उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
CRUD-भारित बैकएंड्स के लिए न्यूनतम ऑब्ज़रवेबिलिटी: स्ट्रक्चर्ड लॉग्स, आवश्यक मेट्रिक्स, और व्यावहारिक अलर्ट ताकि धीमी क्वेरीज, त्रुटियाँ, और आउटेज जल्दी पकड़े जा सकें।
CRUD-भारी बिज़नेस ऐप्स अक्सर उबाऊ और महंगी तरह से बिगड़ते हैं। एक लिस्ट पेज हर हफ्ते धीमा हो जाता है, सेव बटन कभी-कभी टाइमआउट देता है, और सपोर्ट “रैंडम 500s” रिपोर्ट करता है जिन्हें आप दोहराकर नहीं बना पाते। डेवलपमेंट में कुछ भी टूटा हुआ नहीं दिखता, लेकिन प्रोडक्शन भरोसेमंद नहीं लगता।
असल लागत सिर्फ घटना नहीं होती। सबसे बड़ी हानि अनुमान लगाने में लगने वाला समय है। स्पष्ट संकेतों के बिना टीमें “शायद डेटाबेस है,” “शायद नेटवर्क है,” और “शायद वही एक एंडपॉइंट” के बीच उछलती रहती हैं, जबकि यूजर इंतज़ार करते हैं और भरोसा घटता है।
ऑब्ज़रवेबिलिटी उन अटकलों को जवाब में बदल देती है। सीधे शब्दों में: आप देख सकते हैं कि क्या हुआ और क्यों हुआ। आप तीन प्रकार के सिग्नल से वहां पहुंचते हैं:
CRUD ऐप्स और API सर्विसेज़ के लिए यह फ़ैंसी डैशबोर्ड्स का मामला नहीं है, बल्कि तेज़ डायग्नोसिस का है। जब “Create invoice” कॉल धीमा हो, तो आपको मिनटों में बताना चाहिए कि देरी डेटाबेस क्वेरी, डाउनस्ट्रीम API, या एक ओवरलोडेड वर्कर की वजह से है—घंटों नहीं।
एक न्यूनतम सेटअप उन सवालों से शुरू होता है जिनका आपको खराब दिन पर जवाब चाहिए:
यदि आप जेनरेटेड स्टैक से बैकएंड बनाते हैं (उदाहरण के लिए, AppMaster से Go सर्विसेज़ जेनरेट हों), वही नियम लागू होता है: छोटे से शुरू करें, सिग्नल्स को सुसंगत रखें, और केवल उसी समय नए मेट्रिक्स या अलर्ट जोड़ें जब कोई वास्तविक घटना यह साबित करे कि इससे समय बचता।
एक न्यूनतम ऑब्ज़रवेबिलिटी सेटअप के तीन स्तंभ हैं: logs, metrics, और alerts। traces उपयोगी हैं, पर अधिकांश CRUD-भारी बिज़नेस ऐप्स के लिए वे बोनस हैं।
लक्ष्य सरल है। आपको पता होना चाहिए (1) कब यूज़र्स फेल कर रहे हैं, (2) क्यों वे फेल कर रहे हैं, और (3) सिस्टम के किस हिस्से में यह हो रहा है। अगर आप इन सवालों का तुरंत जवाब नहीं दे पा रहे, तो आप समय बर्बाद करेंगे और बदलावों पर बहस करेंगे।
सबसे छोटा संकेत सेट जो आम तौर पर काम दे देता है ऐसा दिखता है:
request_id, user, endpoint, और error से सर्च कर सकें।यह भी मददगार है कि आप लक्षण (symptoms) और कारण (causes) अलग रखें। लक्षण वह है जो यूज़र्स महसूस करते हैं: 500s, timeouts, slow pages। कारण वह है जो इसे बनाता है: lock contention, saturated connection pool, या किसी नए फ़िल्टर की वजह से धीमी क्वेरी। लक्षण पर अलर्ट करें और तहकीकात के लिए कारण-सिग्नल्स का प्रयोग करें।
एक व्यावहारिक नियम: महत्वपूर्ण सिग्नल देखने के लिए एक ही जगह चुनें। लॉग टूल, मेट्रिक्स टूल, और अलग alert इनबॉक्स के बीच कॉन्टेक्स्ट स्विचिंग आपको उस समय स्लो कर देता है जब सबसे ज़रूरी है।
जब कुछ टूटता है, तो उत्तर तक पहुंचने का तेज़ रास्ता आमतौर पर होता है: “इस यूज़र ने ठीक कौन सी रिक्वेस्ट मारी थी?” इसलिए एक स्थिर correlation ID अधिकांश अन्य लॉग सुधारों से ज्यादा महत्वपूर्ण है।
एक फील्ड नाम चुनें (आम तौर पर request_id) और उसे अनिवार्य समझें। इसे एज़ पर (API gateway या पहले हैंडलर) जनरेट करें, आंतरिक कॉल्स में पास करें, और हर लॉग लाइन में शामिल करें। बैकग्राउंड जॉब्स के लिए, हर जॉब रन पर नया request_id बनाएं और जब जॉब किसी API कॉल से ट्रिगर हुआ हो तो parent_request_id रखें।
लॉग JSON में करें, फ्री टेक्स्ट में नहीं। इससे लॉग सर्चेबल और कंसिस्टेंट रहते हैं जब आप थके हुए, तनाव में, और स्किम कर रहे हों।
CRUD-भारी API सर्विसेज़ के लिए कुछ फ़ील्ड ही पर्याप्त हैं:
timestamp, level, service, envrequest_id, route, method, statusduration_ms, db_query_counttenant_id या account_id (सुरक्षित पहचानकर्ता, व्यक्तिगत डेटा नहीं)लॉग्स आपको यह बताने में मदद करनी चाहिए कि “कौन सा ग्राहक और कौन सा स्क्रीन,” बिना डेटा लीक में बदलने के। नाम, ईमेल, फोन, पते, टोकन, या पूरे रिक्वेस्ट बॉडी को डिफ़ॉल्ट रूप से लॉग करने से बचें। अगर गहरा विवरण चाहिए, तो सिर्फ़ मांग पर और redaction के साथ लॉग करें।
CRUD सिस्टम्स में दो फ़ील्ड जल्दी लाभ देती हैं: duration_ms और db_query_count। ये धीमे हैंडलर्स और आकस्मिक N+1 पैटर्नों को ट्रेसिंग जोड़ने से पहले पकड़ लेते हैं।
लॉग लेवल्स को परिभाषित करें ताकि हर कोई उन्हें एक ही तरह से उपयोग करे:
info: अपेक्षित इवेंट्स (request completed, job started)warn: असामान्य पर रिकवर होने योग्य (slow request, retry succeeded)error: फेल हुई रिक्वेस्ट या जॉब (exception, timeout, bad dependency)यदि आप AppMaster जैसे प्लेटफ़ॉर्म से बैकएंड बनाते हैं, तो जेनरेटेड सेवाओं में वही फ़ील्ड नाम रखें ताकि हर जगह “search by request_id” काम करे।
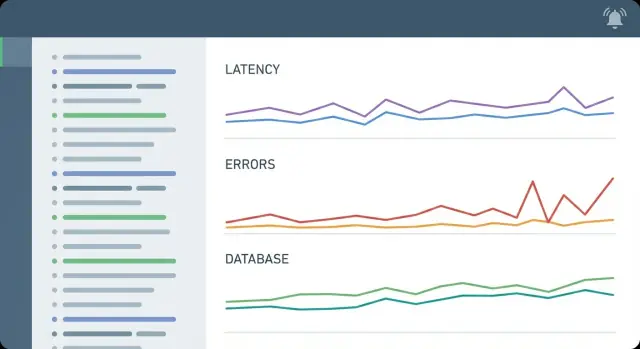
CRUD-भारी ऐप्स में अधिकांश घटनाओं की एक परिचित आकृति होती है: एक या दो एंडपॉइंट धीमे हो जाते हैं, डेटाबेस दबाव में आ जाता है, और यूज़र्स स्पिनर या टाइमआउट देखते हैं। आपके मेट्रिक्स को उस कहानी मिनटों में स्पष्ट कर देनी चाहिए।
एक न्यूनतम सेट आम तौर पर पाँच क्षेत्रों को कवर करता है:
दो बातें मेट्रिक्स को बहुत अधिक actionable बनाती हैं।
पहला, इंटरैक्टिव API रिक्वेस्ट्स और बैकग्राउंड वर्क अलग रखें। एक धीमा ईमेल सें더 या webhook retry लूप CPU, DB कनेक्शन्स, या आउटगोइंग नेटवर्क को भूखा कर सकता है और API को “रैंडमली स्लो” दिखा सकता है। अपनी कतारें, retries, और जॉब duration को उनके अपने टाइम सीरीज़ में ट्रैक करें, भले वे उसी बैकेंड में चलें।
दूसरा, हमेशा वर्ज़न/build मेटाडेटा को डैशबोर्ड और अलर्ट्स से जोड़ें। जब आप कोई नया जेनरेटेड बैकएंड डिप्लॉय करते हैं (उदाहरण के लिए AppMaster से कोड जेनरेशन के बाद), तो आप जल्दी से यह जवाब दे सकें: क्या error rate या p95 latency इसी रिलीज़ के बाद बढ़ा?
एक सरल नियम: अगर कोई मेट्रिक आपको अगले कदम नहीं बता सकता (roll back, scale, fix a query, या जॉब रोकें), तो वह आपके न्यूनतम सेट में नहीं होना चाहिए।
CRUD-भारी ऐप्स में डेटाबेस अक्सर वह जगह होता है जहाँ “धीमा लगना” वास्तविक उपयोगकर्ता दर्द बन जाता है। एक न्यूनतम सेटअप यह स्पष्ट कर दे कि बॉटलनेक PostgreSQL में है, और किस तरह की DB समस्या है।
आपको दर्जनों डैशबोर्ड्स की ज़रूरत नहीं है। उन सिग्नल्स से शुरू करें जो अधिकांश घटनाओं की व्याख्या करते हैं:
API लेयर में एक query timing histogram जोड़ें और उसे endpoint या use case के साथ टैग करें (उदाहरण: GET /customers, “search orders”, “update ticket status”)। यह दिखाता है कि कोई एंडपॉइंट इसलिए धीमा है क्योंकि वह कई छोटी क्वेरीज़ रन करता है या एक बड़ी क्वेरी।
CRUD स्क्रीन अक्सर N+1 क्वेरीज ट्रिगर करती हैं: एक लिस्ट क्वेरी, फिर हर रो के लिए एक क्वेरी संबंधित डेटा पाने के लिए। उन एंडपॉइंट्स की निगरानी करें जहाँ रिक्वेस्ट काउंट फ्लैट रहता है पर DB query count प्रति रिक्वेस्ट बढ़ता है। अगर आप मॉडल और बिज़नेस लॉजिक से बैकएंड जेनरेट करते हैं, तो यही वह जगह है जहाँ आप fetch पैटर्न को ट्यून करते हैं।
अगर आपके पास कैश पहले से है, तो hit rate ट्रैक करें। बेहतर चार्ट पाने के लिए कैश न जोड़ें।
Schema changes और migrations को एक रिस्क विंडो समझें। जब वे शुरू और खत्म हों, तो रिकॉर्ड करें और उस विंडो के दौरान locks, query time, और connection errors में spikes देखें।
अलर्ट्स को एक वास्तविक यूज़र समस्या की ओर इशारा करना चाहिए, न कि एक व्यस्त चार्ट। CRUD-भारी ऐप्स के लिए, यूज़र जो महसूस करते हैं—errors और slowness—उन्हें पहले देखें।
अगर आप शुरुआत में सिर्फ़ तीन अलर्ट जोड़ते हैं, तो वे बनाएं:
उसके बाद, कुछ “संभावित कारण” वाले अलर्ट जोड़ें। CRUD बैकएंड अक्सर पूर्वानुमेय रूप से फेल होते हैं: डेटाबेस कनेक्शन्स खत्म हो जाना, बैकग्राउंड कतार का बढ़ना, या एक अकेला एंडपॉइंट टाइमआउट करना जो पूरे API को धीमा कर देता है।
“p95 > 200ms” जैसे हार्डकोडेड नंबर अक्सर सभी वातावरणों में काम नहीं करते। एक सामान्य हफ़्ते को नापें, फिर अलर्ट को सामान्य के ठीक ऊपर से मार्जिन के साथ सेट करें। उदाहरण के लिए, अगर p95 आमतौर पर बिज़नेस घंटों में 350-450ms है, तो 700ms पर 10 मिनट के लिए अलर्ट करें। अगर 5xx सामान्यतः 0.1-0.3% है, तो 2% पर 5 मिनट के लिए पेज करें।
थ्रेशोल्ड्स को स्थिर रखें। हर दिन उन्हें ट्यून न करें। किसी घटना के बाद ही उन्हें ट्यून करें, जब आप बदलावों को वास्तविक परिणामों से जोड़ सकें।
दो गंभीरता स्तर इस्तेमाल करें ताकि लोग सिग्नल पर भरोसा करें:
डिप्लॉय विंडोज और प्लान्ड मेंटेनेंस के दौरान अलर्ट साइलेंस करें।
अलर्ट्स को actionable बनाएं। “पहले क्या जांचें” शामिल करें (top endpoint, DB connections, हालिया deploy) और “क्या बदला” (नई रिलीज़, schema update)। यदि आप AppMaster में बनाते हैं, तो नोट करें कि सबसे हाल ही में कौन सा बैकएंड या मॉड्यूल regenerate और deploy हुआ—क्योंकि यह अक्सर सबसे तेज़ सुराग होता है।
जब आप यह तय कर लेते हैं कि “काफी अच्छा” क्या मायने रखता है, तो एक न्यूनतम सेटअप आसान हो जाता है। SLOs इस काम के लिए हैं: स्पष्ट लक्ष्य जो अस्पष्ट मॉनिटरिंग को विशिष्ट अलर्ट में बदल देते हैं।
SLIs से शुरू करें जो यूज़र्स के अनुभव से जुड़ी हों: availability (क्या यूज़र्स रिक्वेस्ट पूरा कर पाते हैं), latency (एक्शन कितनी तेज़ी से खत्म होते हैं), और error rate (कितनी बार रिक्वेस्ट फेल होती है)।
SLOs endpoint समूहों के हिसाब से सेट करें, रूट-वार नहीं। CRUD-भारी ऐप्स के लिए ग्रुपिंग पढ़ने योग्य रखती है: reads (GET/list/search), writes (create/update/delete), और auth (login/token refresh)। इससे सैकड़ों छोटे SLOs से बचाव होगा जो कोई भी मेंटेन नहीं करता।
आदर्श SLOs जो सामान्य अपेक्षाओं से मेल खाते हैं:
Error budgets वह “अनुमत बुरा समय” है जो SLO के भीतर है। 99.9% मासिक availability SLO का अर्थ है कि आप महीने में लगभग 43 मिनट डाउनटाइम बर्दाश्त कर सकते हैं। अगर आप यह बजट जल्दी खर्च कर लेते हैं, तो स्थिरता लौटने तक जोखिम भरे बदलाव रोक दें।
SLOs का इस्तेमाल यह तय करने में करें कि क्या किसी चीज़ के लिए अलर्ट चाहिए या सिर्फ़ डैशबोर्ड रुझान। जब आप error budget तेजी से जला रहे हों (यूज़र्स सक्रिय रूप से फेल हो रहे हों) तब अलर्ट करें, न कि जब कोई मेट्रिक कल से थोड़ा खराब दिखे।
यदि आप तेज़ी से बैकएंड बनाते हैं (उदाहरण के लिए AppMaster से Go सर्विस जेनरेट करते हुए), SLOs implementation में बदलाव के बावजूद यूज़र इम्पैक्ट पर ध्यान बनाए रखती हैं।
सबसे पहले उस सिस्टम के हिस्से से शुरू करें जिसे यूज़र्स सबसे ज़्यादा छूते हैं। उन API कॉल्स और जॉब्स को चुनें जो धीमे या टूटे होने पर पूरा ऐप डाउन जैसा अनुभव दे देते हैं।
अपने शीर्ष endpoints और बैकग्राउंड वर्क लिखें। CRUD बिज़नेस ऐप के लिए आम तौर पर यह login, list/search, create/update, और एक export/import जॉब होता है। अगर आपने बैकएंड AppMaster से बनाया है, तो अपनी generated endpoints और किसी भी Business Process flows को शामिल करें जो शेड्यूल पर या webhooks पर चलते हों।
request_id, user_id (यदि उपलब्ध), endpoint, status_code, latency_ms, db_time_ms, और ज्ञात त्रुटियों के लिए एक छोटा error_code।अलर्ट्स को कम और लक्षित रखें। आप ऐसे अलर्ट चाहते हैं जो यूज़र इम्पैक्ट की ओर इशारा करें, न कि “कुछ बदल गया”।
एक मजबूत शुरुआती सेट में शामिल हैं: API p95 latency बहुत ज़्यादा, सतत 5xx rate, 4xx में अचानक spike (अक्सर auth या validation बदलाव), बैकग्राउंड जॉब failures, DB slow queries, DB connections सीमा के पास, और कम डिस्क स्पेस (अगर self-hosted)।
फिर हर अलर्ट के लिए एक छोटा runbook लिखें। एक पेज काफी है: पहले क्या जांचें (डैशबोर्ड पैनल्स और प्रमुख लॉग फ़ील्ड्स), संभावित कारण (DB locks, missing index, downstream outage), और पहला सुरक्षित कदम (अटके वर्कर को restart करें, परिवर्तन rollback करें, भारी जॉब को pause करें)।
न्यूनतम ऑब्ज़रवेबिलिटी सेटअप को बेकार बनाने का सबसे तेज़ तरीका मॉनिटरिंग को एक चेकबॉक्स समझना है। CRUD-भारी ऐप्स आम तौर पर कुछ पूर्वानुमेय तरीकों से फेल होते हैं (धीमे DB कॉल, timeouts, खराब रिलीज़), इसलिए आपके सिग्नल्स को उन पर केंद्रित रखें।
सबसे सामान्य विफलता alert fatigue है: बहुत ज्यादा अलर्ट, बहुत कम कार्रवाई। अगर आप हर स्पाइक पर पेज करते हैं, लोग अलर्ट्स पर भरोसा नहीं करेंगे। एक अच्छा नियम सरल है: एक अलर्ट को संभावित फिक्स की ओर इशारा करना चाहिए, सिर्फ़ “कुछ बदल गया” नहीं।
एक और क्लासिक गलती correlation IDs का अभाव है। अगर आप एक एरर लॉग, एक धीमी रिक्वेस्ट, और एक DB क्वेरी को एक ही रिक्वेस्ट से जोड़ नहीं पा रहे, तो आप घंटों खो देंगे। सुनिश्चित करें कि हर रिक्वेस्ट को request_id मिलता है (और उसे लॉग्स, ट्रेसेस अगर हैं, और ज़रूरी होने पर रिस्पॉन्स में शामिल करें)।
शोर वाले सिस्टम आम तौर पर इन समस्याओं को साझा करते हैं:
CRUD ऐप्स विशेष रूप से “औसत फ़ंस” के प्रति संवेदनशील हैं। एक ही धीमी क्वेरी 5% रिक्वेस्ट्स को दर्दनाक बना सकती है जबकि औसत ठीक दिखता है। Tail latency और error rate एक स्पष्ट तस्वीर देते हैं।
डिप्लॉय मार्कर्स जोड़ें। चाहे आप CI से शिप करें या AppMaster जैसी सर्विस से कोड regenerate करें, version और deployment time को एक इवेंट और आपके लॉग्स में रिकॉर्ड करें।
आपका सेटअप तब काम कर रहा है जब आप कुछ सवालों का तेज़ जवाब दे सकें, बिना 20 मिनट डैशबोर्ड खोदे। अगर आप तेज़ी से “हाँ/नहीं” तक नहीं पहुँचते, तो आप किसी मुख्य सिग्नल से चूक रहे हैं या आपके व्यू बहुत बिखरे हुए हैं।
आपको इनमें से अधिकांश एक मिनट से कम में कर पाए जाने चाहिए:
लॉग्स को एक साथ सुरक्षित और उपयोगी रखें। उन्हें किसी असफल रिक्वेस्ट का अनुसरण करने के लिए पर्याप्त संदर्भ चाहिए, पर व्यक्तिगत डेटा लीक नहीं होना चाहिए।
एक हालिया फेल्योर चुनें और उसके लॉग खोलें। पुष्टि करें कि आपके पास request_id, endpoint, status code, duration, और एक स्पष्ट error message है। साथ ही यह भी पुष्टि करें कि आप rå tokens, passwords, पूरे payment विवरण, या व्यक्तिगत फ़ील्ड्स लॉग नहीं कर रहे।
अगर आप CRUD-भारी बैकएंड्स AppMaster से बना रहे हैं, तो एक ही “incident view” का लक्ष्य रखें जो ये चेक जोड़ता हो: errors, p95 latency by endpoint, और DB health। यह अकेला अधिकांश वास्तविक आउटेज को कवर कर देता है।
एक internal admin पोर्टल सुबह ठीक है, फिर एक व्यस्त घंटे में noticeably धीमा हो जाता है। यूज़र्स शिकायत करते हैं कि “Orders” लिस्ट खोलना और एडिट्स सेव करना 10-20 सेकंड ले रहा है।
आप टॉप-लेवल सिग्नल्स से शुरू करते हैं। API डैशबोर्ड दिखाता है कि read endpoints का p95 latency सुबह ~300 ms से 4-6 s पर कूद गया, जबकि error rate कम ही रहा। साथ ही डेटाबेस पैनल में active connections pool limit के पास दिख रहे हैं और lock waits बढ़ रहे हैं। बैकेंड नोड्स का CPU सामान्य दिखता है, तो यह compute की समस्या जैसा नहीं दिखता।
फिर आप एक धीमी रिक्वेस्ट उठाते हैं और लॉग्स के ज़रिए उसका पालन करते हैं। GET /orders पर फ़िल्टर करें और duration के हिसाब से सॉर्ट करें। एक 6-second रिक्वेस्ट से request_id पकड़ें और उसे सेवाओं में खोजें। हैंडलर जल्दी खत्म हुआ दिखेगा, पर उसी request_id के अंदर DB क्वेरी लॉग लाइन 5.4-second की क्वेरी दिखाएगी जिसमे rows=50 और बड़ा lock_wait_ms है।
अब आप कारण confidently कह सकते हैं: slowdown डेटाबेस पाथ में है (slow query या lock contention), नेटवर्क या बैकएंड CPU नहीं। यही न्यूनतम सेटअप आपको तेज़ narrowing देता है।
सुरक्षित क्रम से सामान्य फिक्सेस:
लूप बंद करें एक लक्षित अलर्ट के साथ। तब ही पेज करें जब endpoint group का p95 latency आपकी थ्रेशोल्ड से 10 मिनट तक ऊपर रहे और DB connection usage (उदाहरण के लिए) 80% के ऊपर हो। यह संयोजन शोर से बचाता है और अगली बार इस मुद्दे को पहले पकड़ता है।
एक न्यूनतम ऑब्ज़रवेबिलिटी सेटअप पहले दिन उबाऊ लगना चाहिए। अगर आप बहुत सारे डैशबोर्ड और अलर्ट्स से शुरू करते हैं, तो आप उन्हें हमेशा ट्यून करेंगे और फिर भी असली समस्याएँ मिस कर देंगे।
हर घटना को फीडबैक मानें। फिक्स शिप होने के बाद पूछें: क्या चीज़ ने इसे जल्दी पकड़ने और निदान करने में मदद की होती? सिर्फ़ वही जोड़ें।
शुरू में स्टैंडर्डाइज़ करें, भले ही आज आपके पास सिर्फ़ एक सर्विस ही हो। लॉग्स में वही फ़ील्ड नाम और हर जगह वही मेट्रिक नाम इस्तेमाल करें ताकि नई सर्विस बिना बहस के पैटर्न से मेल खा जाए। यह डैशबोर्ड्स को भी पुन:उपयोगी बनाता है।
एक छोटा रिलीज़ अनुशासन जल्दी फायदा देता है:
अगर आप AppMaster से बैकएंड बनाते हैं, तो observability फ़ील्ड्स और प्रमुख मेट्रिक्स को जेनरेशन से पहले प्लान करना मददगार होता है, ताकि हर नई API production-ready structured logs और health signals के साथ आये। अगर आप एक जगह से उन बैकएंड्स को बनाना शुरू करना चाहते हैं तो AppMaster (appmaster.io) ऐसे प्रोडक्शन-रेडी बैकएंड, वेब, और मोबाइल ऐप जेनरेट करने के लिए डिज़ाइन है, साथ ही implementation को requirements बदलने पर भी सुसंगत रखता है।
एक बार में एक अगला सुधार चुनें, वास्तविक दर्द के आधार पर:
हर वास्तविक घटना के बाद इस चक्र को दोहराएँ। कुछ हफ्तों में आपके पास मॉनिटरिंग होगी जो आपके CRUD ऐप और API ट्रैफ़िक के अनुकूल होगी, न कि सिर्फ़ एक सामान्य टेम्पलेट।
Start with observability when production issues take longer to explain than to fix. If you’re seeing “random 500s,” slow list pages, or timeouts you can’t reproduce, a small set of consistent logs, metrics, and alerts will save hours of guessing.
Monitoring tells you that something is wrong, while observability helps you understand why it happened by using context-rich signals you can correlate. For CRUD APIs, the practical goal is quick diagnosis: which endpoint, which user/tenant, and whether the time was spent in the app or the database.
Start with structured request logs, a handful of core metrics, and a few user-impact alerts. Tracing can wait for many CRUD apps if you already log duration_ms, db_time_ms (or similar), and a stable request_id you can search everywhere.
Use a single correlation field like request_id and include it in every request log line and every background job run. Generate it at the edge, pass it through internal calls, and make sure you can search logs by that ID to reconstruct one failing or slow request quickly.
Log timestamp, level, service, env, route, method, status, duration_ms, and safe identifiers like tenant_id or account_id. Avoid logging personal data, tokens, and full request bodies by default; if you need detail, add it only for specific errors with redaction.
Track request rate, 5xx rate, latency percentiles (at least p50 and p95), and basic saturation (CPU/memory plus any worker or queue pressure you have). Add database time and connection pool usage early, because many CRUD outages are really database contention or pool exhaustion.
Because they hide the slow tail that users actually feel. Averages can look fine while p95 latency is terrible for a meaningful slice of requests, which is exactly how CRUD screens feel “randomly slow” without obvious errors.
Watch slow query rate and query time percentiles, lock waits/deadlocks, and connection usage versus pool limits. Those signals tell you whether the database is the bottleneck and whether the problem is query performance, contention, or simply running out of connections under load.
Start with alerts on user symptoms: sustained 5xx rate, sustained p95 latency, and a sudden drop in successful requests. Add cause-oriented alerts only after that (like DB connections near limit or job backlog) so the on-call signal stays trustworthy and actionable.
Attach version/build metadata to logs, dashboards, and alerts, and record deploy markers so you can see when changes shipped. With generated backends (like AppMaster-generated Go services), this is especially important because regeneration and redeploys can happen often, and you’ll want to quickly confirm whether a regression started right after a release.



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


