Anda tidak memodelkannya dengan jelas, SLA akan terus berjalan padahal seharusnya berhenti, atau ter-reset saat seseorang mengklik status yang salah.
Aturan sederhana: hanya satu status (atau beberapa kecil) yang menjeda jam. Pilihan umum adalah Waiting for customer. Saat tiket masuk ke status itu, simpan cap waktu pause_started_at. Saat pelanggan membalas dan tiket keluar dari status itu, tutup jeda dengan menulis pause_ended_at dan tambahkan durasi ke paused_total_seconds.
Jangan hanya menyimpan satu counter. Tangkap setiap jendela jeda (start, end, siapa atau apa yang memicunya) sehingga Anda punya jejak audit. Nanti, saat seseorang bertanya kenapa sebuah kasus breached, Anda bisa menunjukkan bahwa itu menghabiskan 19 jam menunggu pelanggan.
Penugasan ulang dan perubahan status normal tidak boleh merestart jam. Pisahkan cap waktu SLA dari field kepemilikan. Misalnya, sla_started_at dan sla_due_at harus diset sekali (pada pembuatan, atau saat kebijakan SLA berubah), sementara reassignment hanya memperbarui assignee_id. Evaluator Anda kemudian dapat menghitung waktu yang berlalu sebagai: now minus sla_started_at minus paused_total_seconds.
Aturan yang menjaga timer SLA dan eskalasi tetap dapat diprediksi:
Cara sederhana menguji desain Anda adalah tiket dukungan dengan dua SLA: first response 30 menit, dan resolution penuh 8 jam. Di sinilah logika sering rusak jika tersebar di layar dan tombol.
Anggap setiap tiket menyimpan: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met), plus cap waktu seperti created_at, first_agent_reply_at, dan resolved_at.
Timeline realistis:
Untuk eskalasi, pertahankan satu chain yang jelas yang memicu pada transisi state. Misalnya, saat response menjadi Warning, beri tahu agen yang ditugaskan. Saat menjadi Breached, beri tahu team lead dan naikkan prioritas.
Di setiap langkah, perbarui set kecil field yang sama agar mudah dipikirkan:
response_status atau resolution_status ke Pending, Warning, Breached, atau Met.*_warning_at dan *_breach_at cap waktu sekali, lalu jangan timpa lagi.escalation_level (0, 1, 2) dan set escalated_to (Agent, Lead, Manager).sla_events dengan tipe event dan siapa yang diberi tahu.priority dan due_at agar UI dan laporan mencerminkan eskalasi.Kuncinya adalah Warning dan Breached adalah state eksplisit. Anda bisa melihatnya di data, mengauditnya, dan mengubah ladder nanti tanpa berburu cek timer tersembunyi.
Logika SLA menjadi berantakan saat menyebar. Sebuah pengecekan waktu cepat ditambahkan ke tombol di sini, sebuah alert kondisional di situ, dan segera tidak ada yang bisa menjelaskan mengapa tiket tereskalasi. Jadikan timer SLA dan eskalasi potongan logika kecil dan terpusat yang dibaca setiap layar dan aksi.
Perangkap umum adalah menyematkan pengecekan waktu di banyak tempat (UI, handler API, aksi manual). Perbaikannya adalah menghitung status SLA di satu evaluator dan menyimpan hasilnya di record. Layar hanya membaca status, bukan membuatnya.
Perangkap lain adalah membiarkan timer menggunakan jam yang berbeda. Jika browser menghitung “menit sejak dibuat” tapi backend menggunakan waktu server, Anda akan melihat kasus tepi terkait sleep, zona waktu, dan pergantian daylight. Gunakan waktu server untuk apa pun yang memicu eskalasi.
Notifikasi juga bisa cepat berisik. Jika Anda “cek setiap menit dan kirim jika terlambat”, orang bisa ter-spam setiap menit. Kaitkan pesan ke transisi: “warning sent,” “escalated,” “breached.” Maka Anda mengirim sekali per langkah dan bisa mengaudit apa yang terjadi.
Logika jam kerja adalah sumber kompleksitas lain. Jika setiap aturan punya cabang “jika akhir pekan maka…”, pembaruan menjadi menyakitkan. Letakkan matematika jam kerja di satu fungsi (atau satu blok bersama) yang mengembalikan “menit SLA yang terpakai sejauh ini,” dan gunakan ulang.
Terakhir, jangan mengandalkan menghitung ulang breach dari nol. Simpan momen saat itu terjadi:
breached_at pertama kali Anda mendeteksi breach, dan jangan timpa.escalation_level dan last_escalated_at agar tindakan idempoten.notified_warning_at (atau serupa) untuk mencegah alert berulang.Contoh: tiket mencapai “Response SLA breached” pada 10:07. Jika Anda hanya menghitung ulang, perubahan status atau bug pause/resume bisa membuatnya tampak breach terjadi pada 10:42. Dengan breached_at = 10:07, pelaporan dan postmortem tetap konsisten.
Sebelum menambahkan timer dan alert, lakukan satu pemeriksaan dengan tujuan membuat aturan dapat dibaca sebulan dari sekarang.
Tes praktis: pilih satu tiket yang hampir melewati tenggat dan putar ulang timeline-nya. Jika Anda tidak bisa menjelaskan apa yang akan terjadi pada setiap perubahan status tanpa membaca seluruh workflow, model Anda terlalu tersebar.
Bangun slice paling kecil yang berguna dulu. Pilih satu SLA (misalnya, first response) dan satu level eskalasi (misalnya, beri tahu team lead). Anda akan belajar lebih banyak dari seminggu penggunaan nyata daripada dari desain sempurna di atas kertas.
Simpan ambang dan penerima sebagai data, bukan logika. Masukkan menit dan jam, aturan jam kerja, siapa yang diberi tahu, dan antrean yang memiliki kasus ke dalam tabel atau record konfigurasi. Maka workflow tetap stabil sementara bisnis mengubah angka dan routing.
Rencanakan tampilan dashboard sederhana lebih awal. Anda tidak perlu sistem analitik besar, hanya gambaran bersama tentang apa yang terjadi sekarang: on track, warning, breached, escalated.
Jika Anda membangun ini di alat no-code, pilih platform yang memungkinkan memodelkan data, logika, dan evaluator terjadwal dalam satu tempat. Misalnya, AppMaster (appmaster.io) mendukung pemodelan database, proses bisnis visual, dan menghasilkan aplikasi siap produksi, yang cocok dengan pola “events, evaluator, actions”.
Perbaiki dengan aman dengan iterasi dalam urutan ini:
Saat siap, bangun versi kecil dulu, lalu kembangkan dengan umpan balik nyata dan tiket nyata.
Mulailah dengan definisi yang jelas tentang janji yang Anda ukur, seperti first response atau resolution, dan tuliskan aturan mulai, berhenti, dan jeda secara tepat. Lalu pusatkan perhitungan waktu di satu evaluator yang menetapkan status SLA eksplisit daripada menyebarkan pengecekan “if now > X” di banyak workflow.
Timer adalah jam yang Anda mulai atau jadwalkan setelah suatu peristiwa, seperti tiket berpindah ke status baru. Eskalasi adalah tindakan yang Anda ambil saat ambang tercapai, misalnya memberi tahu lead atau mengubah prioritas. Breach adalah fakta yang disimpan bahwa SLA terlewat, yang bisa Anda laporkan kemudian.
First response mengukur waktu hingga balasan manusia pertama yang bermakna, sedangkan resolution mengukur waktu hingga masalah benar-benar ditutup. Mereka berperilaku berbeda terkait jeda dan pembukaan kembali, jadi memodelkannya terpisah membuat aturan lebih sederhana dan pelaporan akurat.
Gunakan waktu kalender secara default karena lebih sederhana dan lebih mudah di-debug. Tambahkan aturan waktu kerja (business-hours) hanya jika benar-benar diperlukan, karena jam kerja memperkenalkan kompleksitas tambahan seperti hari libur, zona waktu, dan perhitungan hari sebagian.
Modelkan jeda sebagai status eksplisit yang terikat ke status tertentu, misalnya Waiting on Customer, dan simpan kapan jeda dimulai dan berakhir. Saat melanjutkan, lanjutkan dari sisa waktu atau hitung ulang due_at di satu tempat, tetapi jangan biarkan toggle status acak mereset jam.
Satu flag breached = true/false menyembunyikan konteks penting seperti SLA mana yang breached, apakah sedang dijeda, dan apakah sudah dielaskan. Status eksplisit seperti On track, Warning, Breached, Paused, dan Completed membuat sistem dapat diprediksi, mudah diaudit, dan lebih mudah diubah.
Simpan cap waktu yang menjelaskan status, seperti started_at, due_at, breached_at, dan field jeda seperti paused_at dan paused_reason. Juga simpan pelacakan eskalasi seperti last_escalation_level agar Anda tidak memberi notifikasi pada level yang sama dua kali.
Buat ladder kecil yang dimulai dari orang yang bisa bertindak, lalu eskalasikan ke lead, lalu manager hanya jika perlu. Simpan ambang dan penerima sebagai data (misalnya tabel kebijakan) sehingga perubahan waktu eskalasi tidak mengharuskan mengedit banyak workflow.
Hubungkan notifikasi ke transisi status seperti OK -> Warning atau Warning -> Breached, bukan ke pengecekan "masih lewat waktu". Tambahkan guardrail sederhana seperti cooldown dan kondisi berhenti sehingga Anda mengirim satu pesan per langkah bukan berulang kali setiap jadwal berjalan.
Gunakan pola events, satu evaluator, dan actions: events merekam fakta, evaluator menghitung tenggat dan menetapkan status SLA, dan actions bereaksi hanya pada perubahan status. Di AppMaster (appmaster.io), Anda dapat memodelkan data, membangun evaluator sebagai proses bisnis visual, dan memicu notifikasi atau penugasan dari pembaruan status sambil menjaga matematika waktu terpusat.



Eksperimen dengan AppMaster dengan paket gratis.
Saat Anda siap, Anda dapat memilih langganan yang tepat.


