Aplikasi pemesanan peralatan: cegah konflik dan lacak pengembalian
Rencanakan aplikasi pemesanan peralatan yang mencegah pemesanan ganda, mencatat pengembalian dan kerusakan, serta menahan item bermasalah untuk pemeliharaan.
Pelajari perubahan skema tanpa downtime dengan migrasi aditif, backfill aman, dan rollout bertahap yang menjaga klien lama tetap bekerja saat rilis.
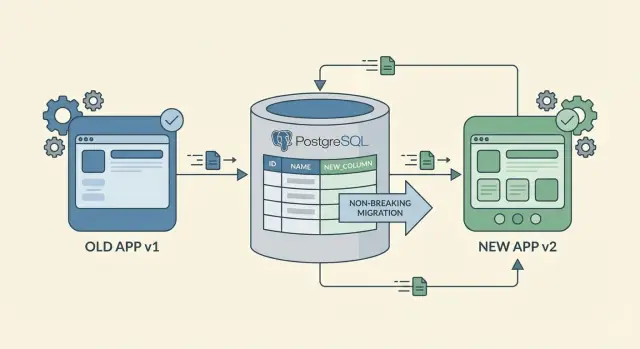
Perubahan skema tanpa downtime bukan berarti tidak ada yang berubah. Artinya pengguna bisa terus bekerja sementara Anda memperbarui database dan aplikasi, tanpa kegagalan atau alur kerja yang terblokir.
Downtime adalah setiap saat sistem Anda berhenti berperilaku normal. Itu bisa nampak sebagai error 500, timeout API, layar yang terbuka tapi menampilkan kosong atau nilai salah, job background yang crash, atau database yang menerima baca tetapi memblokir tulis karena migrasi panjang memegang lock.
Perubahan skema bisa merusak lebih dari sekadar UI utama. Titik kegagalan umum termasuk klien API yang mengharapkan bentuk respons lama, job background yang membaca atau menulis kolom tertentu, laporan yang langsung query tabel, integrasi pihak ketiga, dan skrip admin internal yang "bekerja baik kemarin."
Aplikasi mobile lama dan klien yang di-cache sering menjadi masalah karena Anda tidak bisa memperbarui semuanya sekaligus. Beberapa pengguna mempertahankan versi aplikasi selama berminggu-minggu. Yang lain punya konektivitas tidak stabil dan mengirim ulang permintaan lama nanti. Bahkan klien web bisa berperilaku seperti “versi lama” saat service worker, CDN, atau proxy cache menyimpan kode atau asumsi usang.
Tujuan sebenarnya bukan “satu migrasi besar yang selesai cepat.” Ini adalah rangkaian langkah kecil di mana setiap langkah bekerja sendiri, bahkan saat klien berbeda berada di versi yang berbeda.
Definisi praktis: Anda harus bisa mendeploy kode baru dan skema baru dalam urutan apa pun, dan sistem masih bekerja.
Pola pikir ini membantu Anda menghindari jebakan klasik: mendeploy aplikasi baru yang mengharapkan kolom baru sebelum kolom ada, atau menambahkan kolom baru yang kode lama tidak bisa tangani. Rencanakan perubahan agar bersifat aditif dulu, roll out bertahap, dan hapus jalur lama hanya setelah Anda yakin tidak ada yang menggunakannya.
Jalur paling aman menuju perubahan skema tanpa downtime adalah menambah, bukan mengganti. Menambah kolom atau tabel baru jarang merusak karena kode lama tetap bisa membaca dan menulis bentuk lama.
Rename dan penghapusan adalah langkah berisiko. Rename pada dasarnya adalah “tambah baru + hapus lama,” dan bagian “hapus lama” itulah yang membuat klien lama crash. Jika Anda perlu rename, perlakukan sebagai perubahan dua langkah: tambahkan field baru dulu, pertahankan field lama untuk sementara, dan hapus hanya setelah yakin tidak ada yang bergantung padanya.
Saat menambah kolom, mulailah dengan field yang nullable. Kolom nullable membiarkan kode lama tetap menyisipkan baris tanpa mengetahui kolom baru. Jika akhirnya Anda ingin NOT NULL, tambahkan sebagai nullable dulu, lakukan backfill, lalu terapkan NOT NULL di kemudian hari. Default juga bisa membantu, tetapi hati-hati: menambahkan default kadang menyentuh banyak baris di beberapa database, yang dapat memperlambat perubahan.
Index adalah tambahan yang “aman tapi tidak gratis.” Mereka bisa mempercepat pembacaan, tetapi membuat dan memelihara index dapat memperlambat penulisan. Tambahkan index ketika Anda tahu persis query mana yang akan menggunakannya, dan pertimbangkan rollout pada jam sepi jika database sibuk.
Aturan sederhana untuk migrasi database aditif:
Anggap perubahan skema tanpa downtime sebagai sebuah rollout, bukan satu deploy tunggal. Tujuannya membiarkan versi aplikasi lama dan baru berjalan berdampingan sementara database perlahan pindah ke bentuk baru.
Urutan praktis:
Contoh: Anda memperkenalkan full_name tetapi klien lama masih mengirim first_name dan last_name. Untuk sementara, backend bisa menyusun full_name saat menulis, backfill pengguna lama, lalu membaca full_name sebagai default sambil tetap mendukung payload lama. Hanya setelah adopsi jelas Anda drop field lama.
Backfill mengisi kolom atau tabel baru untuk baris yang sudah ada. Ini sering bagian paling berisiko dari perubahan skema tanpa downtime karena dapat menimbulkan beban database tinggi, lock panjang, dan perilaku “setengah ter-migrasi” yang membingungkan.
Mulailah dengan memilih bagaimana menjalankan backfill. Untuk dataset kecil, runbook manual satu kali bisa cukup. Untuk dataset besar, pilih worker background atau tugas terjadwal yang bisa berjalan berulang dan berhenti dengan aman.
Batch pekerjaan sehingga Anda mengendalikan tekanan ke database. Jangan update jutaan baris dalam satu transaksi. Targetkan ukuran chunk yang dapat diprediksi dan jeda singkat antar batch agar trafik pengguna normal tetap mulus.
Pola praktis:
Buat job dapat di-restart. Simpan penanda progres sederhana di tabel khusus, dan desain job sehingga menjalankan ulang tidak merusak data. Update idempotent (misalnya, update where new_field IS NULL) sangat membantu.
Validasi saat berjalan. Lacak berapa banyak baris yang masih kosong nilai barunya, dan tambahkan beberapa cek sanity. Contoh: tidak ada saldo negatif, timestamp dalam rentang yang diharapkan, status dalam himpunan yang diizinkan. Lakukan sampling untuk mengecek beberapa record nyata.
Putuskan apa yang aplikasi lakukan sementara backfill belum selesai. Opsi aman adalah fallback reads: jika field baru null, hitung atau baca nilai lama. Contoh: Anda menambah preferred_language. Sampai backfill selesai, API bisa mengembalikan bahasa dari pengaturan profil ketika preferred_language kosong, dan baru mulai mewajibkan field baru setelah selesai.
Saat Anda mengirim perubahan skema, jarang Anda mengontrol semua klien. Pengguna web memperbarui cepat, sementara build mobile lama bisa aktif berminggu-minggu. Itu sebabnya API yang kompatibel mundur penting meski migrasi database "aman."
Perlakukan data baru sebagai opsional pada awalnya. Tambahkan field baru ke request dan response, tetapi jangan mewajibkannya pada hari pertama. Jika klien lama tidak mengirim field baru, server tetap harus menerima request dan berperilaku seperti kemarin.
Hindari mengubah makna field yang ada. Rename field bisa aman jika Anda tetap menjaga nama lama bekerja juga. Menggunakan kembali field untuk makna baru adalah tempat munculnya kerusakan halus.
Default sisi server adalah jaring pengaman Anda. Saat memperkenalkan kolom baru seperti preferred_language, set default di server saat field hilang. Response API dapat menyertakan field baru, dan klien lama bisa mengabaikannya.
Aturan kompatibilitas yang mencegah sebagian besar outage:
Contoh: Anda menambah company_size pada flow signup. Backend dapat memberi default seperti "unknown" saat field hilang. Klien baru mengirim nilai nyata, klien lama tetap bekerja, dan dashboard tetap bisa dibaca.
Jika platform Anda meregenerasi aplikasi, Anda mendapatkan rebuild kode dan konfigurasi yang bersih. Itu membantu perubahan skema tanpa downtime karena Anda bisa melakukan langkah kecil, aditif, dan redeploy sering daripada membawa patch selama berbulan-bulan.
Kuncinya adalah satu sumber kebenaran. Jika skema database berubah di satu tempat dan logika bisnis berubah di tempat lain, drift cepat terjadi. Putuskan di mana perubahan didefinisikan, dan perlakukan semuanya sebagai output yang digenerasi.
Penamaan yang jelas mengurangi kecelakaan saat rollout bertahap. Jika Anda memperkenalkan field baru, buat jelas mana yang aman untuk klien lama dan mana yang jalur baru. Misalnya, menamai kolom status_v2 lebih aman daripada status_new karena masih masuk akal enam bulan kemudian.
Bahkan ketika perubahan aditif, rebuild bisa menyingkap coupling tersembunyi. Setelah setiap regenerasi dan deploy, periksa kembali beberapa flow kritis:
Rencanakan langkah migrasi sebelum membuka editor: tambahkan field baru, deploy dengan kedua field didukung, backfill, ganti pembacaan, lalu pensiunkan jalur lama nanti. Urutan itu menjaga skema, logika, dan kode yang digenerasi bergerak bersama sehingga perubahan tetap kecil, mudah direview, dan reversible.
Sebagian besar outage saat perubahan skema tanpa downtime bukan disebabkan kerja database yang “berat.” Mereka datang dari mengubah kontrak antara database, API, dan klien dengan urutan yang salah.
Jebakan umum dan langkah yang lebih aman:
Jika Anda meregenerasi aplikasi, tergoda untuk “membersihkan” nama dan constraint sekaligus. Tahan godaan itu. Pembersihan adalah langkah terakhir, bukan pertama.
Aturan bagus: jika sebuah perubahan tidak bisa di-roll forward dan di-roll back dengan aman, berarti belum siap untuk produksi.
Keberhasilan perubahan skema tanpa downtime bergantung pada dua hal: apa yang Anda pantau, dan seberapa cepat Anda bisa berhenti.
Lacak sinyal yang mencerminkan dampak pengguna nyata, bukan hanya “deploy selesai”:
Jika Anda melakukan dual writes (menulis ke kolom/ tabel lama dan baru), tambahkan logging sementara yang membandingkan keduanya. Jaga agar ketat: log hanya saat nilainya berbeda, sertakan ID record dan kode alasan singkat, dan sampling jika volume tinggi. Buat pengingat untuk menghapus logging ini setelah migrasi agar tidak jadi noise permanen.
Rollback harus realistis. Sebagian besar waktu, Anda tidak rollback skema. Anda rollback kode dan membiarkan skema aditif tetap.
Runbook rollback praktis:
Untuk backfill, buat tombol berhenti yang bisa Anda tekan dalam hitungan detik (feature flag, nilai konfigurasi, jeda job). Juga komunikasikan fase sebelumnya: kapan dual write mulai, kapan backfill berjalan, kapan pembacaan berganti, dan seperti apa “stop” sehingga tak ada improvisasi saat tekanan.
Tepat sebelum Anda kirim perubahan skema, jeda dan jalankan cek cepat ini. Ini menangkap asumsi kecil yang berubah menjadi outage saat ada versi klien campuran.
Jika Anda memakai platform yang meregenerasi, tambahkan satu cek lagi: generate dan deploy build dari model yang sedang dimigrasi, lalu konfirmasi API dan logika bisnis yang digenerasi masih mentolerir record lama. Kegagalan umum adalah mengasumsikan skema baru berarti logika baru wajib.
Tulis juga dua aksi cepat yang akan Anda ambil jika ada yang salah setelah deploy: apa yang akan Anda pantau (error, timeout, progres backfill) dan apa yang akan Anda rollback pertama (matikan feature flag, jeda backfill, revert rilis server). Itu mengubah “kami akan bereaksi cepat” menjadi rencana nyata.
Anda menjalankan aplikasi order. Anda butuh field baru, delivery_window, dan nanti akan diwajibkan untuk aturan bisnis baru. Masalahnya build iOS dan Android lama masih dipakai, dan mereka tidak akan mengirim field itu selama beberapa hari atau minggu. Jika Anda mewajibkan di database sekarang juga, klien-klien itu akan mulai gagal.
Jalur aman:
delivery_window untuk baris lama menggunakan aturan (infer dari metode pengiriman, atau default ke "anytime" sampai pelanggan mengeditnya).delivery_window terlebih dulu, tapi fallback ke nilai inferensi jika kosong.Apa yang dirasakan pengguna selama tiap fase tetap biasa saja (itu tujuannya):
Gerbang monitoring sederhana untuk tiap langkah: lacak persentase order baru dengan delivery_window non-null. Saat angka itu konsisten tinggi (dan error validasi "field hilang" hampir nol), biasanya aman pindah dari backfill ke penegakan constraint.
Rollout hati-hati sekali saja bukan strategi. Perlakukan perubahan skema seperti rutinitas: langkah sama, penamaan sama, sign-off sama. Maka perubahan aditif berikutnya tetap membosankan, bahkan saat aplikasi sibuk dan klien di versi berbeda.
Jaga playbook singkat. Harus menjawab: apa yang kita tambahkan, bagaimana kita mengirimnya dengan aman, dan kapan kita menghapus bagian lama.
Template sederhana:
Mulai dengan tabel berisiko rendah (status opsional baru, field catatan) dan jalankan playbook lengkap: perubahan aditif, backfill, klien versi campuran, lalu cleanup. Latihan ini memaparkan celah pada monitoring, batching, dan komunikasi sebelum Anda mencoba redesign besar.
Satu kebiasaan yang mencegah berantakan jangka panjang: catat item "hapus nanti" sebagai pekerjaan nyata. Saat Anda menambah kolom sementara, kode kompatibilitas, atau logika dual-write, buat tiket pembersihan segera dengan pemilik dan tanggal. Simpan catatan kecil "hutang kompatibilitas" di dokumen rilis supaya tetap terlihat.
Jika Anda membangun dengan AppMaster, Anda bisa memperlakukan regenerasi sebagai bagian dari proses keselamatan: modelkan skema aditif, perbarui logika bisnis untuk menangani kedua field selama transisi, dan regenerasi sehingga source code tetap bersih saat kebutuhan berubah. Jika Anda ingin melihat bagaimana alur kerja ini cocok dengan setup no-code yang tetap menghasilkan source code nyata, AppMaster (appmaster.io) dirancang di sekitar gaya pengiriman iteratif dan bertahap.
Tujuannya bukan kesempurnaan. Tujuannya adalah keterulangan: setiap migrasi punya rencana, ukuran, dan jalan keluar.
Zero-downtime berarti pengguna bisa terus bekerja seperti biasa sementara Anda mengubah skema dan mendeploy kode. Itu termasuk menghindari gangguan yang jelas, tetapi juga menghindari kegagalan diam-diam seperti layar kosong, nilai yang salah, job background yang crash, atau penulisan yang terblokir oleh lock migrasi yang lama.
Karena banyak bagian sistem bergantung pada bentuk database, bukan cuma UI utama. Job background, laporan, skrip admin, integrasi, dan aplikasi mobile lama bisa terus mengirim atau mengharapkan field lama jauh setelah Anda mendeploy kode baru.
Build mobile lama bisa tetap digunakan selama berminggu-minggu, dan beberapa klien melakukan retry permintaan lama nanti. API Anda perlu menerima payload lama dan baru untuk sementara waktu agar versi campuran bisa hidup berdampingan tanpa error.
Perubahan aditif biasanya tidak merusak kode yang sudah ada karena skema lama tetap ada. Rename dan penghapusan berisiko karena menghilangkan sesuatu yang masih dibaca atau ditulis oleh klien lama, yang menyebabkan crash atau permintaan gagal.
Tambahkan kolom sebagai nullable dulu agar kode lama tetap bisa memasukkan baris. Lakukan backfill pada baris lama secara bertahap, lalu setelah cakupan tinggi dan penulisan baru konsisten, baru terapkan NOT NULL sebagai langkah akhir.
Anggap ini sebagai sebuah rollout: tambahkan skema yang kompatibel, deploy kode yang mendukung keduanya, backfill dalam batch kecil, pindahkan pembacaan dengan fallback, dan hapus field lama hanya ketika Anda bisa membuktikan tidak ada lagi yang menggunakannya. Setiap langkah harus aman jika berjalan sendiri.
Jalankan dalam batch kecil dengan transaksi singkat agar tidak mengunci tabel atau menaikkan beban. Buat restartable dan idempotent dengan hanya mengupdate baris yang belum punya nilai baru, dan catat progres agar Anda bisa jeda dan melanjutkan dengan aman.
Buat field baru bersifat opsional dulu dan terapkan default di server saat field itu kosong. Pertahankan perilaku lama stabil, hindari mengubah makna field yang ada, dan uji kedua jalur: “klien baru mengirim” dan “klien lama menghilangkan field”.
Sebagian besar waktu Anda akan mengembalikan kode aplikasi, bukan skema. Biarkan kolom/tabel aditif tetap ada, matikan pembacaan baru terlebih dahulu, lalu matikan penulisan baru dan jeda backfill sampai metrik stabil sehingga Anda bisa pulih cepat tanpa kehilangan data.
Pantau sinyal yang berdampak pada pengguna: tingkat error API, query lambat (p95/p99) pada tabel yang disentuh, latensi penulisan, kedalaman antrean job, dan tekanan CPU/IO database setelah tiap fase. Lanjutkan ke langkah berikutnya hanya saat metrik stabil dan cakupan field baru tinggi, lalu jadwalkan pembersihan sebagai pekerjaan nyata.



Eksperimen dengan AppMaster dengan paket gratis.
Saat Anda siap, Anda dapat memilih langganan yang tepat.


