उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
Soft delete बनाम hard delete: जानें कैसे इतिहास रखें, टूटे हुए रेफरेंसेज़ से बचें, और प्राइवेसी हटाने की माँगों को पूरा करते हुए स्पष्ट नियम अपनाएँ।
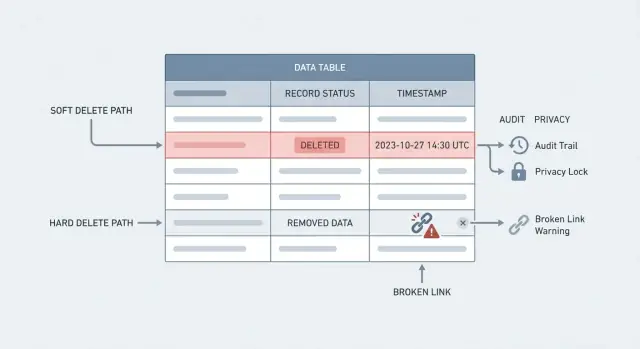
“डिलीट” दो बहुत अलग बातों का मतलब हो सकता है। इन्हें मिलाना टीमों के लिए इतिहास खो देना या प्राइवेसी अनुरोधों को पूरा न करना बन सकता है।
एक hard delete वही है जो ज्यादातर लोग सोचते हैं: रो (row) डेटाबेस से हटा दिया जाता है। बाद में क्वेरी करें तो वह गायब होगा। यह असल में हटाना है, लेकिन यह संदर्भ तोड़ भी सकता है (जैसे किसी ऑर्डर का लिंक हटाए गए ग्राहक की ओर इशारा करता है) जब तक आप इसके लिए डिज़ाइन नहीं करते।
एक soft delete रो को रखता है, लेकिन उसे deleted के रूप में मार्क कर देता है, आमतौर पर deleted_at या is_deleted जैसे फ़ील्ड के साथ। आपकी ऐप इसे गायब मानती है, पर डेटा रिपोर्ट, सपोर्ट, और ऑडिट के लिए मौजूद रहता है।
soft delete vs hard delete के पीछे व्यापार सरल है: इतिहास बनाम असली हटाना। Soft delete इतिहास बचाता है और “undo” संभव बनाता है। Hard delete आपकी स्टोरेज घटाता है, जो प्राइवेसी, सुरक्षा और कानूनी नियमों के लिए मायने रखता है।
डिलीट केवल स्टोरेज को नहीं बदलते। ये यह भी बदलते हैं कि आपकी टीम बाद में क्या जवाब दे सकती है: एक सपोर्ट एजेंट जो पिछले शिकायत को समझने की कोशिश कर रहा है, फाइनेंस जो बिलिंग reconcile कर रहा है, या कंप्लायंस यह देख रहा है कि किसने कब क्या बदला। अगर डेटा जल्दी गायब हो जाए तो रिपोर्ट बदल जाती हैं, टोटल मेल नहीं खाते, और जांच अनुमान पर निर्भर हो जाती है।
एक उपयोगी मानसिक मॉडल:
व्यवहार में, आप किसी यूज़र अकाउंट को soft delete कर सकते हैं ताकि लॉगिन बंद हो जाए और ऑर्डर हिस्ट्री बरकरार रहे, फिर रिटेंशन पीरियड या सत्यापित GDPR right to erasure अनुरोध के बाद व्यक्तिगत फ़ील्ड्स को hard delete (या anonymize) कर दें।
कोई टूल यह निर्णय आपके लिए नहीं लेता। भले ही आप AppMaster जैसे no-code प्लेटफॉर्म से बना रहे हों, असली काम यह तय करना है कि हर टेबल के लिए “deleted” का क्या मतलब है और यह सुनिश्चित करना कि हर स्क्रीन, रिपोर्ट और API एक ही नियम का पालन करते हैं।
ज़्यादातर टीमें डिलीट्स तभी नोटिस करती हैं जब कुछ गड़बड़ हो जाता है। एक “सरल” डिलीट संदर्भ, इतिहास, और आपकी समझने की क्षमता मिटा सकता है।
Hard deletes जोखिम भरे होते हैं क्योंकि इन्हें undo करना मुश्किल होता है। कोई गलत बटन दबा देता है, ऑटोमैटेड जॉब में बग आ जाता है, या सपोर्ट एजेंट गलत प्लेबुक फॉलो कर देता है। साफ़ बैकअप और रिकवर प्रक्रिया के बिना वह नुकसान स्थायी हो जाता है, और बिज़नेस इम्पैक्ट जल्दी दिखने लगता है।
ब्रोकन रेफरेंसेज़ अगला सरप्राइज होते हैं। आप एक ग्राहक को हटा देते हैं, पर उनके ऑर्डर अभी भी मौजूद हैं। अब ऑर्डर किसी खाली आइटम की ओर इशारा कर रहे हैं, इनवॉइस बिलिंग नाम नहीं दिखा पाती, और पोर्टल रिलेटेड डेटा लोड करते समय एरर कर सकता है। भले ही foreign key constraints हों, “फिक्स” और भी बुरा हो सकता है: cascading deletes अनजाने में ज़्यादा मिटा सकते हैं।
एनालिटिक्स और रिपोर्टिंग भी गड़बड़ा जाती है। जब पुराने रिकॉर्ड गायब हो जाते हैं, मेट्रिक्स रेट्रोएक्टिवली बदलते हैं। पिछले महीने का conversion rate खिसकता है, lifetime value घटता है, और ट्रेंड लाइन में ऐसे गैप दिखते हैं जिन्हें कोई समझा नहीं पाता। टीम नंबर्स पर बहस करने लगती है बजाय कि निर्णय लेने के।
सपोर्ट और कंप्लायंस वहां सबसे ज़्यादा चोट पहुँचाते हैं। ग्राहक पूछते हैं, “मुझे क्यों चार्ज किया गया?” या “किसने मेरा प्लान बदला?” अगर रिकॉर्ड गया हुआ है तो आप टाइमलाइन reconstruct नहीं कर सकते। आप वह ऑडिट ट्रेल खो देते हैं जो ये बेसिक सवाल जवाब कर सकता है कि क्या बदला, कब, और किसने।
soft delete vs hard delete चर्चा के पीछे सामान्य failure modes:
जब किसी रिकॉर्ड का लम्बे समय तक मूल्य हो या वह दूसरे डेटा से जुड़ा हो, तो soft delete आम तौर पर सबसे सुरक्षित विकल्प है। रो हटाने के बजाय आप उसे deleted के रूप में चिह्नित करते हैं (जैसे deleted_at या is_deleted) और सामान्य व्यू से छिपा देते हैं। soft delete vs hard delete निर्णय में यह डिफ़ॉल्ट भविष्य में सरप्राइज कम करता है।
यह खासकर वहां काम आता है जहाँ आपको audit trail in databases चाहिए। ऑपरेशंस टीम अक्सर सरल सवालों का जवाब देनी चाहिए जैसे “किसने इस ऑर्डर को बदला?” या “क्यों इस इनवॉइस को कैंसिल किया गया?” अगर आप जल्दी hard delete कर देते हैं तो आप वित्त, सपोर्ट, और कंप्लायंस रिपोर्टिंग के लिए ज़रूरी सबूत खो देते हैं।
Soft delete “undo” भी संभव बनाता है। एडमिन्स गलती से बंद किए गए टिकट को restore कर सकते हैं, आर्काइव किए गए प्रोडक्ट को वापस ला सकते हैं, या गलत स्पैम रिपोर्ट के बाद यूज़र जनरेटेड कंटेंट recover कर सकते हैं। अगर डेटा फिजिकली गया हुआ हो तो यह रिस्टोर फ्लो देना मुश्किल है।
रिलेशनशिप्स भी बड़ा कारण हैं। किसी पैरेंट रो को hard delete करना foreign key constraints तोड़ सकता है या रिपोर्ट में confusing gaps छोड़ सकता है। Soft delete के साथ joins स्थिर रहते हैं और ऐतिहासिक totals consistent रहते हैं (दैनिक राजस्व, पूरे हुए ऑर्डर, रिस्पॉन्स टाइम स्टैट्स)।
Soft delete बिज़नेस रिकॉर्ड्स के लिए अच्छा डिफ़ॉल्ट है जैसे सपोर्ट टिकट, संदेश, ऑर्डर, इनवॉइस, ऑडिट लॉग, एक्टिविटी हिस्ट्री, और यूज़र प्रोफाइल (कम-से-कम तब तक जब तक अंतिम हटाने की पुष्टि न हो)।
उदाहरण: एक सपोर्ट एजेंट एक ऑर्डर नोट को “डिलीट” कर देता है जिसमें गलती है। Soft delete होने पर नोट normal UI से गायब हो जाता है, पर सुपरवाइज़र शिकायत के दौरान उसे अभी भी देख सकते हैं और फाइनेंस रिपोर्ट समझने लायक रहती है।
Soft delete कई ऐप्स के लिए बढ़िया डिफ़ॉल्ट है, पर ऐसे मौके होते हैं जब डेटा रखना (यहाँ तक कि छिपाकर भी) गलत चुनाव है। Hard delete का मतलब है रिकॉर्ड सचमुच हटाया गया और यह कभी-कभी कानूनी, सुरक्षा, या लागत की ज़रूरतों के लिए एकमात्र विकल्प होता है।
सबसे स्पष्ट मामला प्राइवेसी और अनुबंधिक दायित्व है। अगर किसी ने GDPR right to erasure का उपयोग किया है, या आपका कॉन्ट्रैक्ट किसी अवधि के बाद हटाने का वादा करता है, तो “marked as deleted” अक्सर पर्याप्त नहीं माना जाता। आपको रो, उस की प्रतियाँ, और किसी भी स्टोर्ड आइडेंटिफ़ायर को हटाना पड़ सकता है जो व्यक्ति की पहचान कर सके।
सुरक्षा भी एक कारण है। कुछ डेटा बहुत संवेदनशील होते हैं और उन्हें रखना जोखिम भरा होता है: raw access tokens, password reset codes, private keys, one-time verification codes, या unencrypted secrets। इतिहास के लिए इन्हें रखना आमतौर पर जोखिम के लायक नहीं होता।
Hard delete स्केल के लिहाज़ से भी सही हो सकता है। अगर आपके पास बड़े पुराने इवेंट्स, लॉग्स, या टेलीमेट्री टेबल हैं, तो soft delete धीरे-धीरे डेटाबेस बड़ा कर देता है और क्वेरीज़ धीमी कर देता है। एक नियोजित purge पॉलिसी सिस्टम को रिस्पॉन्सिव और लागत पूर्वानुमान योग्य रखती है।
Hard delete अक्सर टेम्पररी डेटा (कॅश, सेशन्स, ड्राफ्ट इम्पोर्ट्स), शॉर्ट-लाइव्ड सिक्योरिटी आर्टिफैक्ट्स (reset tokens, OTPs, invite codes), टेस्ट/डेमो अकाउंट्स, और बड़े ऐतिहासिक डेटासेट्स के लिए उचित होता है जहाँ केवल aggregated stats की ज़रूरत हो।
व्यवहारिक तरीका है “बिज़नेस हिस्ट्री” और “पर्सनल डेटा” को अलग करना। उदाहरण के लिए, अकाउंटिंग के लिए इनवॉइस रखें, पर व्यक्ति पहचान वाले यूज़र प्रोफ़ाइल फ़ील्ड्स को hard-delete या anonymize कर दें।
अगर आपकी टीम soft delete vs hard delete पर बहस कर रही है, तो एक सरल परीक्षण करें: अगर डेटा रखना कानूनी या सुरक्षा जोखिम बनाता है, तो hard delete (या irreversible anonymization) को जीतने दें।
Soft delete तब सबसे बेहतर काम करता है जब वह बोअरिंग और predictable हो। लक्ष्य सरल है: रिकॉर्ड डेटाबेस में रहे, पर ऐप के सामान्य हिस्से उसे “गया” मानें।
आप तीन सामान्य पैटर्न देखेंगे: deleted_at timestamp, is_deleted flag, या status enum। कई टीमें deleted_at पसंद करती हैं क्योंकि यह एक ही बार में दो सवालों का जवाब देता है: क्या यह हटाया गया है, और कब हुआ।
अगर आपके पास पहले से कई लाइफसाइकल स्टेट्स हैं (active, pending, suspended), तो status enum काम कर सकता है, पर “deleted” को “archived” और “deactivated” से अलग रखें। ये अलग चीजें हैं:
Soft delete vs hard delete अक्सर यूनिक फील्ड्स जैसे ईमेल, यूज़रनेम, या ऑर्डर नंबर पर अटकता है। अगर कोई यूज़र deleted है पर उनका ईमेल अभी भी स्टोर है और यूनिक है, तो वही व्यक्ति फिर से साइन अप नहीं कर पाएगा।
दो सामान्य फिक्स हैं: या तो यूनिकनेस केवल non-deleted रो पर लागू करें, या delete के समय वैल्यू को rewrite कर दें (उदाहरण के लिए, रैंडम suffix जोड़ दें)। आपका चुनाव प्राइवेसी और ऑडिट ज़रूरतों पर निर्भर करेगा।
निर्धारित करें कि अलग-अलग ऑडियंस क्या देख सकती है। एक सामान्य नियम सेट होता है: सामान्य यूज़र्स कभी deleted रिकॉर्ड नहीं देखते, सपोर्ट/एडमिन यूज़र उन्हें स्पष्ट लेबल के साथ देख सकते हैं, और exports/reports केवल अनुरोध पर उन्हें शामिल करते हैं।
“हर कोई फ़िल्टर जोड़ना याद रखेगा” पर निर्भर न रहें। नियम को एक ही जगह रखें: व्यूज़, डिफ़ॉल्ट क्वेरीज़, या आपके डेटा एक्सेस लेयर में। AppMaster में काम कर रहे हैं तो आमतौर पर यह आपके endpoints और business processes में फ़िल्टर bake करने जैसा होता है, ताकि deleted रो गलत स्क्रीन में वापस न आ जाएँ।
मतलब लिखकर रखें — एक छोटा इंटरनल नोट (या स्कीमा कमेंट)। भविष्य का आप तब धन्यवाद देगा जब “deleted”, “archived”, और “deactivated” एक ही मीटिंग में आ जाएँ।
रिलेशनशिप्स के माध्यम से ऐप्स को अक्सर डिलीट्स से नुकसान होता है। कोई रिकॉर्ड शायद अकेला नहीं होता: यूज़र्स के ऑर्डर होते हैं, टिकट्स के कमेंट्स होते हैं, प्रोजेक्ट्स के फाइल्स होते हैं। soft delete vs hard delete में मुश्किल यह है कि रेफरेंसेज़ को consistent रखना जबकि प्रोडक्ट को यह दिखाना कि आइटम “गया” है।
Foreign keys आपको broken references से बचाते हैं, पर हर विकल्प अलग मायना रखता है:
अगर आप soft delete उपयोग करते हैं तो RESTRICT अक्सर सबसे सुरक्षित डिफ़ॉल्ट होता है। आप रो रखते हैं, इसलिए keys वैलिड रहते हैं, और आप बच्चों को खाली pointing करने से बच जाते हैं।
Soft delete आमतौर पर foreign keys नहीं बदलता। इसके बजाय, आप deleted parents को ऐप और रिपोर्ट में filter out करते हैं। अगर एक ग्राहक soft-deleted है, उनके इनवॉइस अभी भी सही तरह join करें, पर स्क्रीन ड्रॉपडाउन में ग्राहक नहीं दिखना चाहिए।
attachments, comments, और activity logs के लिए तय करें कि यूज़र के लिए “डिलीट” का क्या मतलब है। कुछ टीमें shell रखती हैं पर रिस्की हिस्सों को हटा देती हैं: प्राइवेसी आवश्यक होने पर attachment content को placeholder से बदल दें, comments में author को deleted user के रूप में मार्क या anonymize करें, और activity logs को immutable रखें।
Joins और रिपोर्टिंग के लिए स्पष्ट नियम चाहिए: क्या deleted rows शामिल होंगे? कई टीमें दो मानक क्वेरीज रखती हैं: एक “active only” और एक “including deleted”, ताकि सपोर्ट और रिपोर्टिंग महत्वपूर्ण इतिहास छिपा न दें।
व्यवहारिक पॉलिसी अक्सर दिन-प्रतिदिन की गलतियों के लिए soft delete और कानूनी/प्राइवेसी जरूरतों के लिए hard delete इस्तेमाल करती है। अगर आप इसे सिर्फ एक निर्णय (soft delete vs hard delete) मानते हैं तो आप मध्य मार्ग को छोड़ देते हैं: इतिहास कुछ समय के लिए रखें, फिर जो आवश्यक है उसे purge कर दें।
डेटा को कुछ buckets में बाँट कर शुरू करें। “User profile” व्यक्तिगत है, “transactions” वित्तीय रिकॉर्ड हैं, और “logs” सिस्टम हिस्ट्री हैं। हर bucket को अलग नियम चाहिए।
एक छोटा प्लान जो ज्यादातर टीमों में काम करता है:
मान लें एक ग्राहक खाता बंद करने को कहता है। तुरंत यूज़र रिकॉर्ड को soft delete करें ताकि वे साइन इन न कर सकें और आप रेफरेंसेज़ नहीं तोड़ें। फिर उन व्यक्तिगत फ़ील्ड्स को anonymize करें जिन्हें रखना ठीक नहीं (नाम, ईमेल, फोन), जबकि अकाउंटिंग के लिए आवश्यक गैर‑व्यक्तिगत ट्रांजैक्शन तथ्य रखें। अंत में, एक शेड्यूल्ड purge जॉब अंतिम पीरियड के बाद जो कुछ अभी भी व्यक्तिगत है उसे हटा दे।
टीमें मुश्किल में इसलिए पड़ती हैं क्योंकि वे पद्धति असमान रूप से लागू करती हैं। एक सामान्य पैटर्न यह है कि कागज़ पर तो “soft delete vs hard delete” है, पर व्यवहार में “एक स्क्रीन में छिपाओ और बाकी भूल जाओ” होता है।
एक आसान गलती: आप deleted records UI में छिपाते हैं, पर वे API, CSV एक्सपोर्ट, एडमिन टूल्स, या डेटा सिंक जॉब्स के ज़रिये दिखने लगते हैं। यूज़र जल्दी नोटिस करते हैं जब एक “deleted” ग्राहक ईमेल लिस्ट या मोबाइल सर्च में दिखाई दे।
रिपोर्ट्स और सर्च भी एक और जाल हैं। अगर रिपोर्ट क्वेरीज लगातार deleted rows को फ़िल्टर नहीं करतीं, तो टोटल्स बदलते हैं और डैशबोर्ड अनबीलेवबल हो जाते हैं। सबसे बुरे मामले बैकग्राउंड जॉब्स होते हैं जो deleted आइटम्स को re-index या re-send कर देते हैं क्योंकि उन्होंने वही नियम नहीं लागू किए।
Hard deletes भी ज़्यादा आगे जा सकते हैं। एक single cascading delete ऑर्डर्स, इनवॉइस, संदेश, और लॉग्स को मिटा सकता है जो आपको वास्तव में एक ऑडिट ट्रेल के लिए चाहिए थे। अगर आप hard delete कर रहे हैं, तो स्पष्ट रूप से बताएं कि क्या गायब हो सकता है और क्या बनाए रखना या anonymize करना है।
Soft delete के साथ यूनिक कंस्ट्रेंट्स सूक्ष्म दर्द पैदा कर सकते हैं। अगर कोई यूज़र अपना अकाउंट डिलीट करे और फिर उसी ईमेल से फिर से साइन अप करने कोशिश करे, साइन-अप फ़ेल हो सकता है अगर पुराना रो अभी भी यूनिक ईमेल रखता है। इसको पहले से प्लान करें।
कम्प्लायंस टीमें पूछेंगी: क्या आप साबित कर सकते हैं कि deletion हुआ और कब? “हमें लगता है कि हटाया गया” कई डेटा रिटेंशन रिव्यू पास नहीं करेगा। एक deletion timestamp रखें, किसने/क्या ट्रिगर किया और एक immutable log एंट्री।
शिप करने से पहले पूरे surface area की sanity जांच करें: API, एक्सपोर्ट, सर्च, रिपोर्ट्स, और बैकग्राउंड जॉब्स। साथ ही तालिका दर तालिका cascades की समीक्षा करें, और पुष्टि करें कि यूज़र वही यूनिक डेटा (जैसे ईमेल या यूज़रनेम) फिर से बना सकता है जब यह आपके प्रोडक्ट के वादे का हिस्सा हो।
soft delete vs hard delete चुनने से पहले अपनी ऐप का असली व्यवहार वेरिफ़ाई करें, सिर्फ़ स्कीमा नहीं।
फिर privacy path end-to-end टेस्ट करें। क्या आप GDPR right to erasure अनुरोध पूरा कर सकते हैं across copies, exports, search indexes, analytics tables, और integrations, न कि सिर्फ़ मुख्य डेटाबेस में?
एक व्यावहारिक तरीका यह है कि staging में एक “delete user” ड्राइक रन चलाएँ और डेटा ट्रेल को फॉलो करें।
एक ग्राहक लिखता है: “कृपया मेरा अकाउंट डिलीट कर दें।” आपके पास ऐसी इनवॉइसें भी हैं जिन्हें अकाउंटिंग और चार्जबैक चेक के लिए रखना ज़रूरी है। यही जगह है जहाँ soft delete vs hard delete व्यावहारिक बन जाता है: आप एक्सेस और व्यक्तिगत विवरण हटा सकते हैं पर बिज़नेस रिकॉर्ड्स रख सकते हैं जिन्हें व्यवसाय रखना चाहिए।
“अकाउंट” को “बिलिंग रिकॉर्ड” से अलग करें। अकाउंट लॉगिन और पहचान के बारे में है। बिलिंग रिकॉर्ड पहले ही हुए लेनदेन के बारे में है।
एक साफ़ तरीका:
सपोर्ट टिकट्स और संदेश अक्सर बीच में रहते हैं। अगर संदेश कंटेंट में व्यक्तिगत डेटा है तो आपको टेक्स्ट के हिस्सों को redact करना पड़ सकता है, attachments हटाने पड़ सकते हैं, और टिकट shell (timestamps, category, resolution) क्वालिटी ट्रैकिंग के लिए रखना पड़ सकता है। अगर आपका प्रोडक्ट संदेश भेजता है (email/SMS, Telegram), तो आउटबाउंड identifiers भी हटा दें ताकि व्यक्ति को फिर से संपर्क न किया जा सके।
सपोर्ट अब क्या देख सकता है? आम तौर पर इनवॉयस नंबर, तिथियाँ, राशियाँ, स्थिति, और एक नोट कि यूज़र डिलीट हुआ और कब। जो नहीं दिखा चाहिए वह है कोई भी पहचान बताने वाली चीज़: लॉगिन ईमेल, पूरा नाम, पते, सेव किए गए पेमेंट मेथड डिटेल्स, या सक्रिय सेशन्स।
डिलीशन निर्णय तभी टिकते हैं जब उन्हें लिखा गया हो और प्रोडक्ट में एक ही तरीके से लागू किया गया हो। soft delete vs hard delete को पहले पॉलिसी प्रश्न के रूप में मानें, न कि सिर्फ़ एक कोडिंग ट्रिक के रूप में।
एक सरल डेटा रिटेंशन पॉलिसी से शुरू करें जिसे टीम का कोई भी सदस्य पढ़ सके। इसमें बताएँ कि आप क्या रखते हैं, कितने समय तक रखते हैं, और क्यों रखते हैं। “क्यों” महत्वपूर्ण है क्योंकि यह दो लक्ष्यों के संघर्ष में बताता है कि क्या जीतता है (उदा., सपोर्ट इतिहास बनाम प्राइवेसी अनुरोध)।
अच्छा डिफ़ॉल्ट अक्सर यह होता है: रोज़मर्रा के बिज़नेस रिकॉर्ड्स के लिए soft delete (orders, tickets, projects), सच में संवेदनशील डेटा के लिए hard delete (tokens, secrets) और वह जो आप नहीं रखना चाहिए।
एक बार नीति स्पष्ट हो जाए, उन फ़्लो को बनाएं जो इसे लागू करें: restore के लिए एक “trash” व्यू, irreversible deletion से पहले एक “purge queue” और कौन‑कब‑क्या किया इसका audit व्यू। “Purge” को “delete” से कठिन बनाएं ताकि यह गलती से न हो।
अगर आप इसे AppMaster (appmaster.io) में लागू कर रहे हैं, तो Data Designer में soft-delete फ़ील्ड मॉडल करना और delete, restore, और purge लॉजिक को एक Business Process में केंद्रीकृत करना मदद करता है, ताकि वही नियम स्क्रीन और API endpoints में एक समान लागू हों।
A hard delete physically removes the row from the database, so future queries can’t find it. A soft delete keeps the row but marks it as deleted (often with deleted_at), so your app hides it in normal screens while preserving history for support, audits, and reporting.
Use soft delete by default for business records you may need to explain later, like orders, invoices, tickets, messages, and account activity. It reduces accidental data loss, keeps relationships intact, and makes a safe “undo” possible without restoring from backups.
Hard delete is best when keeping the data creates privacy or security risk, or when retention rules require true removal. Common examples are password reset tokens, one-time codes, sessions, API tokens, and personal data that must be erased after a verified request or after a retention period.
A deleted_at timestamp is a common choice because it tells you both that the record is deleted and when it happened. It also supports practical workflows like retention windows (purge after 30 days) and audit questions (“when was this removed?”) without needing a separate log just for timing.
Unique fields like email or username often block re-signup if the “deleted” row still holds the unique value. A typical fix is to enforce uniqueness only for non-deleted rows, or to rewrite the unique field during deletion so it no longer collides, depending on your privacy and audit needs.
Hard deleting a parent record can orphan children (like orders) or trigger cascades that delete far more than intended. Soft delete usually avoids broken references because keys stay valid, but you still need consistent filtering so deleted parents don’t appear in dropdowns or user-facing joins.
If you hard delete historical rows, past totals can change, trends can develop gaps, and finance numbers may stop matching what people saw before. Soft delete helps preserve history, but only if reports and analytics queries clearly define whether they include deleted rows and apply that rule consistently.
“Soft deleted” often isn’t enough for right-to-erasure requests because the personal data may still exist in the database and backups. A practical pattern is to remove access immediately, then hard delete or irreversibly anonymize personal identifiers while keeping non-personal transaction facts you must retain for accounting or disputes.
Restoring should bring the record back to a safe, valid state without reviving sensitive items that should stay gone, like sessions or reset tokens. It also needs clear rules for related data, so you don’t restore an account but leave it missing required relationships or permissions.
Centralize delete, restore, and purge behavior so every API, screen, export, and background job applies the same filtering rule. In AppMaster, this is typically done by adding soft-delete fields in the Data Designer and implementing the logic once in a Business Process so new endpoints don’t accidentally expose deleted data.



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


