Aplikasi pemesanan peralatan: cegah konflik dan lacak pengembalian
Rencanakan aplikasi pemesanan peralatan yang mencegah pemesanan ganda, mencatat pengembalian dan kerusakan, serta menahan item bermasalah untuk pemeliharaan.
Pelajari desain hub integrasi untuk memusatkan kredensial, melacak status sinkron, dan menangani error secara konsisten saat tumpukan SaaS Anda berkembang ke banyak layanan.
Sebuah tumpukan SaaS seringkali mulai sederhana: satu CRM, satu alat penagihan, satu inbox support. Lalu tim menambahkan otomatisasi pemasaran, data warehouse, saluran support kedua, dan beberapa alat niche yang "hanya perlu sinkron cepat." Sebelum lama, Anda punya jaringan koneksi point-to-point yang tak seorang pun benar-benar memilikinya.
Yang pertama kali rusak biasanya bukan data. Melainkan lem-lem yang mengelilinginya.
Kredensial berakhir berserak di akun pribadi, spreadsheet bersama, dan variabel environment acak. Token kedaluwarsa, orang pergi, dan tiba-tiba "integrasi" bergantung pada login yang tak seorang pun dapat menemukan. Bahkan ketika keamanan ditangani dengan baik, rotasi secret jadi menyakitkan karena setiap koneksi punya pengaturan dan tempat pembaruan sendiri.
Visibilitas runtuh berikutnya. Setiap integrasi melaporkan status berbeda (atau bahkan tidak melaporkan). Satu alat mengatakan "terhubung" padahal diam-diam gagal sinkron. Yang lain mengirim email samar yang diabaikan. Ketika sales bertanya kenapa pelanggan tidak terprovisi, jawabannya berubah jadi perburuan barang di log, dashboard, dan thread chat.
Beban support naik cepat karena kegagalan sulit didiagnosa dan mudah terulang. Masalah kecil seperti batasan laju, perubahan skema, dan retry parsial berubah jadi insiden panjang ketika tak ada yang dapat melihat jalur lengkap dari "event terjadi" sampai "data sampai."
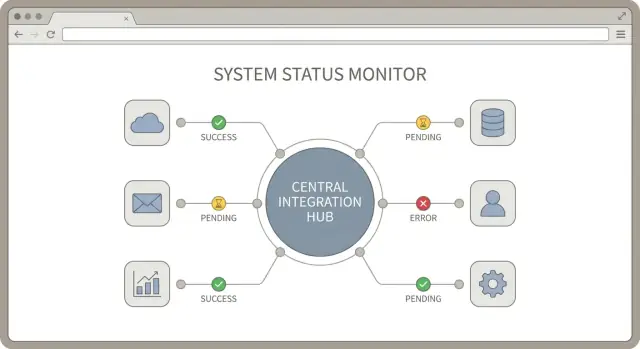
Integration hub adalah gagasan sederhana: satu tempat pusat di mana koneksi Anda ke layanan pihak ketiga dikelola, dimonitor, dan disupport. Desain hub integrasi yang baik menciptakan aturan konsisten tentang bagaimana integrasi mengautentikasi, bagaimana mereka melaporkan status sinkron, dan bagaimana error ditangani.
Hub yang praktis menargetkan empat hasil: lebih sedikit kegagalan (pola retry dan validasi bersama), perbaikan lebih cepat (penelusuran mudah), akses lebih aman (kepemilikan kredensial terpusat), dan beban support lebih rendah (alert dan pesan standar).
Jika Anda membangun tumpukan di platform seperti AppMaster, tujuannya sama: jaga operasi integrasi cukup sederhana sehingga non-spesialis bisa mengerti apa yang terjadi, dan spesialis bisa memperbaikinya cepat ketika tidak.
Sebelum membuat keputusan besar soal integrasi, dapatkan gambaran jelas tentang apa yang sudah Anda hubungkan (atau rencanakan untuk dihubungkan). Bagian ini seringkali dilewati orang, dan biasanya menimbulkan kejutan nanti.
Mulailah dengan mencantumkan setiap layanan pihak ketiga di tumpukan Anda, termasuk yang "kecil." Sertakan siapa pemiliknya (orang atau tim) dan apakah itu live, direncanakan, atau eksperimental.
Selanjutnya, pisahkan integrasi yang terlihat pelanggan dari otomatisasi latar belakang. Integrasi yang berhadapan dengan pengguna mungkin berupa "Hubungkan akun Salesforce Anda." Otomatisasi internal mungkin berupa "Saat invoice dibayar di Stripe, tandai pelanggan sebagai aktif di database." Keduanya punya ekspektasi keandalan yang berbeda, dan kegagalannya pun berbeda.
Lalu peta aliran data dengan satu pertanyaan: siapa yang membutuhkan data untuk melakukan pekerjaannya? Product mungkin butuh event penggunaan untuk onboarding. Ops perlu status akun dan provisioning. Finance perlu invoice, refund, dan field pajak. Support perlu tiket, riwayat percakapan, dan pencocokan identitas pengguna. Kebutuhan ini membentuk hub integrasi Anda lebih daripada API vendor.
Akhirnya, tetapkan ekspektasi waktu untuk setiap aliran:
Contoh: "Invoice terbayar" mungkin butuh near real time untuk kontrol akses, tapi harian untuk ringkasan finance. Tangkap itu sejak awal dan monitoring serta penanganan error jadi jauh lebih mudah distandarisasi.
Desain hub integrasi yang baik dimulai dengan batasan. Jika hub mencoba melakukan segalanya, ia menjadi bottleneck untuk setiap tim. Jika terlalu sedikit, Anda berakhir dengan selusin skrip one-off yang berperilaku berbeda-beda.
Tuliskan apa yang dimiliki hub dan apa yang tidak. Pemisahan praktis adalah:
Pilih satu entry point untuk semua integrasi dan patuhi itu. Entry point bisa berupa API (sistem lain memanggil hub) atau job runner (hub menjalankan pull/push terjadwal). Menggunakan keduanya tidak apa-apa, tetapi hanya jika keduanya berbagi pipeline internal yang sama sehingga retry, logging, dan alert berperilaku seragam.
Beberapa keputusan menjaga hub tetap fokus: standarkan bagaimana integrasi dipicu (webhook, jadwal, rerun manual), sepakati bentuk payload boundary (meskipun partner berbeda), putuskan apa yang dipertahankan (event mentah, record ternormalisasi, keduanya, atau tidak sama sekali), definisikan apa artinya "selesai" (diterima, dikirim, dikonfirmasi), dan tetapkan kepemilikan untuk keunikan partner.
Tentukan di mana transformasi terjadi. Jika Anda melakukan normalisasi data di hub, layanan downstream jadi lebih sederhana, tetapi hub membutuhkan versioning dan test yang lebih kuat. Jika Anda biarkan hub tipis dan meneruskan payload partner mentah, setiap layanan downstream harus mempelajari format setiap partner. Banyak tim memilih jalan tengah: normalisasi hanya field bersama (ID, timestamp, status dasar) dan aturan domain tetap di downstream.
Rencanakan multi-tenant sejak hari pertama. Putuskan apakah unit isolasi adalah customer, workspace, atau org. Pilihan itu memengaruhi rate limit, penyimpanan kredensial, dan backfill. Ketika token Salesforce satu pelanggan kedaluwarsa, Anda harus menjeda hanya job tenant itu, bukan seluruh pipeline. Tools seperti AppMaster dapat membantu memodelkan tenant dan workflow secara visual, tetapi batas-batas itu tetap harus eksplisit sebelum membangun.
Vault kredensial bisa membuat hidup tenang atau berubah menjadi risiko insiden permanen. Tujuannya sederhana: satu tempat menyimpan akses, tanpa memberi setiap sistem dan rekan lebih banyak wewenang daripada yang mereka butuhkan.
OAuth dan API key muncul di tempat berbeda. OAuth umum untuk aplikasi berhadapan pengguna seperti Google, Slack, Microsoft, dan banyak CRM. Pengguna memberi izin, dan Anda menyimpan access token plus refresh token. API key lebih umum untuk alat server-to-server dan API lama. Mereka bisa berlaku lama, sehingga penyimpanan aman dan rotasi jadi lebih penting.
Simpan semua terenkripsi dan skopkan ke tenant yang tepat. Dalam produk multi-pelanggan, perlakukan kredensial sebagai data pelanggan. Jaga isolasi ketat sehingga token Tenant A tidak pernah bisa dipakai untuk Tenant B, bahkan secara tidak sengaja. Simpan juga metadata yang Anda perlukan nanti, seperti koneksi mana yang terkait, kapan kedaluwarsa, dan izin apa yang diberikan.
Aturan praktis yang mencegah sebagian besar masalah:
Rencanakan refresh dan revocation tanpa memutus sinkron. Untuk OAuth, refresh harus terjadi otomatis di background, dan hub Anda harus menangani "token expired" dengan melakukan refresh sekali dan retry dengan aman. Untuk revocation (pengguna memutus, tim keamanan menonaktifkan app, atau scope berubah), hentikan sinkron, tandai koneksi sebagai needs_auth, dan simpan jejak audit yang jelas.
Jika Anda membangun hub di AppMaster, perlakukan kredensial sebagai model data terlindungi, simpan akses di logika backend-only, dan tampilkan hanya status connected/disconnected ke UI. Operator dapat memperbaiki koneksi tanpa pernah melihat secret.
Saat Anda menghubungkan banyak alat, "apakah ini bekerja?" menjadi pertanyaan harian. Solusinya bukan log lebih banyak. Melainkan sekumpulan sinyal sinkron kecil dan konsisten yang terlihat sama untuk setiap integrasi. Desain hub yang baik memperlakukan status sebagai fitur kelas satu.
Mulailah dengan mendefinisikan daftar pendek state koneksi dan gunakan di mana-mana: di UI admin, di alert, dan di catatan support. Gunakan nama yang sederhana agar rekan non-teknis bisa bertindak.
Lacak tiga timestamp per koneksi: terakhir mulai sinkron, terakhir sinkron sukses, dan waktu error terakhir. Mereka menceritakan kondisi secara cepat tanpa perlu menggali lebih dalam.
Tampilan per-integrasi kecil membantu tim support bergerak cepat. Setiap halaman koneksi harus menunjukkan state saat ini, timestamp tersebut, dan pesan error terakhir dalam format yang bersih dan ramah pengguna (tanpa stack trace). Tambahkan satu baris rekomendasi tindakan singkat seperti "Re-auth required" atau "Rate limit, retrying."
Tambahkan beberapa sinyal kesehatan yang memprediksi masalah sebelum pengguna menyadarinya: ukuran backlog, hitungan retry, hit rate limit, dan throughput sukses terakhir (perkiraan berapa item yang tersinkron tiap run).
Contoh: sinkron CRM Anda terhubung, tetapi backlog meningkat dan hit rate limit melonjak. Itu belum outage, tapi tanda jelas untuk mengurangi frekuensi sinkron atau batch request. Jika Anda membangun hub di AppMaster, field status ini mudah dipetakan ke model Data Designer dan UI dashboard support sederhana yang tim Anda bisa gunakan sehari-hari.
Sinkron yang andal lebih soal langkah yang dapat diulang daripada logika rumit. Mulailah dengan satu model eksekusi jelas, lalu tambahkan kompleksitas hanya bila perlu.
Sebagian besar tim menggunakan campuran, tapi setiap konektor harus punya trigger utama agar mudah ditelusuri:
Jika Anda membangun di AppMaster, ini sering dipetakan ke endpoint webhook, proses background, dan tugas terjadwal, semuanya memberi makan pipeline internal yang sama.
Vendor berbeda memberi nama hal yang sama dengan cara berbeda (customerId vs contact_id, string status, format tanggal). Konversi setiap payload masuk ke satu format internal sebelum menerapkan aturan bisnis. Ini membuat sisa hub lebih sederhana dan perubahan connector jadi tidak menyakitkan.
Retry itu normal. Hub Anda harus mampu menjalankan aksi yang sama dua kali tanpa membuat duplikat. Pendekatan umum adalah menyimpan external ID dan "last processed version" (timestamp, sequence number, atau event ID). Jika item yang sama muncul lagi, Anda skip atau update dengan aman.
API pihak ketiga bisa lambat atau macet. Masukkan tugas ter-normalisasi ke antrean tahan lama, lalu proses dengan timeout eksplisit. Jika panggilan memakan waktu terlalu lama, anggap gagal, catat alasannya, dan retry nanti daripada memblokir semuanya.
Tangani limit dengan backoff dan throttling per-connector. Back off pada respon 429/5xx dengan jadwal retry yang dibatasi, tetapkan batas concurrency terpisah per konektor (CRM bukan billing), dan tambahkan jitter untuk menghindari lonjakan retry bersamaan.
Contoh: sebuah "invoice baru terbayar" datang dari billing lewat webhook, dinormalisasi dan masuk antrean, lalu membuat atau memperbarui akun yang sesuai di CRM Anda. Jika CRM membatasi laju, konektor itu melambat tanpa menunda sinkron tiket support.
Hub yang "kadang gagal" lebih buruk daripada tidak punya hub. Solusinya adalah cara bersama untuk mendeskripsikan error, memutuskan langkah selanjutnya, dan memberi tahu admin non-teknis apa yang harus dilakukan.
Mulailah dengan bentuk error standar yang dikembalikan setiap konektor, meskipun payload pihak ketiga berbeda. Itu menjaga UI, alert, dan playbook support konsisten.
RATE_LIMIT)Lalu klasifikasikan kegagalan ke beberapa bucket (jaga tetap kecil): auth, validation, timeout, rate limit, dan outage.
Lampirkan aturan retry yang jelas ke tiap bucket. Rate limit dapat retry tertunda dengan backoff. Timeout dapat retry cepat dengan jumlah terbatas. Validation butuh penanganan manual sampai data diperbaiki. Auth menjeda integrasi dan meminta admin untuk reconnect.
Simpan respon mentah pihak ketiga, tetapi simpan dengan aman. Redaksi secret (token, API key, data kartu penuh) sebelum menyimpan. Jika itu bisa memberi akses, tidak layak masuk log.
Tulis dua pesan per error: satu untuk admin dan satu untuk engineer. Pesan admin bisa: "Salesforce connection expired. Reconnect to resume syncing." Tampilan engineer dapat menyertakan respon tersanitasi, request ID, dan langkah yang gagal. Di sinilah konsistensi hub membayar, apakah Anda mengimplementasikan flow dalam kode atau dengan alat visual seperti Business Process Editor AppMaster.
Banyak proyek integrasi gagal karena alasan yang membosankan. Hub bekerja di demo, lalu runtuh saat Anda menambah lebih banyak tenant, tipe data, dan edge case.
Satu perangkap besar adalah mencampur logika koneksi dengan logika bisnis. Ketika "cara bicara ke API" berada di jalur kode yang sama dengan "apa arti record pelanggan," setiap aturan baru berisiko merusak konektor. Jaga adapter fokus pada auth, paging, rate limit, dan mapping. Letakkan aturan bisnis di lapisan terpisah yang bisa diuji tanpa memanggil API pihak ketiga.
Masalah umum lain adalah menganggap state tenant bersifat global. Di produk B2B, setiap tenant butuh token, cursor, dan checkpoint sinkron sendiri. Jika Anda menyimpan "last sync time" di satu tempat bersama, satu pelanggan bisa menimpa yang lain dan Anda kehilangan update atau terjadi kebocoran data antar-tenant.
Lima perangkap yang sering muncul, plus perbaikan sederhana:
Retry perlu perhatian khusus. Jika panggilan create timeout, retry bisa membuat duplikat kecuali Anda gunakan idempotency key atau strategi upsert kuat. Jika API pihak ketiga tidak mendukung idempotency, pantau ledger penulisan lokal sehingga Anda bisa mendeteksi dan menghindari penulisan berulang.
Jangan lewatkan audit log. Ketika support bertanya kenapa record hilang, Anda perlu jawaban dalam menit, bukan tebakan. Bahkan jika Anda membangun hub dengan alat visual seperti AppMaster, jadikan log dan state per-tenant prioritas.
Hub integrasi yang baik membosankan dengan cara terbaik: menghubungkan, melaporkan kesehatannya dengan jelas, dan gagal dengan cara yang bisa dimengerti tim Anda.
Mulailah dengan memeriksa bagaimana setiap integrasi mengautentikasi dan apa yang Anda lakukan dengan kredensial itu. Minta seperangkat izin sekecil mungkin yang masih memungkinkan job berjalan (read-only bila memungkinkan). Simpan secret di secret store khusus atau vault terenkripsi dan rotasi tanpa mengubah kode. Pastikan log dan pesan error tidak pernah memuat token, API key, refresh token, atau header mentah.
Setelah kredensial aman, pastikan setiap koneksi pelanggan punya satu sumber kebenaran yang jelas.
Kejelasan operasional menjaga integrasi tetap dapat dikelola ketika Anda memiliki puluhan pelanggan dan banyak layanan pihak ketiga.
Lacak state koneksi per pelanggan (terhubung, perlu otentikasi, dijeda, gagal) dan tampilkan di UI admin. Catat timestamp sinkron sukses terakhir per objek atau per job sinkron, bukan hanya "kami menjalankan sesuatu kemarin." Buat error terakhir mudah ditemukan dengan konteks: pelanggan mana, integrasi mana, langkah mana, request eksternal mana, dan apa yang terjadi selanjutnya.
Batasi retry (maks percobaan dan jendela cutoff), dan desain penulisan agar idempotent sehingga rerun tidak membuat duplikat. Tetapkan target support: seseorang di tim harus bisa menemukan kegagalan terbaru dan detailnya dalam waktu kurang dari dua menit tanpa membaca kode.
Jika Anda membangun UI hub dan pelacakan status cepat, platform seperti AppMaster dapat membantu mengirim dashboard internal dan logika workflow dengan cepat sambil tetap menghasilkan kode produksi.
Bayangkan sebuah produk SaaS yang membutuhkan tiga integrasi umum: Stripe untuk event billing, HubSpot untuk handoff sales, dan Zendesk untuk tiket support. Alih-alih menghubungkan tiap alat langsung ke aplikasi, lewatkan semuanya melalui satu integration hub.
Onboarding dimulai di panel admin. Seorang admin klik "Connect Stripe", "Connect HubSpot", dan "Connect Zendesk". Setiap konektor menyimpan kredensial di hub, bukan di skrip acak atau laptop karyawan. Lalu hub menjalankan import awal:
Setelah import, sinkron pertama dimulai. Hub menulis record sinkron untuk setiap konektor sehingga semua orang melihat cerita yang sama. Tampilan admin sederhana menjawab sebagian besar pertanyaan: state koneksi, waktu sinkron sukses terakhir, job saat ini (importing, syncing, idle), ringkasan error dan kode, dan run terjadwal berikutnya.
Sekarang jam sibuk dan Stripe memberi rate limit pada panggilan API Anda. Alih-alih membuat seluruh sistem gagal, konektor Stripe menandai job sebagai retrying, menyimpan progres parsial (mis. "invoices sampai 10:40"), dan back off. HubSpot dan Zendesk terus sinkron.
Support mendapat tiket: "Billing terlihat ketinggalan." Mereka membuka hub dan melihat Stripe dalam kondisi gagal dengan error rate limit. Resolusinya prosedural:
Jika Anda membangun di platform seperti AppMaster, alur ini mudah dipetakan ke logika visual (state job, retry, layar admin) sambil tetap menghasilkan kode backend nyata untuk produksi.
Desain hub integrasi yang baik kurang tentang membangun semuanya sekaligus dan lebih tentang membuat setiap koneksi baru dapat diprediksi. Mulailah dengan seperangkat aturan bersama yang harus diikuti setiap konektor, meskipun versi pertama terasa "terlalu sederhana."
Mulailah dengan konsistensi: state singkat untuk job sinkron (pending, running, succeeded, failed), kategori error pendek (auth, rate limit, validation, upstream outage, unknown), dan log audit yang menjawab siapa menjalankan apa, kapan, dan dengan record mana. Jika Anda tidak bisa mempercayai status dan log, dashboard dan alert hanya akan membuat kebisingan.
Tambah konektor satu per satu menggunakan template dan konvensi yang sama. Setiap konektor harus menggunakan alur kredensial yang sama, aturan retry yang sama, dan cara yang sama untuk menulis update status. Pengulangan itulah yang menjaga hub bisa disupport ketika jumlah integrasi bertambah dari tiga menjadi sepuluh.
Rencana rollout praktis:
Perkenalkan dashboard dan alert hanya setelah data status dasar benar. Mulailah dengan satu layar yang menunjukkan waktu sinkron terakhir, hasil terakhir, run berikutnya, dan pesan error terbaru dengan kategori.
Jika Anda lebih suka pendekatan no-code, Anda dapat memodelkan data, membangun logika sinkron, dan menampilkan layar status di AppMaster, lalu deploy ke cloud Anda atau ekspor source code. Jaga versi pertama tetap membosankan dan dapat diamati, lalu perbaiki performa dan edge case setelah operasi stabil.
Mulailah dengan inventaris sederhana: daftar semua alat pihak ketiga, siapa yang bertanggung jawab, dan apakah alat itu aktif atau masih direncanakan. Lalu tuliskan data apa yang mengalir antar sistem dan mengapa itu penting bagi tiap tim (support, finance, ops). Peta ini akan menunjukkan mana yang butuh perilaku real-time, mana yang bisa dijalankan harian, dan mana yang perlu pemantauan paling ketat.
Miliki plumbing bersama: setup koneksi, penyimpanan kredensial, penjadwalan/trigger, pelaporan status konsisten, dan penanganan error yang seragam. Biarkan keputusan bisnis berada di luar hub supaya Anda tidak perlu mengubah kode konektor setiap kali aturan produk berubah. Batas ini menjaga hub tetap berguna tanpa jadi hambatan.
Gunakan satu entry point utama per konektor agar mudah menelusuri penyebab kegagalan. Webhook cocok bila Anda butuh pembaruan near real time, scheduled pulls untuk penyedia yang tidak bisa melakukan push, dan job-style untuk alur yang harus berjalan berurutan. Apa pun yang dipilih, pastikan retry, logging, dan update status seragam di semua trigger.
Perlakukan kredensial sebagai data pelanggan: simpan terenkripsi dengan isolasi tenant yang ketat. Jangan tampilkan token di log, UI, atau screenshot support, dan jangan pakai ulang secret produksi di staging. Simpan juga metadata yang diperlukan untuk operasi aman, seperti waktu kedaluwarsa, scope, dan tenant/koneksi yang terkait.
OAuth ideal untuk pelanggan yang menghubungkan akun mereka sendiri dan Anda butuh akses yang bisa dicabut dengan scope. API key lebih sederhana untuk server-to-server tetapi seringnya berumur panjang, jadi rotasi dan kontrol akses menjadi penting. Jika bisa memilih, gunakan OAuth untuk koneksi user-facing dan batasi serta rotasi key untuk integrasi server-to-server.
Simpan state tenant terpisah untuk segala hal: token, cursor, checkpoint, hitungan retry, dan progres backfill. Kegagalan satu tenant harus menjeda hanya job tenant itu, bukan seluruh konektor. Isolasi ini mencegah kebocoran data antar-tenant dan mempermudah penanganan masalah.
Gunakan beberapa state sederhana di semua konektor, misalnya terhubung, perlu otentikasi, dijeda, dan gagal. Rekam tiga timestamp per koneksi: mulai sinkron terakhir, sinkron sukses terakhir, dan waktu error terakhir. Dengan sinyal ini, sebagian besar pertanyaan “apakah ini bekerja?” bisa dijawab tanpa membuka log.
Jadikan setiap penulisan idempotent sehingga retry tidak menghasilkan duplikat. Biasanya ini berarti menyimpan external object ID plus penanda “last processed” dan melakukan upsert bukan create buta. Jika penyedia tidak mendukung idempotency, simpan ledger lokal untuk mendeteksi upaya penulisan berulang sebelum menulis lagi.
Tangani rate limit secara sengaja: batasi per konektor, backoff pada 429 dan error transient, dan tambahkan jitter agar retry tidak menumpuk bersamaan. Tempatkan pekerjaan di antrean tahan lama dengan timeouts sehingga API yang lambat tidak memblokir integrasi lain. Tujuannya adalah memperlambat satu konektor tanpa membuat seluruh hub terhenti.
Untuk pendekatan tanpa kode, modelkan koneksi, tenant, dan field status di Data Designer AppMaster, lalu implementasikan workflow sinkronisasi di Business Process Editor. Simpan kredensial di logika backend saja dan tampilkan hanya status aman serta prompt tindakan di UI. Anda bisa mengirimkan dashboard operasi internal dengan cepat dan tetap mengekspor kode produksi.



Eksperimen dengan AppMaster dengan paket gratis.
Saat Anda siap, Anda dapat memilih langganan yang tepat.


