Aplikasi pemesanan peralatan: cegah konflik dan lacak pengembalian
Rencanakan aplikasi pemesanan peralatan yang mencegah pemesanan ganda, mencatat pengembalian dan kerusakan, serta menahan item bermasalah untuk pemeliharaan.
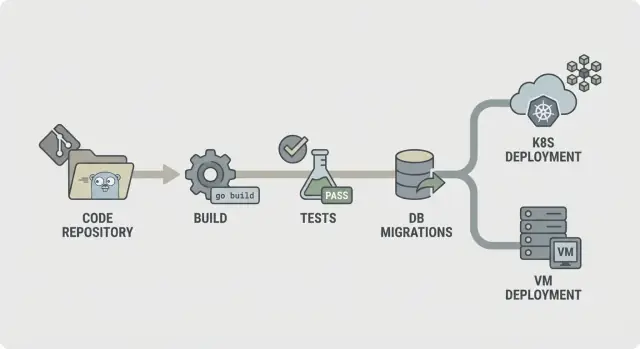
CI/CD untuk backend Go: langkah pipeline praktis untuk build, test, migrasi, dan deploy aman ke Kubernetes atau VM dengan lingkungan yang dapat diprediksi.
Deploy manual gagal dengan cara yang membosankan dan berulang. Seseorang membangun di laptop dengan versi Go berbeda, lupa variabel lingkungan, melewatkan migrasi, atau me-restart service yang salah. Rilis “berfungsi di mesin saya”, tapi tidak di produksi, dan Anda baru tahu setelah pengguna merasakannya.
Kode yang dihasilkan tidak menghapus kebutuhan disiplin rilis. Saat Anda meregenerasi backend setelah memperbarui kebutuhan, Anda bisa memperkenalkan endpoint baru, bentuk data baru, atau dependensi baru bahkan jika Anda tidak pernah menyentuh kode secara manual. Itu tepat saat Anda ingin pipeline menjadi pagar pengaman: setiap perubahan melewati pemeriksaan yang sama, setiap waktu.
Lingkungan yang dapat diprediksi berarti langkah build dan deploy berjalan dalam kondisi yang dapat Anda beri nama dan ulangi. Beberapa aturan menutupi sebagian besar masalah:
Tujuan CI/CD untuk backend Go bukan otomatisasi demi otomatisasi. Ini tentang rilis yang dapat diulang dengan lebih sedikit stres: regenerasi, jalankan pipeline, dan percaya bahwa apa yang keluar bisa dideploy.
Jika Anda menggunakan generator seperti AppMaster yang menghasilkan backend Go, ini menjadi lebih penting. Regenerasi adalah fitur, tetapi itu hanya terasa aman ketika jalur dari perubahan ke produksi konsisten, teruji, dan dapat diprediksi.
“Dapat diprediksi” berarti input yang sama menghasilkan hasil yang sama, tidak peduli di mana Anda menjalankannya. Untuk CI/CD backend Go, itu dimulai dengan menyepakati apa yang harus identik di dev, staging, dan prod.
Hal yang biasanya tidak boleh berubah: versi Go, base OS image, build flags, dan bagaimana konfigurasi dimuat. Jika salah satu berubah antar lingkungan, Anda akan mendapatkan kejutan seperti perilaku TLS berbeda, paket sistem yang hilang, atau bug yang hanya muncul di produksi.
Sebagian besar drift lingkungan muncul di tempat yang sama:
Memilih antara Kubernetes dan VM lebih soal apa yang tim Anda bisa jalankan dengan tenang.
Kubernetes cocok saat Anda butuh autoscaling, rolling updates, dan cara standar menjalankan banyak layanan. Ia juga membantu menegakkan konsistensi karena pod berjalan dari image yang sama. VM bisa tepat saat Anda hanya punya satu atau beberapa layanan, tim kecil, dan ingin lebih sedikit bagian yang bergerak.
Anda dapat mempertahankan pipeline yang sama meskipun runtime berbeda dengan menstandarisasi artefak dan kontraknya. Contohnya: selalu build image container yang sama di CI, jalankan langkah pengujian yang sama, dan publish bundle migrasi yang sama. Setelah itu hanya langkah deploy yang berubah: Kubernetes menerapkan tag image baru, sedangkan VM menarik image dan me-restart service.
Contoh praktis: sebuah tim meregenerasi backend Go dari AppMaster dan deploy ke staging di Kubernetes tetapi menggunakan VM di produksi untuk sekarang. Jika keduanya menarik image yang persis sama dan memuat konfigurasi dari jenis secret store yang sama, “runtime berbeda” menjadi detail deploy, bukan sumber bug. Jika Anda menggunakan AppMaster (appmaster.io), model ini juga cocok karena Anda bisa deploy ke target cloud yang dikelola atau mengekspor source code dan menjalankan pipeline yang sama di infrastruktur sendiri.
Pipeline yang dapat diprediksi mudah dijelaskan: periksa kode, build, buktikan bekerja, kirim hal yang sama yang Anda uji, lalu deploy dengan cara yang sama setiap kali. Kejelasan itu lebih penting ketika backend Anda diregenerasi (misalnya dari AppMaster), karena perubahan bisa menyentuh banyak file sekaligus dan Anda ingin umpan balik yang cepat dan konsisten.
Alur CI/CD sederhana untuk backend Go terlihat seperti ini:
Strukturkan agar kegagalan berhenti lebih awal. Jika lint gagal, langkah lain tidak boleh berjalan. Jika build gagal, Anda tidak perlu membuang waktu memulai database untuk integration checks. Ini menekan biaya dan membuat pipeline terasa cepat.
Tidak setiap langkah harus berjalan di setiap commit. Pembagian umum:
Putuskan apa yang Anda simpan sebagai artefak. Biasanya itu binary terkompilasi atau image container (yang Anda deploy), plus log migrasi dan laporan test. Menyimpan ini mempermudah rollback dan audit karena Anda bisa menunjuk persis apa yang diuji dan dipromosikan.
Stage build harus menjawab satu pertanyaan: bisakah kita menghasilkan binary yang sama hari ini, besok, dan di runner yang berbeda. Jika itu tidak benar, setiap langkah selanjutnya (test, migrasi, deploy) menjadi sulit dipercaya.
Mulailah dengan pin environment. Gunakan versi Go tetap (misalnya 1.22.x) dan runner image tetap (distro Linux dan versi paket). Hindari tag “latest”. Perubahan kecil di libc, Git, atau toolchain Go bisa menciptakan kegagalan “works on my machine” yang menyakitkan untuk di-debug.
Caching module membantu, tetapi hanya ketika Anda menganggapnya sebagai peningkatan kecepatan, bukan sumber kebenaran. Cache Go build cache dan module download cache, tetapi beri kunci berdasarkan go.sum (atau bersihkan saat main ketika dep berubah) sehingga dependensi baru selalu memicu download bersih.
Tambahkan gerbang cepat sebelum kompilasi. Buat agar cepat supaya pengembang tidak melewatinya. Set tipikalnya adalah pemeriksaan gofmt, go vet, dan (jika tetap cepat) staticcheck. Juga gagalkan jika file yang dihasilkan hilang atau ketinggalan, yang sering terjadi di codebase yang diregenerasi.
Kompilasi secara reproducible dan sematkan info versi. Flag seperti -trimpath membantu, dan Anda bisa set -ldflags untuk menyisipkan commit SHA dan waktu build. Hasilkan satu artefak bernama per service. Itu memudahkan melacak apa yang berjalan di Kubernetes atau di VM, terutama saat backend Anda diregenerasi.
Test hanya membantu jika berjalan dengan cara yang sama setiap kali. Utamakan umpan balik cepat terlebih dulu, lalu tambahkan pemeriksaan lebih dalam yang tetap selesai dalam waktu yang dapat diprediksi.
Mulailah dengan unit tests pada setiap commit. Tetapkan timeout keras sehingga test yang macet gagal keras alih-alih menggantung seluruh pipeline. Juga putuskan apa arti “cukup” untuk cakupan (coverage) bagi tim Anda. Coverage bukan trofi, tetapi ambang minimum membantu mencegah penurunan kualitas pelan-pelan.
Stage test yang stabil biasanya meliputi:
go test ./... dengan timeout per-paket dan timeout job global.Race detector berharga, tetapi bisa memperlambat build cukup banyak. Kompromi yang baik adalah menjalankannya pada pull request dan build nightly, atau hanya pada paket terpilih, bukan setiap push.
Test yang flaky harus membuat build gagal. Jika Anda harus mengkarantina test, tetap terlihat: pindahkan ke job terpisah yang tetap berjalan dan melaporkan merah, dan minta pemilik serta tenggat untuk memperbaikinya.
Simpan output test agar debug tidak memerlukan jalankan ulang segalanya. Simpan log mentah plus laporan sederhana (pass/fail, durasi, dan test lambat teratas). Itu memudahkan menemukan regresi, terutama saat perubahan regenerasi menyentuh banyak file.
Unit test memberi tahu kode Anda bekerja terisolasi. Integration checks memberi tahu layanan berperilaku benar saat boot, terhubung ke layanan nyata, dan menangani request nyata. Ini adalah jaring pengaman yang menangkap masalah yang hanya muncul ketika semuanya terhubung.
Gunakan dependensi ephemeral ketika kode Anda membutuhkannya untuk start atau menjawab request kunci. PostgreSQL sementara (dan Redis jika digunakan) yang diputar hanya untuk job biasanya cukup. Pertahankan versinya dekat dengan produksi, tetapi jangan mencoba menyalin setiap detail produksi.
Stage integrasi yang baik kecil dengan sengaja:
Untuk pengecekan kontrak API, fokus pada endpoint yang paling berbahaya jika rusak. Anda tidak perlu suite end-to-end lengkap. Beberapa kebenaran request/response cukup: field wajib ditolak dengan 400, auth yang dibutuhkan mengembalikan 401, dan jalur bahagia mengembalikan 200 dengan kunci JSON yang diharapkan.
Untuk menjaga integrasi tetap cepat dijalankan sering, batasi cakupan dan kontrol waktu. Pilih satu database dengan dataset kecil. Jalankan hanya beberapa request. Tetapkan timeout keras sehingga boot yang macet gagal dalam hitungan detik, bukan menit.
Jika Anda meregenerasi backend (misalnya dengan AppMaster), pemeriksaan ini punya bobot ekstra. Mereka mengkonfirmasi layanan yang diregenerasi masih start bersih dan masih berbicara API yang diharapkan oleh web atau mobile app Anda.
Mulailah dengan memilih di mana migrasi dijalankan. Menjalankannya di CI bagus untuk mendeteksi kesalahan lebih awal, tetapi CI biasanya tidak seharusnya menyentuh produksi. Sebagian besar tim menjalankan migrasi saat deploy (sebagai langkah terpisah) atau sebagai job “migrate” yang harus selesai sebelum versi baru dimulai.
Aturan praktis: build dan test di CI, lalu jalankan migrasi sedekat mungkin dengan produksi, dengan kredensial produksi dan batasan mirip produksi. Di Kubernetes, itu sering berupa Job satu-kali. Di VM, bisa berupa perintah ter-skrip di langkah rilis.
Urutan lebih penting dari yang diperkirakan orang. Gunakan file timestamp (atau nomor berurutan) dan tegakkan “apply berurutan, tepat sekali.” Buat migrasi idempoten bila memungkinkan, sehingga retry tidak membuat duplikasi atau crash di tengah jalan.
Sederhanakan strategi migrasi:
Tambahkan gate pengaman sebelum apa pun dijalankan. Ini bisa berupa kunci database sehingga hanya satu migrasi berjalan sekaligus, plus kebijakan seperti “tidak ada perubahan destruktif tanpa persetujuan.” Misalnya, gagalkan pipeline jika migrasi berisi DROP TABLE atau DROP COLUMN kecuali gate manual disetujui.
Rollback adalah kenyataan pahit: banyak perubahan skema tidak dapat dibalik. Jika Anda drop column, Anda tidak bisa mengembalikan datanya. Rencanakan rollback di sekitar perbaikan maju: simpan down migration hanya jika benar-benar aman, dan andalkan backup plus migrasi maju ketika tidak aman.
Pasangkan setiap migrasi dengan rencana pemulihan: apa yang dilakukan jika gagal di tengah, dan apa yang dilakukan jika aplikasi perlu rollback. Jika Anda menghasilkan backend Go (misalnya dengan AppMaster), anggap migrasi sebagai bagian dari kontrak rilis sehingga kode yang diregenerasi dan skema tetap sinkron.
Pipeline terasa dapat diprediksi ketika hal yang Anda deploy selalu sama dengan yang Anda uji. Itu bergantung pada packaging dan konfigurasi. Perlakukan output build sebagai artefak tersegel dan simpan semua perbedaan lingkungan di luarnya.
Packaging biasanya berarti salah satu dari dua jalur. Image container adalah default jika Anda deploy ke Kubernetes, karena mengunci lapisan OS dan membuat rollout konsisten. Bundle VM bisa sama andal ketika Anda butuh VM, selama ia menyertakan binary terkompilasi plus set file kecil yang dibutuhkan saat runtime (misalnya: CA cert, template, atau aset statis), dan Anda mendeploynya dengan cara yang sama setiap kali.
Konfigurasi harus eksternal, bukan dibakar ke dalam binary. Gunakan environment variables untuk sebagian besar pengaturan (port, host DB, feature flag). Gunakan file konfigurasi hanya ketika nilai panjang atau terstruktur, dan jaga agar itu spesifik lingkungan. Jika Anda menggunakan config service, anggap itu dependency: izin terkunci, log audit, dan rencana fallback yang jelas.
Secret adalah garis yang tidak boleh dilanggar. Mereka tidak masuk repo, image, atau log CI. Hindari mencetak connection string saat startup. Simpan secret di secret store CI Anda dan suntikkan saat deploy.
Untuk membuat artefak dapat ditelusuri, sematkan identitas ke setiap build: tag artefak dengan versi plus commit hash, sertakan metadata build (versi, commit, waktu build) di endpoint info, dan catat tag artefak di log deploy. Buat mudah menjawab “apa yang berjalan” dari satu perintah atau dashboard.
Jika Anda menghasilkan backend Go (misalnya dengan AppMaster), disiplin ini lebih penting: regenerasi aman ketika penamaan artefak dan aturan konfigurasi membuat setiap rilis mudah direproduksi.
Sebagian besar kegagalan deploy bukan karena “kode jelek”. Mereka akibat lingkungan yang tidak cocok: konfigurasi berbeda, secret hilang, atau service yang start tapi sebenarnya tidak siap. Tujuannya sederhana: deploy artefak yang sama ke mana pun, dan ubah hanya konfigurasi.
Di Kubernetes, tujuannya rollout terkendali. Gunakan rolling updates sehingga Anda mengganti pod secara bertahap, dan tambahkan readiness serta liveness checks sehingga platform tahu kapan mengirim traffic dan kapan merestart container yang macet. Resource requests dan limits juga penting, karena service Go yang bekerja di runner CI besar bisa OOM-killed di node kecil.
Pertahankan konfigurasi dan secret di luar image. Build satu image per commit, lalu suntikkan pengaturan spesifik lingkungan saat deploy (ConfigMaps, Secrets, atau secret manager Anda). Dengan begitu, staging dan production menjalankan bit yang sama.
Jika Anda deploy ke virtual machine, systemd bisa menjadi “mini orchestrator” Anda. Buat unit file dengan working directory jelas, file environment, dan kebijakan restart. Buat log prediktabel dengan mengirim stdout/stderr ke log collector atau journald, sehingga insiden tidak berubah menjadi perburuan SSH.
Anda tetap bisa melakukan rollout aman tanpa cluster. Setup blue/green sederhana bekerja: pertahankan dua direktori (atau dua VM), alihkan load balancer, dan siapkan versi sebelumnya untuk rollback cepat. Canary mirip: kirim sebagian kecil traffic ke versi baru sebelum commit.
Sebelum menandai deploy “selesai”, jalankan smoke check post-deploy yang sama di mana pun:
Jika Anda meregenerasi backend (misalnya backend Go AppMaster), pendekatan ini tetap stabil: build sekali, deploy artefak, dan biarkan konfigurasi lingkungan mengendalikan perbedaan, bukan skrip ad-hoc.
Sebagian besar rilis rusak bukan karena “kode jelek”. Mereka terjadi ketika pipeline berperilaku berbeda dari run ke run. Jika Anda ingin CI/CD untuk backend Go terasa tenang dan dapat diprediksi, perhatikan pola-pola ini.
Menjalankan migrasi database otomatis di setiap deploy tanpa guardrail adalah klasik. Migrasi yang mengunci tabel dapat menurunkan layanan sibuk. Letakkan migrasi di balik langkah eksplisit, minta persetujuan untuk produksi, dan pastikan Anda bisa menjalankannya ulang dengan aman.
Menggunakan tag latest atau base image yang tidak dipin adalah cara mudah menciptakan kegagalan misterius. Pin Docker image dan versi Go supaya lingkungan build Anda tidak bergeser.
Berbagi satu database antar lingkungan “sementara” cenderung menjadi permanen, dan ini cara data uji bocor ke staging dan skrip staging menyentuh produksi. Pisahkan database (dan kredensial) per lingkungan, walau skemanya sama.
Ketiadaan health checks dan readiness checks membiarkan deploy “sukses” sementara service rusak, dan traffic dialihkan terlalu dini. Tambahkan cek yang mencerminkan perilaku nyata: apakah app bisa start, terhubung ke database, dan melayani request.
Terakhir, kepemilikan yang tidak jelas untuk secret, konfigurasi, dan akses mengubah rilis menjadi tebak-tebakan. Seseorang harus bertanggung jawab membuat, merotasi, dan menyuntik secret.
Kegagalan realistis: tim menggabungkan perubahan, pipeline melakukan deploy, dan migrasi otomatis berjalan dulu. Itu selesai di staging (data kecil), tapi time out di produksi (data besar). Dengan image yang dipin, pemisahan lingkungan, dan langkah migrasi yang digated, deploy akan berhenti dengan aman.
Jika Anda menghasilkan backend Go (misalnya dengan AppMaster), aturan ini lebih penting karena regenerasi bisa menyentuh banyak file sekaligus. Input yang dapat diprediksi dan gate eksplisit menjaga perubahan “besar” agar tidak menjadi rilis berisiko.
Gunakan ini sebagai pengecekan naluriah untuk CI/CD backend Go. Jika Anda bisa menjawab tiap poin dengan “ya” yang jelas, rilis menjadi lebih mudah.
Batasi akses produksi dan buat dapat diaudit. CI harus melakukan deploy menggunakan service account khusus, secret dikelola secara terpusat, dan setiap tindakan manual di produksi harus meninggalkan jejak jelas (siapa, apa, kapan).
Tim ops kecil beranggotakan empat orang merilis sekali seminggu. Mereka sering meregenerasi backend Go karena tim produk terus menyempurnakan workflow. Tujuan sederhana: lebih sedikit perbaikan larut malam dan rilis yang tidak mengejutkan siapa pun.
Perubahan tipikal Jumat: mereka menambahkan field baru ke customers (perubahan skema) dan memperbarui API yang menulisnya (perubahan kode). Pipeline menganggap ini satu rilis. Ia membangun satu artefak, menjalankan test terhadap artefak yang sama, dan baru kemudian menerapkan migrasi dan deploy. Dengan begitu, database tidak pernah lebih maju dari kode yang mengharapkannya, dan kode tidak pernah dideploy tanpa skema yang cocok.
Saat perubahan skema disertakan, pipeline menambahkan gate pengaman. Ia memeriksa bahwa migrasi bersifat additif (seperti menambahkan kolom nullable) dan menandai aksi berisiko (seperti drop column atau rewrite tabel besar). Jika migrasi berisiko, rilis berhenti sebelum produksi. Tim kemudian menulis ulang migrasi agar lebih aman atau menjadwalkannya pada jendela terencana.
Jika test gagal, tidak ada yang bergerak maju. Sama halnya jika migrasi gagal di lingkungan pra-produksi. Pipeline tidak boleh mencoba memaksa perubahan lewat “hanya kali ini”.
Langkah praktis yang sederhana untuk kebanyakan tim:
Jika Anda menghasilkan backend dengan AppMaster, pertahankan regenerasi di dalam stage pipeline yang sama: regenerate, build, test, migrate di lingkungan aman, lalu deploy. Perlakukan source yang dihasilkan seperti source lain. Setiap rilis harus dapat direproduksi dari versi yang ditandai, dengan langkah yang sama setiap kali.
Pasang versi Go dan lingkungan build Anda sehingga input yang sama selalu menghasilkan binary atau image yang sama. Itu menghilangkan perbedaan “works on my machine” dan membuat kegagalan lebih mudah direproduksi dan diperbaiki.
Regenerasi dapat mengubah endpoint, model database, dan dependensi bahkan jika tidak ada yang mengedit kode secara manual. Pipeline memastikan perubahan itu melewati pemeriksaan yang sama setiap kali, sehingga regenerasi tetap aman bukan berisiko.
Build sekali, lalu promosikan artefak yang sama melalui dev, staging, dan prod. Jika Anda membangun ulang per lingkungan, Anda bisa tidak sengaja mengirim sesuatu yang belum pernah diuji, meskipun commit-nya sama.
Jalankan gerbang cepat pada setiap pull request: formatting, pengecekan statis dasar, build, dan unit test dengan timeout. Buat cukup cepat agar orang tidak melewatinya, dan cukup ketat agar perubahan rusak berhenti sejak awal.
Gunakan stage integrasi kecil yang menyalakan service dengan konfigurasi mirip produksi dan berkomunikasi ke dependensi nyata seperti PostgreSQL. Tujuannya menangkap kasus “kompilasi berhasil tapi tidak bisa start” dan pelanggaran kontrak jelas tanpa mengubah CI menjadi rangkaian end-to-end yang berlangsung berjam-jam.
Anggap migrasi sebagai langkah rilis yang dikontrol, bukan sesuatu yang berjalan implisit di setiap deploy. Jalankan dengan log yang jelas dan kunci single-run, dan jujurlah tentang rollback: banyak perubahan skema memerlukan perbaikan maju atau restore backup, bukan undo sederhana.
Gunakan readiness checks sehingga traffic hanya menuju pod baru setelah service benar-benar siap, dan gunakan liveness checks untuk merestart container yang macet. Juga tetapkan resource requests dan limits yang realistis sehingga service yang lulus CI tidak terbunuh di production karena menggunakan memori lebih dari yang diharapkan.
Unit file systemd sederhana ditambah skrip rilis yang konsisten seringkali cukup untuk deploy tenang di VM. Pertahankan model artefak yang sama seperti kontainer bila memungkinkan, dan tambah smoke check post-deploy kecil sehingga “restart sukses” tidak menyembunyikan service yang rusak.
Jangan pernah memasukkan secret ke repo, artefak build, atau logs. Suntik secret saat deploy dari secret store yang dikelola, batasi siapa yang dapat membacanya, dan jadikan rotasi sebagai tugas rutin bukan keadaan darurat.
Masukkan regenerasi ke dalam stage pipeline yang sama seperti perubahan lain: regenerate, build, test, package, lalu migrate dan deploy dengan gate. Jika Anda menggunakan AppMaster untuk menghasilkan backend Go, ini memungkinkan Anda bergerak cepat tanpa menebak apa yang berubah, dan mencoba alur tanpa kode untuk regenerasi dan deploy lebih percaya diri.



Eksperimen dengan AppMaster dengan paket gratis.
Saat Anda siap, Anda dapat memilih langganan yang tepat.


