Aplikasi pemesanan peralatan: cegah konflik dan lacak pengembalian
Rencanakan aplikasi pemesanan peralatan yang mencegah pemesanan ganda, mencatat pengembalian dan kerusakan, serta menahan item bermasalah untuk pemeliharaan.
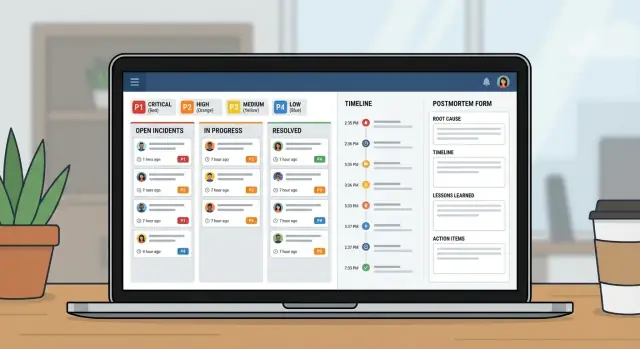
Rencanakan dan bangun aplikasi manajemen insiden untuk tim IT dengan alur keparahan, kepemilikan jelas, timeline, dan postmortem dalam satu alat internal.
Saat outage terjadi, kebanyakan tim mengambil apa pun yang tersedia: thread chat, rantai email, atau mungkin spreadsheet yang diupdate ketika ada waktu. Di bawah tekanan, pengaturan itu rusak dengan cara yang sama tiap kali: kepemilikan kabur, stempel waktu hilang, dan keputusan lenyap di guliran chat.
Aplikasi manajemen insiden sederhana memperbaiki dasar-dasarnya. Ia memberi satu tempat untuk menyimpan insiden, dengan pemilik jelas, level keparahan yang disepakati semua orang, dan timeline apa yang terjadi dan kapan. Satu catatan itu penting karena pertanyaan yang sama muncul di setiap insiden: Siapa yang memimpin? Kapan mulai? Apa status saat ini? Apa yang sudah dicoba?
Tanpa catatan bersama itu, penyerahan tugas membuang waktu. Support memberi tahu pelanggan satu hal sementara engineering melakukan hal lain. Manajer meminta pembaruan yang menarik responder dari perbaikan. Setelahnya, tak seorang pun bisa membangun kembali timeline dengan percaya diri, sehingga postmortem berubah jadi tebakan.
Tujuannya bukan mengganti monitoring, chat, atau ticketing Anda. Alert masih bisa datang dari tempat lain. Intinya adalah menangkap jejak keputusan dan menjaga manusia tetap selaras.
Operasi IT dan on-call engineer menggunakannya untuk mengoordinasikan respon. Support menggunakannya untuk memberi pembaruan yang akurat dengan cepat. Manajer menggunakannya untuk melihat progres tanpa mengganggu responder.
Pukul 09:12, monitoring menandai lonjakan error 500 di portal pelanggan. Seorang agen support juga melaporkan, “Login gagal untuk kebanyakan pengguna.” IT lead on-call membuka insiden P1 di aplikasi dan melampirkan alert pertama plus screenshot dari support.
Dengan P1, perilaku berubah cepat. Pemilik insiden menarik pemilik backend, pemilik database, dan liaison support. Pekerjaan non-esensial ditangguhkan. Deploy yang direncanakan dihentikan. Tim sepakat pada ritme pembaruan (misalnya setiap 15 menit). Panggilan bersama dimulai, tetapi catatan insiden tetap sumber kebenaran.
Pukul 09:18, seseorang bertanya, “Apa yang berubah?” Timeline menunjukkan deploy pada 08:57, tapi tidak menyebut apa yang dideploy. Pemilik backend tetap rollback. Error turun, lalu kembali. Kini tim curiga pada database.
Sebagian besar keterlambatan muncul di beberapa tempat yang dapat diprediksi: penyerahan yang tidak jelas (“Saya kira kamu yang memeriksa itu”), konteks hilang (perubahan terbaru, risiko yang diketahui, pemilik saat ini), dan pembaruan yang tersebar di chat, tiket, dan email.
Pukul 09:41, pemilik database menemukan query runaway yang dipicu job terjadwal. Mereka menonaktifkan job, restart service yang terdampak, dan mengonfirmasi pemulihan. Keparahan diturunkan menjadi P2 untuk pemantauan.
Penutupan yang baik bukan sekadar “kembali berjalan.” Itu catatan rapi: timeline menit demi menit, akar penyebab akhir, siapa yang membuat keputusan apa, apa yang ditangguhkan, dan kerja lanjutan dengan pemilik serta tanggal jatuh tempo. Begitulah P1 yang penuh tekanan berubah menjadi pembelajaran, bukan rasa sakit berulang.
Alat insiden yang baik sebagian besar adalah model data yang baik. Jika catatan samar, orang akan berdebat tentang apa insiden itu, kapan mulai, dan apa yang masih terbuka.
Jaga entitas inti dekat dengan cara tim IT sudah bicara:
Untuk mencegah kebingungan nanti, berikan Incident beberapa field terstruktur yang selalu diisi. Teks bebas membantu, tapi tidak boleh jadi satu-satunya sumber kebenaran. Minimum praktis: judul jelas, dampak (apa yang dialami pengguna), layanan yang terdampak, waktu mulai, status saat ini, dan keparahan.
Relasi lebih penting daripada field tambahan. Satu incident harus punya banyak update dan tugas, plus hubungan many-to-many ke services (karena outage sering memengaruhi beberapa sistem). Postmortem sebaiknya satu-ke-satu dengan incident, sehingga ada satu cerita final.
Contoh: incident “Checkout errors” terhubung ke Services “Payments API” dan “PostgreSQL,” punya update setiap 15 menit, dan tugas seperti “Rollback deploy” dan “Tambah retry guard.” Nanti, postmortem menangkap akar penyebab dan membuat tugas jangka panjang.
Saat orang stres, mereka butuh label sederhana yang berarti sama bagi semua orang. Definisikan P1 sampai P4 dengan bahasa biasa dan tampilkan definisinya di sebelah field keparahan.
Target respon harus berbentuk komitmen. Baseline sederhana (sesuaikan dengan realitas Anda):
| Keparahan | Respon pertama (ack) | Pembaruan pertama | Frekuensi pembaruan |
|---|---|---|---|
| P1 | 5 min | 15 min | setiap 30 min |
| P2 | 15 min | 30 min | setiap 60 min |
| P3 | 4 jam | 1 hari kerja | harian |
| P4 | 2 hari kerja | 1 minggu | mingguan |
Buat aturan eskalasi mekanis. Jika P2 melewatkan ritme pembaruan atau dampak bertambah, sistem harus mendorong review keparahan. Untuk menghindari fluktuasi berlebihan, batasi siapa yang bisa mengubah keparahan (seringkali pemilik insiden atau incident commander), tetapi biarkan siapapun meminta review lewat komentar.
Matriks dampak cepat juga membantu tim memilih keparahan dengan cepat. Tangkap sebagai beberapa field wajib: pengguna terdampak, risiko pendapatan, keselamatan, kepatuhan/keamanan, dan apakah ada workaround.
Selama insiden, orang tidak butuh lebih banyak pilihan. Mereka butuh beberapa status yang membuat langkah berikutnya jelas.
Mulai dengan langkah yang sudah Anda ikuti pada hari yang baik, lalu jaga agar daftar pendek. Jika lebih dari 6 atau 7 status, tim akan berdebat soal kata-kata alih-alih memperbaiki masalah.
Set praktis:
Setiap status perlu aturan masuk dan keluar yang jelas. Contoh:
Gunakan transisi untuk menegakkan field yang sering terlupakan. Aturan umum: Anda tidak bisa menutup incident tanpa ringkasan akar penyebab singkat dan setidaknya satu item tindak lanjut. Jika “RCA: TBD” diizinkan, biasanya akan tetap begitu.
Halaman insiden harus menjawab tiga pertanyaan sekilas: siapa pemiliknya, apa tindakan selanjutnya, dan kapan pembaruan terakhir diposting.
Saat insiden ramai, cara tercepat kehilangan waktu adalah kepemilikan yang kabur. Aplikasi Anda harus membuat satu orang bertanggung jawab secara jelas, sambil tetap memudahkan orang lain membantu.
Pola sederhana yang tahan lama:
Penugasan harus eksplisit dan dapat diaudit. Lacak siapa yang menetapkan owner, siapa yang menerima, dan setiap perubahan setelah itu. “Diterima” penting, karena menugaskan seseorang yang sedang tidur atau offline bukan kepemilikan nyata.
Penugasan on-call vs berbasis tim biasanya tergantung keparahan. Untuk P1/P2, default ke rotasi on-call sehingga selalu ada pemilik bernama. Untuk keparahan lebih rendah, penugasan berbasis tim bisa bekerja, tapi tetap wajibkan satu primary owner dalam waktu singkat.
Rencanakan cuti dan outage manusia dalam proses Anda, bukan hanya sistem. Jika orang yang ditugaskan ditandai tidak tersedia, rute ke on-call sekunder atau lead tim. Buat otomatis, tapi terlihat sehingga bisa dikoreksi cepat.
Eskalasi harus dipicu oleh keparahan dan keheningan. Titik awal yang berguna:
Timeline yang baik adalah memori bersama. Selama insiden, konteks cepat hilang. Jika Anda menangkap momen yang tepat di satu tempat, penyerahan jadi lebih mudah dan postmortem sebagian besar sudah tertulis sebelum siapa pun membuka dokumen.
Jaga timeline bersifat opinatif. Jangan jadikan ia log chat. Kebanyakan tim mengandalkan beberapa entri saja: deteksi, pengakuan, langkah mitigasi kunci, restore, dan penutupan.
Setiap entri butuh stempel waktu, penulis, dan deskripsi singkat dengan bahasa biasa. Seseorang yang bergabung terlambat harus bisa membaca lima entri dan paham apa yang terjadi.
Berbagai pembaruan melayani audiens berbeda. Akan membantu jika entri punya tipe, seperti catatan internal (detail mentah), pembaruan untuk pelanggan (bahasa aman), keputusan (mengapa memilih opsi A), dan handoff (apa yang harus diketahui orang berikutnya).
Pengingat harus mengikuti keparahan, bukan preferensi pribadi. Jika timer mencapai batas, ping pemilik saat ini dulu, lalu eskalasi jika terus terlewat.
Notifikasi harus terarah dan dapat diprediksi. Aturan kecil biasanya cukup: notifikasi pada pembuatan, perubahan keparahan, restore, dan pembaruan yang terlambat. Hindari memberi tahu seluruh perusahaan untuk setiap perubahan.
Postmortem harus melakukan dua hal: menjelaskan apa yang terjadi dengan bahasa sederhana, dan membuat kegagalan yang sama lebih kecil kemungkinannya.
Jaga tulisannya singkat, dan paksa hasilnya jadi aksi. Struktur praktis meliputi: ringkasan, dampak ke pelanggan, akar penyebab, perbaikan yang diterapkan, dan tindak lanjut.
Tindak lanjut adalah intinya. Jangan biarkan mereka jadi paragraf di akhir. Ubah setiap tindak lanjut menjadi tugas yang ditelusuri dengan pemilik dan tanggal jatuh tempo, meski tanggalnya “sprint berikutnya.” Itu bedanya antara “kita harus tingkatkan monitoring” dan “Alex menambahkan alert saturasi koneksi DB pada hari Jumat.”
Tag membuat postmortem berguna nanti. Tambahkan 1 sampai 3 tema untuk setiap insiden (kekurangan monitoring, rilis, kapasitas, proses). Setelah sebulan, Anda bisa menjawab pertanyaan dasar seperti apakah sebagian besar P1 disebabkan release atau alert yang tidak ada.
Bukti harus mudah dilampirkan, bukan wajib. Sediakan field opsional untuk screenshot, potongan log, dan referensi ke sistem eksternal (ID tiket, thread chat, nomor kasus vendor). Buat ringan agar orang benar-benar mengisinya.
Perlakukan ini seperti produk kecil, bukan spreadsheet dengan kolom tambahan. Aplikasi insiden yang baik sebenarnya tiga tampilan: apa yang sedang terjadi sekarang, apa yang harus dilakukan selanjutnya, dan apa yang dipelajari sesudahnya.
Mulai dengan menggambar layar yang akan dibuka orang saat tekanan:
Bangun model data dan izin bersamaan. Jika semua bisa mengedit semua hal, riwayat jadi berantakan. Pendekatan umum: akses tampilan luas untuk IT, kontrol perubahan state/keparahan, responder bisa menambah update, dan ada pemilik jelas untuk persetujuan postmortem.
Lalu tambahkan aturan alur kerja yang mencegah insiden setengah terisi. Field wajib harus bergantung pada status. Mungkin Anda membolehkan “New” hanya dengan judul dan pelapor, tapi mewajibkan “Mitigating” memiliki ringkasan dampak, dan mewajibkan “Resolved” menyertakan ringkasan akar penyebab plus setidaknya satu tindak lanjut.
Akhirnya, uji dengan memutar ulang 2 sampai 3 insiden masa lalu. Satu orang bertindak sebagai incident commander dan satu sebagai responder. Anda akan cepat melihat status mana yang tidak jelas, field mana yang dilewatkan, dan di mana Anda butuh default yang lebih baik.
Kebanyakan sistem insiden gagal karena alasan sederhana: orang tidak ingat aturan saat stres, dan aplikasi tidak menangkap fakta yang Anda butuhkan nanti.
Jika Anda punya enam level keparahan dan sepuluh status, orang akan menebak. Jaga keparahan 3–4 dan fokuskan status pada apa yang harus dilakukan selanjutnya.
Saat semua orang “mengawasi,” tidak ada yang menjalankan. Wajibkan satu pemilik bernama sebelum insiden bisa maju, dan buat handoff eksplisit.
Jika “apa yang terjadi kapan” bergantung pada riwayat chat, postmortem menjadi perdebatan. Tangkap otomatis timestamp untuk opened, acknowledged, mitigated, dan resolved, dan jaga entri timeline singkat.
Juga hindari menutup dengan catatan akar penyebab yang samar seperti “masalah jaringan.” Wajibkan pernyataan akar penyebab yang jelas plus setidaknya satu langkah konkret berikutnya.
Sebelum Anda gulirkan ke seluruh organisasi IT, lakukan stress test pada dasar-dasarnya. Jika orang tidak menemukan tombol yang tepat dalam dua menit pertama, mereka akan kembali ke thread chat dan spreadsheet.
Fokus pada beberapa pemeriksaan peluncuran singkat: peran dan izin, definisi keparahan yang jelas, kepemilikan yang ditegakkan, aturan pengingat, dan jalur eskalasi ketika target respon terlewat.
Pilotkan dengan satu tim dan beberapa layanan yang sering menghasilkan alert. Jalankan selama dua minggu, lalu sesuaikan berdasarkan insiden nyata.
Jika Anda ingin membangunnya sebagai satu alat internal tanpa menjahit spreadsheet dan aplikasi terpisah, AppMaster (appmaster.io) adalah salah satu opsi. Ia memungkinkan Anda membuat model data, aturan alur kerja, dan antarmuka web/mobile dalam satu tempat, yang cocok untuk antrean insiden, halaman insiden, dan pelacakan postmortem.
Ia menggantikan pembaruan yang tersebar dengan satu catatan bersama yang menjawab hal-hal dasar dengan cepat: siapa pemilik insiden, apa yang dilihat pengguna, apa yang sudah dicoba, dan apa langkah selanjutnya. Ini mengurangi waktu yang hilang karena penyerahan tugas, pesan yang bertentangan, dan interupsi “bisakah kamu ringkaskan?”.
Buka insiden segera setelah Anda percaya ada dampak nyata pada pelanggan atau bisnis, meskipun penyebabnya belum jelas. Anda bisa membuka dengan judul draf dan “dampak tidak diketahui”, lalu perbarui detail saat severity dan ruang lingkup dikonfirmasi.
Simpel dan terstruktur: judul jelas, ringkasan dampak, layanan yang terpengaruh, waktu mulai, status saat ini, severity, dan satu pemilik tunggal. Tambahkan pembaruan dan tugas saat situasi berkembang, tapi jangan hanya mengandalkan teks bebas untuk fakta inti.
Gunakan 3 hingga 4 level dengan arti yang jelas agar tidak memicu perdebatan. Default yang baik: P1 untuk outage inti atau risiko kehilangan data, P2 untuk fitur utama terganggu dengan workaround atau cakupan terbatas, P3 untuk isu berdampak kecil, dan P4 untuk masalah kosmetik atau minor.
Buat target yang terasa seperti komitmen, bukan tebakan: waktu untuk mengakui, waktu untuk pembaruan pertama, dan frekuensi pembaruan. Lalu picu pengingat dan eskalasi saat frekuensi terlewat—karena “keheningan” sering kali adalah kegagalan nyata selama insiden.
Targetkan sekitar enam status: New, Acknowledged, Investigating, Mitigating, Monitoring, dan Resolved. Setiap status harus membuat langkah selanjutnya jelas, dan transisi harus menegakkan hal-hal yang sering terlupakan saat stres, misalnya mewajibkan pemilik sebelum Acknowledged atau ringkasan root cause sebelum penutupan.
Wajibkan satu pemilik utama yang bertanggung jawab mendorong respon dan memposting pembaruan. Catat penerimaan secara eksplisit supaya Anda tidak “menugaskan” seseorang yang sedang offline, dan buat handoff sebagai peristiwa yang direkam agar orang berikutnya tidak mengulang investigasi dari awal.
Tangkap hanya momen yang penting: deteksi, pengakuan, keputusan kunci, langkah mitigasi, pemulihan, dan penutupan — masing-masing dengan stempel waktu dan penulis. Perlakukan timeline sebagai memori bersama, bukan transkrip chat, sehingga orang yang datang terlambat bisa cepat mengejar.
Buat singkat dan berfokus pada aksi: apa yang terjadi, dampak pada pelanggan, penyebab utama, apa yang diubah saat mitigasi, dan tindak lanjut dengan pemilik dan tanggal jatuh tempo. Tulisan berguna, tapi tugas yang ditindaklanjuti mencegah insiden yang sama terulang.
Ya—jika Anda memodelkan incidents, updates, tasks, services, dan postmortems sebagai data nyata dan menerapkan aturan alur kerja di aplikasi. Dengan AppMaster (appmaster.io), tim bisa membangun model data plus layar web/mobile dan validasi berbasis status di satu tempat, sehingga proses tidak kembali ke spreadsheet saat tekanan.



Eksperimen dengan AppMaster dengan paket gratis.
Saat Anda siap, Anda dapat memilih langganan yang tepat.


