उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
सिखें कि कैसे स्पष्ट स्टेट, मेंटेन करने योग्य नियम, और सरल एस्केलेशन पथ बनाकर SLA टाइमर और एस्केलेशंस का मॉडल तैयार करें ताकि वर्कफ़्लो ऐप बाद में बदलना आसान रहे।
समय-आधारित नियम अक्सर सरल शुरू होते हैं: “अगर टिकट को 2 घंटे में कोई जवाब नहीं मिले तो किसी को सूचित करो।” फिर वर्कफ़्लो बढ़ता है, टीमें अपवाद जोड़ती हैं, और अचानक कोई भी सुनिश्चित नहीं होता कि क्या होगा। इसी तरह SLA टाइमर और एस्केलेशन भूलभुलैया बन जाते हैं।
चलती चीज़ों के नाम स्पष्ट रखने से मदद मिलती है।
एक टाइमर वह घड़ी है जिसे आप किसी इवेंट के बाद शुरू करते हैं (या शेड्यूल करते हैं), जैसे “टिकट को Waiting for Agent में भेजा गया।” एक एस्केलेशन वह कार्य है जो आप घड़ी के किसी थ्रेशोल्ड पर पहुँचने पर करते हैं, जैसे लीड को सूचित करना, प्राथमिकता बदलना, या काम फिर से असाइन करना। एक ब्रीच वह दर्ज रिकॉर्ड है जो कहता है, “हमने SLA को मिस कर दिया,” जिसे आप रिपोर्टिंग, अलर्ट और फॉलो-अप के लिए उपयोग करते हैं।
समस्या उस समय दिखती है जब समय-लॉजिक ऐप में बिखर जाती है: “अपडेट टिकट” फ्लो में कुछ चेक, रात में चलने वाली जॉब में और बाद में किसी विशेष ग्राहक के लिए एक-ऑफ नियम। हर टुकड़ा अपने आप में समझ में आता है, लेकिन मिलकर वे आश्चर्य पैदा करते हैं।
टिपिकल लक्षण:
लक्ष्य यह है कि व्यवहार भविष्यवाणी योग्य रहे और बाद में बदलना आसान रहे: SLA टायमिंग का एक स्पष्ट स्रोत, रिपोर्टेबल स्पष्ट ब्रीच स्टेट्स, और एस्केलेशन स्टेप्स जिन्हें बदलाव के लिए पूरे विज़ुअल लॉजिक में खोजने की ज़रूरत न हो।
किसी भी टाइमर को बनाने से पहले, उस वादे को लिखें जिसे आप नाप रहे हैं। कई गंदा लॉजिक इसी कारण आता है कि सभी संभावित समय नियमों को एक ही बार में कवर करने की कोशिश की जाती है।
सामान्य SLA प्रकार एक जैसे सुनाई देते हैं पर अलग चीज़ें मापते हैं:
फिर तय करें कि “समय” का क्या मतलब है। Calendar time 24/7 गिनता है। Working time केवल परिभाषित व्यापारिक घंटों को गिनता है (उदा., सोम-शुक्र, 9-6)। अगर आपको सचमुच working time की ज़रूरत नहीं है तो शुरुआत में उससे बचें — यह छुट्टियाँ, टाइमज़ोन और आंशिक दिन जैसे एज केस जोड़ता है।
फिर पॉज़ के बारे में स्पष्ट हों। पॉज़ सिर्फ “स्टेटस बदला” नहीं है — यह एक नियम है जिसका एक मालिक होता है। कौन इसे पॉज़ कर सकता है (केवल एजेंट, केवल सिस्टम, ग्राहक क्रिया)? कौन से स्टेटस इसे पॉज़ करते हैं (Waiting on Customer, On Hold, Pending Approval)? क्या इसे रेज़्यूम करता है? रेज़्यूम होने पर क्या शेष समय से जारी होगा या टाइमर रीस्टार्ट होगा?
अंत में, प्रॉडक्ट शब्दों में ब्रीच का क्या अर्थ है, यह परिभाषित करें। एक ब्रीच को ठोस तरीके से स्टोर और क्वेरी करने लायक होना चाहिए, जैसे:
breached_at) (जब डेडलाइन मिस हुई)उदाहरण: “First response SLA breached” का मतलब हो सकता है कि टिकट को Breached स्टेट मिल जाए, breached_at टाइमस्टैम्प दर्ज हो, और escalation_level 1 पर सेट हो।
अगर आप चाहते हैं कि SLA टाइमर और एस्केलेशन पढ़ने में सरल रहें, तो SLA को एक छोटा स्टेट मशीन मानें। जब “सच” छोटी-छोटी चेक में फैला होता है (if now > due, if priority is high, if last reply is empty), तो विज़ुअल लॉजिक जल्दी जटिल हो जाता है और छोटे बदलाव चीज़ें तोड़ देते हैं।
एक छोटी, सहमत SLA स्टेट सेट के साथ शुरू करें जिसे हर वर्कफ़्लो कदम समझ सके। कई टीमों के लिए ये अधिकतर मामलों को कवर करते हैं:
एक सरल breached = true/false फ़्लैग अक्सर पर्याप्त नहीं होता। आपको यह जानने की भी ज़रूरत होती है कि कौन सी SLA ब्रीच हुई (first response बनाम resolution), क्या वर्तमान में पॉज़ है, और क्या आपने पहले ही एस्केलेशन किया है। बिना उस संदर्भ के, लोग टिप्पणियों, टाइमस्टैम्प और स्टेटस नामों से अर्थ निकालने लगते हैं — और यही जगह लॉजिक नाज़ुक हो जाता है।
स्टेट को स्पष्ट रूप से रखें और उन टाइमस्टैम्पों को स्टोर करें जो उसे समझाएँ। तब फैसले सरल रहेंगे: आपका evaluator रिकॉर्ड पढ़ेगा, अगला स्टेट तय करेगा, और बाकी सब उसके स्टेट पर प्रतिक्रिया करेगा।
स्टेट के साथ स्टोर करने लायक उपयोगी फ़ील्ड:
started_at और due_at (हम कौन सी घड़ी चला रहे हैं, और कब ड्यू है?)breached_at (कब यह वास्तव में सीमा पार हुई?)paused_at और paused_reason (घड़ी क्यों रुकी?)breach_reason (किस नियम ने ब्रीच ट्रिगर किया, साधारण शब्दों में)last_escalation_level (ताकि आप एक ही लेवल को दोबारा न नोटिफ़ाई करें)उदाहरण: जब टिकट “Waiting on customer” में जाता है, SLA स्टेट को Paused सेट करें, paused_reason = "waiting_on_customer" रिकॉर्ड करें, और टाइमर रोक दें। जब ग्राहक जवाब दे, तब रेज़्यूम करें — नया started_at सेट करें (या अनपॉज़ कर के due_at पुनर्गणना करें)। फिर बहुत खोजने की ज़रूरत नहीं पड़ेगी।
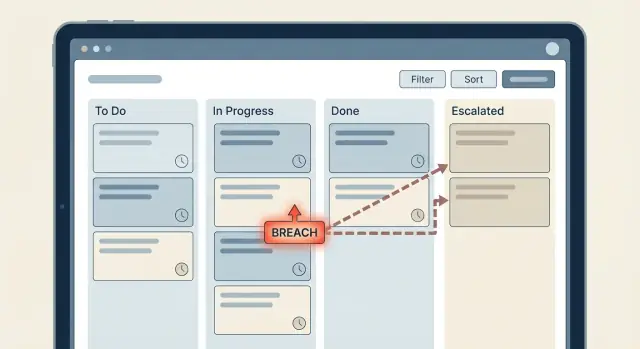
एस्केलेशन लैडर यह स्पष्ट योजना है कि SLA टाइमर के करीब पहुँचना या ब्रीच होने पर क्या होगा। गलती यह है कि ऑर्ग चार्ट को सीधे वर्कफ़्लो में कॉपी कर देना। आप उस सबसे छोटे सेट स्टेप्स को चाहते हैं जो एक अटके हुए आइटम को फिर से चालू कर सके।
एक साधारण लैडर जो कई टीमें उपयोग करती हैं: असाइन किए गए एजेंट (Level 0) को पहली नज़्दिकता, फिर टीम लीड (Level 1), और उसके बाद मैनेजर (Level 2)। यह काम इसलिए करता है क्योंकि यह वहाँ से शुरू होता है जहाँ काम वास्तव में हो सकता है, और जरूरत पड़ने पर ही अधिकार बढ़ता है।
वर्कफ़्लो एस्केलेशन नियम बनाए रखने के लिए, एस्केलेशन थ्रेशोल्ड को डेटा के रूप में स्टोर करें, न कि हार्डकोडेड कंडीशंस में। उन्हें एक टेबल या सेटिंग्स ऑब्जेक्ट में रखें: “पहली रिमाइंडर 30 मिनट के बाद” या “2 घंटे के बाद लीड को एस्केलेट करें।” जब नीतियाँ बदलें, आप एक ही जगह अपडेट करेंगे बजाय कई वर्कफ़्लो एडिट करने के।
एस्केलेशन तब स्पैम बन जाते हैं जब वे बहुत बार फ़ायर हों। प्रत्येक स्टेप के लिए गार्डरैल्स जोड़ें ताकि हर बार का उद्देश्य स्पष्ट रहे:
केवल नोटिफ़िकेशन से अटके हुए काम ठीक नहीं होते अगर जिम्मेदारी अस्पष्ट रहती है। पहले से मालिकाने के नियम परिभाषित करें: क्या टिकट एजेंट के पास ही रहेगा, लीड को रिसाइन होगा, या एक साझा क्यू में जाएगा?
उदाहरण: Level 1 एस्केलेशन के बाद टिकट टीम लीड को असाइन करें और मूल एजेंट को watcher बनाएं। इससे स्पष्ट होता है कि अगले कदम के लिए कौन जिम्मेदार है और लैडर एक ही आइटम को लोगों के बीच उछालता नहीं रहेगा।
SLA टाइमर और एस्केलेशन को मेंटेन करने योग्य रखने का सबसे आसान तरीका इसे तीन हिस्सों की एक छोटी प्रणाली की तरह मानना है: events, evaluator, और actions. इससे समय-लॉजिक दर्जनों "if time > X" चेक में फैलती नहीं है।
इवेंट्स सरल तथ्य होते हैं और इनमें टाइमर मैथ नहीं होनी चाहिए। वे यह जवाब देते हैं कि “क्या बदला?” न कि “हमें इसके बारे में क्या करना चाहिए?” सामान्य इवेंट्स में ticket created, agent replied, customer replied, status changed, या एक मैन्युअल pause/resume शामिल हैं।
इन्हें टाइमस्टैम्प और स्टेटस फ़ील्ड के रूप में स्टोर करें (उदा.: created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
एक एकल “SLA evaluator” स्टेप बनाएं जो किसी भी इवेंट के बाद और निश्चित शेड्यूल पर चले। यही evaluator due_at और शेष समय की गणना करने की एकमात्र जगह हो। यह वर्तमान तथ्यों को पढ़ता है, डेडलाइन फिर से गणना करता है, और स्पष्ट SLA स्टेट फ़ील्ड लिखता है जैसे sla_response_state और sla_resolution_state।
यहीं ब्रीच स्टेट मॉडलिंग साफ़ रहती है: evaluator OK, AtRisk, Breached जैसे स्टेट सेट करता है, बजाय इसके कि लॉजिक नोटिफ़िकेशंस के अंदर छिपा रहे।
नोटिफ़िकेशंस, असाइनमेंट, और एस्केलेशंस केवल तब ट्रिगर होने चाहिए जब स्टेट बदले (उदा.: OK -> AtRisk). संदेश भेजना SLA स्टेट अपडेट से अलग रखें। तब आप नॉटिफ़ाई करने वाले व्यक्ति को बदले बिना गणनाओं को बदले बिना परिवर्तन कर सकते हैं।
एक मेंटेन करने योग्य सेटअप आमतौर पर इस तरह दिखता है: रिकॉर्ड पर कुछ फ़ील्ड, एक छोटा नीति तालिका, और एक evaluator जो निर्णय लेता है कि आगे क्या होगा।
उस इकाई से शुरू करें जो SLA की मालिक है (ticket, order, request)। स्पष्ट टाइमस्टैम्प और एक "current SLA state" फ़ील्ड जोड़ें। इसे साधारण और अनुमान्य रखें।
फिर एक छोटी नीति तालिका जोड़ें जो नियमों का वर्णन करे बजाय उन्हें कई फ़्लोज़ में हार्डकोड करने के। सरल संस्करण में प्रति प्राथमिकता (P1, P2, P3) एक रो हो सकती है जिसमें लक्ष्य मिनट और एस्केलेशन थ्रेशोल्ड हों (उदा.: 80% पर चेतावनी, 100% पर ब्रीच)। यह एक रिकॉर्ड बदलने और पाँच वर्कफ़्लो एडिट करने के बीच अंतर है।
हर जगह अलग-अलग टाइमर बनाने के बजाय, एक शेड्यूल्ड प्रोसेस का उपयोग करें जो नियमित अंतराल पर आइटम चेक करे (सख्त SLAs के लिए हर मिनट, कई टीमों के लिए हर 5 मिनट)। शेड्यूल एक evaluator को कॉल करता है जो:
sla_state और next_check_at लिखता हैइससे SLA टाइमर और एस्केलेशन समझना आसान होता है क्योंकि आप कई टाइमरों की बजाय एक evaluator डिबग करते हैं।
evaluator को नए स्टेट के साथ-साथ यह पता चलना चाहिए कि स्टेट बदला भी है या नहीं। केवल तब संदेश या टास्क फायर करें जब स्टेट मूव करे (उदा. ok -> warning, warning -> breached)। अगर रिकॉर्ड एक घंटे तक breached रहा, तो आप 12 बार रिपीट नॉटिफ़िकेशन नहीं भेजना चाहेंगे।
एक व्यावहारिक पैटर्न यह है: sla_state और last_escalation_level स्टोर करें, उन्हें नए गणना किए गए मानों से तुलना करें, और तभी मैसेजिंग (email/SMS/Telegram) या आंतरिक टास्क कॉल करें।
पॉज़ वही जगह है जहाँ समय नियम आमतौर पर गड़बड़ हो जाते हैं। यदि आप इन्हें स्पष्ट रूप से मॉडल नहीं करते, तो आपका SLA या तो चलती रहे जब उसे नहीं चलना चाहिए, या कोई किसी गलत स्टेटस क्लिक से रीसेट कर दे।
एक सरल नियम: केवल एक स्टेट (या कुछ सीमित स्टेट) घड़ी को पॉज़ करे। सामान्य विकल्प है Waiting for customer। जब टिकट उस स्टेट में जाता है, तो pause_started_at टाइमस्टैम्प स्टोर करें। जब ग्राहक जवाब दे कर टिकट उस स्टेट से निकलता है, तो pause_ended_at लिखें और अवधि को paused_total_seconds में जोड़ दें।
सिर्फ़ एक काउंटर न रखें। हर पॉज़ विंडो (start, end, किसने/क्या ट्रिगर किया) कैप्चर करें ताकि आपके पास ऑडिट ट्रेल रहे। बाद में, जब कोई पूछे कि केस क्यों ब्रीच हुआ, आप दिखा सकें कि उसने 19 घंटे ग्राहक का इंतज़ार किया।
रीअसाइनमेंट और सामान्य स्टेटस बदलाव घड़ी को रीस्टार्ट नहीं करना चाहिए। SLA टाइमस्टैम्प ownership फ़ील्ड से अलग रखें। उदाहरण के लिए, sla_started_at और sla_due_at एक बार (क्रिएशन पर, या SLA पॉलिसी बदलने पर) सेट किए जाएँ, जबकि reassignment सिर्फ assignee_id अपडेट करे। फिर आपका evaluator शेष समय इस तरह गणना कर सकता है: now - sla_started_at - paused_total_seconds.
ऐसे नियम जो SLA टाइमर और एस्केलेशन को भविष्यवाणी योग्य बनाते हैं:
डिज़ाइन की जांच करने का एक सरल तरीका है कि एक सपोर्ट टिकट लें जिसमें दो SLAs हों: पहला जवाब 30 मिनट में, और पूरा रिज़ॉल्यूशन 8 घंटे में। यदि लॉजिक स्क्रीन और बटन में बिखरा हुआ है तो यहीं अक्सर टूटता है।
मान लीजिए हर टिकट में स्टोर है: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met), और टाइमस्टैम्प्स जैसे created_at, first_agent_reply_at, और resolved_at।
एक वास्तविक Timeline:
एस्केलेशंस के लिए, एक स्पष्ट चेन रखें जो स्टेट ट्रांज़िशन पर ट्रिगर हो। उदाहरण के लिए, जब response Warning बने तो असाइन किए गए एजेंट को नोटिफ़ाई करें। जब यह Breached बने तो टीम लीड को नोटिफ़ाई करें और प्राथमिकता अपडेट करें।
हर स्टेप पर वही छोटा सेट फ़ील्ड अपडेट करें ताकि उसे समझना आसान रहे:
response_status या resolution_status को Pending, Warning, Breached, या Met सेट करें।*_warning_at और *_breach_at टाइमस्टैम्प्स एक बार लिखें, फिर कभी ओवरराइट न करें।escalation_level (0, 1, 2) इन्क्रीमेंट करें और escalated_to सेट करें (Agent, Lead, Manager)।sla_events लॉग में इवेंट प्रकार और किसे नोटिफ़ाई किया गया उसका रिकॉर्ड जोड़ें।priority और due_at सेट करें ताकि UI और रिपोर्ट एस्केलेशन दिखाएँ।कुंजी यह है कि Warning और Breached स्पष्ट स्टेट हों। आप उन्हें डेटा में देख सकते हैं, ऑडिट कर सकते हैं, और बाद में लैडर बदल सकते हैं बिना छिपे हुए टाइमर चेक ढूँढे।
SLA लॉजिक तब गंदा होता है जब यह फैल जाता है। एक बटन पर एक त्वरित टाइम चेक, वहाँ एक कंडीशनल अलर्ट, और जल्द ही कोई भी समझ नहीं पाता कि टिकट क्यों एस्केलेट हुआ। SLA टाइमर और एस्केलेशन को एक छोटा, केंद्रीय लॉजिक रखें जिस पर हर स्क्रीन और एक्शन निर्भर करे।
एक आम जाल है कई स्थानों पर समय चेक एम्बेड करना (UI स्क्रीन, API हैंडलर, मैन्युअल क्रियाएँ)। सुधार यह है कि SLA स्टेट एक evaluator में गणना करें और रिकॉर्ड पर परिणाम स्टोर करें। स्क्रीनें स्टेट पढ़ें, उसे न बनाएं।
एक और जाल है कि टाइमर अलग-अलग क्लॉक्स उपयोग करते हैं। अगर ब्राउज़र “minutes since created” गणना करता है पर बैकएंड सर्वर समय उपयोग करता है, तो आपको स्लीप, टाइमज़ोन, और डे़लाइट सेविंग्ज़ के आसपास एज केस दिखेंगे। किसी भी ऐसी चीज़ के लिए जो एस्केलेशन ट्रिगर करती है, सर्वर समय पसंद करें।
नोटिफ़िकेशंस भी जल्दी शोर कर सकती हैं। अगर आप “हर मिनट चेक करें और ओवरड्यू होने पर भेजें” करते हैं, तो लोग हर मिनट स्पैम महसूस करेंगे। संदेशों को ट्रांज़िशन से जोड़ें: “warning sent,” “escalated,” “breached.” तब आप प्रति स्टेप एक बार भेजते हैं और क्या हुआ इसका ऑडिट रख सकते हैं।
बिज़नेस आवर्स लॉजिक भी अनजाने जटिलता का स्रोत है। अगर हर नियम में उसकी अपनी “यदि वीकेंड तो…” शाखा है, तो अपडेट्स मुश्किल हो जाते हैं। बिज़नेस-आवर्स मैथ को एक फ़ंक्शन (या एक शेयर किए गए ब्लॉक) में रखें जो “अब तक कितने SLA मिनट खर्च हुए” लौटाए, और उसे पुन: उपयोग करें।
अंततः, ब्रीच को फिर से गणना करने पर भरोसा न करें — जिस क्षण ब्रीच हुआ उसे स्टोर करें:
breached_at सेव करें, और उसे कभी ओवरराइट न करें।escalation_level और last_escalated_at सेव करें ताकि एक्शन आयडेम्पोटेन्ट रहें।notified_warning_at जैसे फ़ील्ड सेव करें ताकि बार-बार अलर्ट न जाएं।उदाहरण: एक टिकट “Response SLA breached” पर 10:07 को पहुंचता है। अगर आप केवल पुनर्गणना करते हैं, तो एक बाद का स्टेटस चेंज या पॉज़/रेज़्यूम बग से ब्रीच का समय 10:42 दिख सकता है। breached_at = 10:07 के साथ रिपोर्टिंग और पोस्टमॉर्टेम स्थिर रहते हैं।
टाइमर और अलर्ट जोड़ने से पहले, एक पास करें ताकि नियम एक महीने बाद भी पठनीय रहें।
एक व्यावहारिक परीक्षण: एक ऐसा टिकट लें जो ब्रीच के करीब है और उसकी टाइमलाइन को रिप्ले करें। अगर आप बिना पूरे वर्कफ़्लो को पढ़े यह नहीं बता सकते कि प्रत्येक स्टेट परिवर्तन पर क्या होगा, तो आपका मॉडल बहुत बिखरा हुआ है।
सबसे छोटा उपयोगी स्लाइस पहले बनाएं। एक SLA चुनें (उदा., first response) और एक एस्केलेशन लेवल (उदा., टीम लीड को सूचित करें)। एक सप्ताह के वास्तविक उपयोग से आप कागज़ पर परफेक्ट डिज़ाइन से ज़्यादा सीखेंगे।
थ्रेशोल्ड और रिसिपियंट्स को डेटा रखें, न कि लॉजिक में। मिनट और घंटे, बिज़नेस-आवर्स नियम, किसे नोटिफ़ाई करना है, और कौन सी क्यू केस की मालिक है ये टेबल या कन्फिग रिकॉर्ड में रखें। तब वर्कफ़्लो स्थिर रहेगा जबकि बिज़नेस केवल नंबर और राउटिंग बदल सकेगा।
एक साधारण डैशबोर्ड व्यू जल्दी बनाना प्लान करें। आपको बड़ी एनालिटिक्स प्रणाली की ज़रूरत नहीं — बस एक साझा तस्वीर कि अभी क्या हो रहा है: on track, warning, breached, escalated।
यदि आप इसे किसी नो‑कोड वर्कफ़्लो ऐप में बना रहे हैं, तो ऐसा प्लेटफ़ॉर्म चुनना मददगार है जो डेटा मॉडलिंग, विज़ुअल बिज़नेस प्रोसेसेस, और शेड्यूल्ड evaluators एक ही जगह करने दे। उदाहरण के लिए, AppMaster (appmaster.io) डेटाबेस मॉडलिंग, विज़ुअल बिज़नेस प्रोसेस और प्रोडक्शन-रेडी ऐप्स जनरेट करने का समर्थन करता है, जो "events, evaluator, actions" पैटर्न के साथ अच्छा मेल खाता है।
सुरक्षित रूप से परिष्कृत करने के लिए इस क्रम में परिवर्तन करें:
जब आप तैयार हों, पहले एक छोटा वर्शन बनाएं, फिर वास्तविक फ़ीडबैक और वास्तविक टिकट्स के साथ उसे बढ़ाएँ।
Start with a clear definition of the promise you’re measuring, like first response or resolution, and write down the exact start, stop, and pause rules. Then centralize the time math in one evaluator that sets explicit SLA states instead of sprinkling “if now > X” checks across many workflows.
A timer is the clock you start or schedule after an event, such as a ticket moving to a new status. An escalation is the action you take when a threshold is reached, like notifying a lead or changing priority. A breach is the stored fact that the SLA was missed, which you can report on later.
First response measures time until the first meaningful human reply, while resolution measures time until the issue is truly closed. They behave differently around pauses and reopenings, so modeling them separately keeps your rules simpler and your reporting accurate.
Use calendar time by default because it’s simpler and easier to debug. Only add working-time rules if you truly need them, since business hours introduce extra complexity like holidays, time zones, and partial-day calculations.
Model pauses as explicit states tied to specific statuses, like Waiting on Customer, and store when the pause started and ended. When you resume, either continue with remaining time or recalculate due time in one place, but don’t let random status toggles reset the clock.
A single flag hides important context, like which SLA breached, whether it’s paused, and whether you already escalated. Explicit states like On track, Warning, Breached, Paused, and Completed make the system predictable and easier to audit and change.
Store timestamps that explain the state, such as started_at, due_at, breached_at, and pause fields like paused_at and paused_reason. Also store escalation tracking like last_escalation_level so you don’t notify the same level twice.
Create a small ladder that starts with the person who can act, then escalates to a lead, then a manager only if needed. Keep thresholds and recipients as data (like a policy table) so changing escalation timing doesn’t require editing multiple workflows.
Tie notifications to state transitions like OK -> Warning or Warning -> Breached, not to “still overdue” checks. Add simple guardrails like cooldown windows and stop conditions so you send one message per step instead of repeating alerts every scheduled run.
Use a pattern of events, a single evaluator, and actions: events record facts, the evaluator computes deadlines and sets SLA state, and actions react only to state changes. In AppMaster, you can model the data, build the evaluator as a visual business process, and trigger notifications or assignments from the state updates while keeping time math centralized.



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


