Aplikasi pemesanan peralatan: cegah konflik dan lacak pengembalian
Rencanakan aplikasi pemesanan peralatan yang mencegah pemesanan ganda, mencatat pengembalian dan kerusakan, serta menahan item bermasalah untuk pemeliharaan.
Alur kerja jangka panjang bisa gagal dengan cara berantakan. Pelajari pola status yang jelas, penghitung retry, penanganan dead-letter, dan dasbor yang dapat dipercaya operator.
Alur kerja yang berjalan lama gagal dengan cara berbeda dibanding permintaan singkat. Panggilan API singkat biasanya berhasil atau error segera. Sebuah workflow yang berjalan berjam-jam atau berhari-hari bisa mencapai 9 dari 10 langkah dan tetap meninggalkan kekacauan: catatan yang setengah dibuat, status yang membingungkan, dan tidak ada tindakan selanjutnya yang jelas.
Itulah sebabnya “kemarin berhasil” sering muncul. Workflow tidak berubah, tetapi lingkungannya berubah. Alur kerja jangka panjang bergantung pada layanan lain tetap sehat, kredensial tetap valid, dan data tetap sesuai bentuk yang diharapkan.
Mode kegagalan paling umum terlihat seperti ini: timeout dan dependency lambat (API mitra tersedia tapi hari ini memakan 40 detik), pembaruan parsial (record A dibuat, record B tidak dibuat, dan Anda tidak bisa menjalankan ulang dengan aman), pemadaman dependency (penyedia email/SMS, gateway pembayaran, jendela maintenance), callback yang hilang dan jadwal yang terlewat (webhook tak pernah datang, job timer tidak terpanggil), dan langkah manusia yang terhenti (persetujuan tertunda berhari-hari lalu dilanjutkan dengan asumsi usang).
Bagian tersulit adalah status. Permintaan singkat bisa menyimpan status di memori sampai selesai. Workflow tidak bisa. Ia harus menyimpan status antara langkah dan siap dilanjutkan setelah restart, deploy, atau crash. Ia juga harus menghadapi kemungkinan langkah yang sama terpicu dua kali (retry, webhook duplikat, replay operator).
Pada praktiknya, “andal” bukan tentang tidak pernah gagal, melainkan tentang dapat diprediksi, dapat dijelaskan, dapat dipulihkan, dan jelas dimiliki.
Dapat diprediksi berarti workflow bereaksi sama tiap kali dependency gagal. Dapat dijelaskan berarti operator bisa menjawab, dalam satu menit, “Di mana macet dan kenapa?” Dapat dipulihkan berarti Anda bisa mengulang atau melanjutkan dengan aman tanpa merusak. Kepemilikan jelas berarti setiap item yang macet punya tindakan selanjutnya yang jelas: tunggu, ulangi, perbaiki data, atau serahkan ke manusia.
Contoh sederhana: otomatisasi onboarding membuat record pelanggan, menyiapkan akses, dan mengirim pesan sambutan. Jika provisioning berhasil tapi pengiriman pesan gagal karena penyedia email turun, workflow yang andal mencatat “Provisioned, message pending” dan menjadwalkan pengulangan. Ia tidak menjalankan ulang provisioning secara membabi buta.
Alat dapat mempermudah dengan menjaga logika workflow dan data persisten dekat satu sama lain. Misalnya, AppMaster memungkinkan Anda memodelkan status workflow di data (melalui Data Designer) dan mengupdatenya dari Business Processes visual. Tapi keandalan datang dari pola, bukan alat: perlakukan otomatisasi jangka panjang sebagai rangkaian status tahan lama yang bisa bertahan terhadap waktu, kegagalan, dan intervensi manusia.
Alur kerja jangka panjang cenderung gagal dengan cara yang berulang: API pihak ketiga melambat, manusia belum menyetujui, atau job menunggu antrean. Status yang jelas membuat situasi itu terlihat, sehingga orang tidak salah mengira “butuh waktu” sebagai “rusak”.
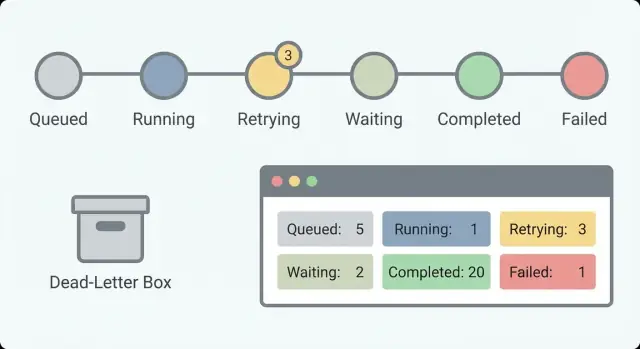
Mulailah dengan set status kecil yang menjawab satu pertanyaan: apa yang sedang terjadi sekarang? Jika Anda punya 30 status, tak ada yang akan mengingatnya. Dengan sekitar 5–8, orang yang on-call bisa memindai daftar dan memahaminya.
Set status praktis yang bekerja untuk banyak workflow:
Memisahkan Menunggu dari Berjalan penting. “Menunggu respon pelanggan” adalah sehat. “Berjalan selama 6 jam” mungkin hang. Tanpa pemisahan ini, Anda akan mengejar alarm palsu dan melewatkan yang sebenarnya.
Nama status tidak cukup. Tambahkan beberapa field yang mengubah status menjadi sesuatu yang bisa ditindaklanjuti:
Contoh: alur onboarding bisa menampilkan “Menunggu” dengan alasan “Pending manager approval” dan terakhir berubah “2 hari lalu.” Itu memberi tahu bahwa ini tidak macet, tapi mungkin perlu pengingat.
Perlakukan nama status seperti API. Jika Anda menggantinya setiap bulan, dasbor, alert, dan playbook dukungan cepat menjadi menyesatkan. Jika Anda butuh makna baru, pertimbangkan menambah status baru dan biarkan yang lama tetap ada untuk record yang sudah ada.
Di AppMaster, Anda bisa memodelkan status ini di Data Designer dan mengupdatenya dari logika Business Process. Itu menjaga status terlihat dan konsisten di seluruh aplikasi Anda alih-alih terkubur di log.
Retry membantu sampai mereka menyembunyikan masalah sebenarnya. Tujuannya bukan “tidak pernah gagal.” Tujuannya “gagal dengan cara yang bisa dipahami dan diperbaiki.” Itu dimulai dengan aturan jelas apa yang boleh diulang dan apa yang tidak.
Aturan yang bisa diterima banyak tim: ulangi error yang kemungkinan sementara (network timeout, rate limit, gangguan pihak ketiga). Jangan ulangi error yang jelas permanen (input tidak valid, izin hilang, “akun ditutup”, “kartu ditolak”). Jika Anda tidak bisa membedakan, anggap non-retryable sampai Anda tahu lebih banyak.
Lacak counter retry per langkah (atau per panggilan eksternal), bukan hanya satu counter untuk seluruh workflow. Sebuah workflow bisa punya sepuluh langkah, dan hanya satu yang flakey. Counter per langkah mencegah langkah akhir “mencuri” percobaan dari langkah awal.
Misalnya, panggilan “Upload document” mungkin diulang beberapa kali, sementara “Send welcome email” tidak perlu terus dicoba karena upload sudah menghabiskan semua percobaan.
Pilih pola backoff yang sesuai risiko. Delay tetap bisa cukup untuk retry sederhana dan murah. Exponential backoff membantu saat Anda mungkin terkena rate limit. Tambahkan batas (cap) supaya jeda tidak tumbuh tanpa batas, dan tambahkan sedikit jitter untuk menghindari retry storm.
Lalu tentukan kapan berhenti. Kondisi berhenti yang baik eksplisit: jumlah percobaan maksimum, total waktu maksimum, atau “berhenti untuk kode error tertentu.” Gateway pembayaran mengembalikan “invalid card” harus berhenti segera meskipun biasanya Anda mengizinkan lima percobaan.
Operator juga perlu tahu apa yang akan terjadi selanjutnya. Catat waktu pengulangan berikutnya dan alasannya (misalnya, “Retry 3/5 at 14:32 due to timeout”). Di AppMaster, Anda bisa menyimpan itu di record workflow sehingga dasbor dapat menampilkan “menunggu sampai” tanpa menebak.
Kebijakan retry yang baik meninggalkan jejak: apa yang gagal, berapa kali dicoba, kapan akan dicoba lagi, dan kapan akan berhenti dan dialihkan ke dead-letter.
Dalam workflow yang berjalan berjam-jam atau berhari-hari, pengulangan itu normal. Risikonya mengulang langkah yang sudah berhasil. Idempotensi adalah aturan yang membuat ini aman: sebuah langkah idempotent jika menjalankannya dua kali memiliki efek yang sama dengan menjalankannya sekali.
Kegagalan klasik: Anda mengenakan biaya kartu, lalu workflow crash sebelum menyimpan “payment succeeded.” Saat retry, ia menagih lagi. Itu masalah double-write: dunia luar berubah, tapi status workflow Anda tidak.
Pola paling aman adalah membuat kunci idempotensi stabil untuk setiap langkah yang berpengaruh, mengirimkannya dengan panggilan eksternal, dan menyimpan hasil langkah segera setelah diterima. Banyak penyedia pembayaran dan penerima webhook mendukung kunci idempotensi (misalnya, menagih pesanan berdasarkan OrderID). Jika langkah terulang, penyedia mengembalikan hasil asli daripada melakukan aksi lagi.
Di dalam engine workflow Anda, anggap setiap langkah bisa direplay. Di AppMaster, itu sering berarti menyimpan output langkah di model database Anda dan memeriksanya di Business Process sebelum memanggil integrasi lagi. Jika “Send welcome email” sudah punya MessageID tersimpan, retry harus memakai record itu dan melanjutkan.
Pendekatan praktis aman-duplikat:
Duplikasi tetap terjadi, terutama dengan webhook masuk atau ketika pengguna menekan tombol yang sama dua kali. Putuskan kebijakan per tipe event: abaikan duplikat tepat (sama idempotency key), gabungkan pembaruan yang kompatibel (mis. last-write-wins untuk field profil), atau tandai untuk ditinjau jika ada risiko uang atau kepatuhan.
Dead-letter adalah item workflow yang gagal dan dipindahkan keluar dari jalur normal agar tidak memblokir semuanya. Anda menyimpannya dengan sengaja. Tujuannya membuatnya mudah dimengerti apa yang terjadi, putuskan apakah bisa diperbaiki, dan memproses ulang dengan aman.
Kesalahan terbesar adalah menyimpan hanya pesan error. Saat seseorang melihat dead-letter nanti, mereka perlu konteks cukup untuk mereproduksi masalah tanpa menebak.
Entri dead-letter yang berguna mencakup:
Klasifikasi membuat dead-letter dapat ditindaklanjuti. Kategori singkat membantu operator memilih langkah berikutnya. Grup umum termasuk permanent error (aturan logika, status tidak valid), masalah data (field hilang, format salah), dependency down (timeout, rate limit, outage), dan auth/permission (token kadaluarsa, kredensial ditolak).
Pemrosesan ulang harus dikendalikan. Tujuannya menghindari kerusakan berulang, seperti menagih dua kali atau mengirim spam email. Tentukan aturan siapa yang bisa retry, kapan boleh retry, apa yang bisa diubah (edit field tertentu, lampirkan dokumen yang hilang, refresh token), dan apa yang harus tetap (request ID dan idempotency key downstream).
Buat item dead-letter dapat dicari berdasarkan identifier stabil. Saat operator bisa mengetik “order 18422” dan melihat langkah, input, dan riwayat percobaan yang tepat, perbaikan menjadi cepat dan konsisten.
Jika Anda membangun ini di AppMaster, perlakukan dead-letter sebagai model database kelas satu dan simpan status, percobaan, dan identifier sebagai field. Dengan begitu, dasbor internal Anda bisa query, filter, dan memicu aksi reprocess yang terkontrol.
Alur kerja jangka panjang bisa gagal dengan cara lambat dan membingungkan: langkah menunggu balasan email, penyedia pembayaran timeout, atau webhook datang dua kali. Jika Anda tidak bisa melihat apa yang sedang dilakukan workflow sekarang, Anda akan menebak. Visibilitas yang baik mengubah “rusak” menjadi jawaban jelas: workflow mana, langkah mana, status apa, dan apa yang harus dilakukan.
Mulailah dengan membuat setiap langkah mengeluarkan set field kecil yang sama sehingga operator bisa memindai cepat:
Field-field itu mendukung penghitung dasar yang menunjukkan kesehatan sekilas. Untuk workflow jangka panjang, jumlah lebih penting daripada satu error karena Anda mencari tren: pekerjaan yang menumpuk, spike retry, atau waktu tunggu yang tak pernah berakhir.
Lacak started, completed, failed, retrying, dan waiting dari waktu ke waktu. Jumlah waiting kecil bisa normal (persetujuan manusia). Jumlah waiting yang naik biasanya berarti sesuatu terblokir. Jumlah retrying yang naik sering menunjukkan masalah penyedia atau bug yang terus menghasilkan error yang sama.
Alert harus mencerminkan pengalaman operator. Alih-alih “terjadi error,” alert pada gejala: backlog yang tumbuh (started minus completed terus meningkat), terlalu banyak workflow terjebak di waiting melewati waktu yang diharapkan, tingkat retry tinggi untuk langkah tertentu, atau lonjakan kegagalan tepat setelah rilis atau perubahan konfigurasi.
Simpan jejak peristiwa untuk setiap workflow sehingga “apa yang terjadi?” bisa dijawab dalam satu tampilan. Jejak yang berguna mencakup timestamp, transisi status, ringkasan input dan output (bukan payload sensitif penuh), dan alasan retry atau kegagalan. Contoh: “Charge card: retry 3/5, timeout dari provider, percobaan berikutnya dalam 10m.”
Correlation ID adalah perekatnya. Jika pelanggan bilang “pembayaran saya ditagih dua kali,” Anda perlu mengaitkan event workflow dengan charge ID penyedia pembayaran dan internal order ID Anda. Di AppMaster, Anda bisa menstandarisasi ini di logika Business Process dengan menghasilkan dan meneruskan correlation ID melalui panggilan API dan langkah messaging agar dasbor dan log sejajar.
Saat workflow berjalan berjam-jam atau berhari-hari, kegagalan adalah normal. Yang membuat kegagalan normal menjadi outage adalah dasbor yang hanya menampilkan “Failed” tanpa informasi lain. Tujuannya membantu operator menjawab tiga pertanyaan dengan cepat: apa yang terjadi, kenapa terjadi, dan apa yang aman dilakukan selanjutnya.
Mulailah dengan daftar workflow yang memudahkan menemukan beberapa item yang penting. Filter mengurangi kepanikan dan kebingungan karena siapa pun bisa mempersempit tampilan dengan cepat.
Filter berguna termasuk status, usia (waktu mulai dan waktu di status saat ini), pemilik (tim/pelanggan/operator yang bertanggung jawab), tipe (nama/versi workflow), dan prioritas jika ada langkah berdampak pelanggan.
Selanjutnya, tunjukkan “kenapa” di samping status daripada menyembunyikannya di log. Pill status hanya membantu jika dipasangkan dengan pesan error terakhir, kategori error singkat, dan apa yang sistem rencanakan selanjutnya. Dua field melakukan sebagian besar pekerjaan: last error dan next retry time. Jika next retry kosong, jelaskan apakah workflow menunggu manusia, dijeda, atau gagal permanen.
Aksi operator harus aman secara default. Pandu orang ke tindakan berisiko rendah terlebih dahulu dan buat tindakan berisiko eksplisit:
“Force continue” adalah tempat terjadi banyak kerusakan. Jika Anda menawarkannya, jelaskan risikonya dalam bahasa sederhana: “Ini melewati verifikasi pembayaran dan mungkin membuat pesanan tidak terbayar.” Tampilkan juga data apa yang akan ditulis jika dilanjutkan.
Audit semua tindakan operator. Catat siapa yang melakukannya, kapan, state sebelum/sesudah, dan catatan alasannya. Jika Anda membangun alat internal di AppMaster, simpan jejak audit ini sebagai tabel kelas satu dan tunjukkan di halaman detail workflow supaya serah terima tetap bersih.
Pola ini menjaga workflow dapat diprediksi: setiap item selalu berada dalam status yang jelas, setiap kegagalan punya tempat untuk pergi, dan operator bisa bertindak tanpa menebak.
Step 1: Define states and allowed transitions. Tulis sejumlah kecil status yang orang bisa pahami (mis. Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter). Lalu tentukan perpindahan yang legal agar pekerjaan tidak melayang-layang ke limbo.
Step 2: Break work into small steps with clear inputs and outputs. Setiap langkah harus menerima satu input yang terdefinisi dengan baik dan menghasilkan satu output (atau error yang jelas). Jika Anda perlu keputusan manusia atau panggilan API eksternal, jadikan itu langkah tersendiri sehingga bisa berhenti dan dilanjutkan dengan bersih.
Step 3: Add a retry policy per step. Pilih batas percobaan, jeda antar percobaan, dan alasan berhenti yang tidak boleh diulang (data tidak valid, permission denied, field wajib hilang). Simpan counter retry per langkah agar operator bisa melihat tepat apa yang macet.
Step 4: Persist progress after every step. Setelah langkah selesai, simpan state baru beserta output kunci. Jika proses restart, ia harus melanjutkan dari langkah terakhir yang selesai, bukan mulai dari awal.
Step 5: Route to a dead-letter record and support reprocessing. Saat pengulangan habis, pindahkan item ke state dead-letter dan simpan konteks penuh: input, error terakhir, nama langkah, hitungan percobaan, dan timestamp. Reprocessing harus disengaja: perbaiki data atau konfigurasi dulu, lalu re-queue mulai dari langkah tertentu.
Step 6: Define dashboard fields and operator actions. Dasbor yang baik menjawab “apa yang gagal, di mana, dan apa yang bisa saya lakukan selanjutnya?” Di AppMaster, Anda bisa membangun ini sebagai admin web app sederhana yang didukung tabel workflow Anda.
Field dan aksi kunci untuk disertakan:
Onboarding karyawan adalah uji yang bagus. Ia mencampur persetujuan, sistem eksternal, dan orang yang offline. Alur sederhana: HR mengisi form new hire, manajer menyetujui, IT membuat akun, dan karyawan baru menerima pesan sambutan.
Buat status mudah dibaca. Saat seseorang membuka record, mereka harus langsung melihat perbedaan antara “Menunggu persetujuan” dan “Mengulang penyiapan akun.” Satu baris kejelasan bisa menghemat satu jam tebak-tebakan.
Set status yang jelas untuk UI:
Retry cocok pada langkah yang bergantung jaringan atau API pihak ketiga. Provisioning akun (email, SSO, Slack), mengirim email/SMS, dan memanggil API internal adalah kandidat retry yang baik. Tampilkan counter retry dan batasi (mis. ulangi sampai lima kali dengan delay meningkat, lalu berhenti).
Penanganan dead-letter untuk masalah yang tidak akan sembuh sendiri: tidak ada manajer di form, alamat email tidak valid, atau permintaan akses yang bertentangan dengan kebijakan. Saat Anda memindahkan run ke dead-letter, simpan konteks: field mana yang gagal validasi, respons API terakhir, dan siapa yang dapat memberikan override.
Operator harus punya beberapa aksi sederhana: perbaiki data (tambah manajer, koreksi email), jalankan ulang satu langkah yang gagal (bukan seluruh workflow), atau batalkan dengan bersih (dan urus undo setup parsial jika perlu).
Dengan AppMaster, Anda bisa memodelkan ini di Business Process Editor, menyimpan counter retry di data, dan membangun layar operator di web UI builder yang menampilkan status, error terakhir, dan tombol untuk mengulang langkah yang gagal.
Sebagian besar masalah keandalan bisa diprediksi: sebuah langkah berjalan dua kali, retry berputar pada jam 2 pagi, atau item “macet” tidak punya petunjuk apa yang terakhir terjadi. Daftar periksa mencegah ini menjadi tebak-tebakan.
Pemeriksaan cepat yang menangkap sebagian besar masalah sejak dini:
Jika Anda hanya bisa memperbaiki satu hal, tingkatkan visibilitas. Banyak “bug workflow” sebenarnya adalah masalah “kita tidak tahu apa yang sedang dilakukan.” Dasbor Anda harus menunjukkan apa yang terakhir terjadi, apa yang akan terjadi selanjutnya, dan kapan.
Tampilan operator praktis meliputi status saat ini, pesan error terakhir, jumlah percobaan, waktu pengulangan berikutnya, dan satu aksi jelas (retry now, mark as resolved, atau send to manual review). Buat aksi aman secara default: jalankan ulang satu langkah, bukan seluruh workflow.
Langkah selanjutnya:
Perlakukan ini sebagai daftar periksa hidup. Setiap kali Anda menambah langkah baru, jalankan pemeriksaan ini sebelum mencapai produksi.
Long-running workflows bisa berhasil selama berjam-jam lalu gagal di akhir, meninggalkan perubahan parsial. Mereka juga bergantung pada hal yang bisa berubah saat workflow berjalan, seperti ketersediaan pihak ketiga, kredensial, bentuk data, dan waktu respons manusia.
Jaga set status kecil dan mudah dibaca agar operator bisa memahaminya sekilas. Default yang baik adalah: queued, running, waiting, succeeded, dan failed — dengan “waiting” dipisahkan jelas dari “running” sehingga jeda sehat tidak dianggap hang.
Simpan informasi yang membuat status menjadi dapat ditindaklanjuti: status saat ini, kapan terakhir berubah, status sebelumnya, dan alasan singkat saat menunggu atau gagal. Jika ada pengulangan, simpan juga jumlah percobaan dan waktu pengulangan berikutnya sehingga tidak perlu menebak apa yang akan terjadi.
Agar tidak memicu alarm palsu dan insiden yang terlewat. “Waiting for approval” atau “waiting for a webhook” bisa sehat, sementara “running selama enam jam” mungkin menandakan langkah macet. Memisahkan keduanya membantu alert dan keputusan operator.
Ulangi kesalahan yang kemungkinan bersifat sementara, seperti timeouts, rate limits, dan gangguan singkat. Jangan ulangi kesalahan yang jelas permanen, seperti input tidak valid, izin hilang, atau penolakan pembayaran—mengulang hanya membuang sumber daya dan bisa berisiko.
Penghitungan pengulangan per langkah mencegah satu integrasi yang bermasalah menghabiskan semua kesempatan untuk keseluruhan workflow. Ini juga mempermudah diagnosis karena Anda tahu langkah mana yang gagal dan berapa kali dicoba.
Pilih pola backoff yang sesuai risiko, dan selalu batasi agar jeda tidak membesar tanpa batas. Buat aturan berhenti eksplisit seperti jumlah maksimum percobaan atau total waktu maksimum, lalu catat alasan kegagalan dan waktu pengulangan berikutnya agar kepemilikan jelas.
Anggap setiap langkah dapat dijalankan ulang karena pengulangan, replay, atau webhook ganda. Cara umum: gunakan kunci idempotensi yang stabil per langkah, simpan record “step started” sebelum panggilan eksternal, dan simpan hasil segera setelah mendapat respons sehingga pengulangan dapat memakai hasil tersebut daripada mengulangi aksi.
Item dead-letter adalah yang dipindahkan keluar dari jalur normal setelah pengulangan habis agar tidak memblokir yang lain. Simpan konteks cukup untuk memperbaiki dan memproses ulang dengan aman: identifier, input (atau snapshot aman), di mana gagal, riwayat percobaan, dan respons error dari dependency — jangan cuma menyimpan pesan error yang samar.
Dasbor yang cepat dipakai menunjukkan di mana item itu, mengapa sampai di situ, dan apa yang akan terjadi selanjutnya. Gunakan field konsisten seperti workflow ID, langkah saat ini, status, waktu dalam status, kesalahan terakhir, dan correlation ID. Aksi yang tersedia harus aman secara default, seperti mengulang satu langkah, pause/resume, atau mengirim ke manual review, dan aksi berisiko harus diberi label jelas.



Eksperimen dengan AppMaster dengan paket gratis.
Saat Anda siap, Anda dapat memilih langganan yang tepat.


