उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
लंबे-समय के वर्कफ़्लो गड़बड़ तरीके से फेल हो सकते हैं। स्पष्ट स्टेट पैटर्न, स्टेप-स्तरीय रिट्राई काउंटर, डेड-लेट्टर हैंडलिंग और ऑपरेटर ट्रस्ट करने योग्य डैशबोर्ड सीखें।
लंबे समय तक चलने वाले वर्कफ़्लो तेज़ अनुरोधों से अलग तरह से फेल होते हैं। एक छोटा API कॉल या तो तुरंत सफल होता है या एरर देता है। घंटों या दिनों तक चलने वाला वर्कफ़्लो 9 में से 9 कदम निकाल सकता है और फिर भी गड़बड़ी छोड़ सकता है: आधे-निर्मित रिकॉर्ड, भ्रमित स्थिति, और कोई स्पष्ट अगला कदम नहीं।
इसीलिए अक्सर मिलता है “यह कल काम कर रहा था”। वर्कफ़्लो बदलता नहीं, लेकिन उसका वातावरण बदल सकता है। लंबे वर्कफ़्लो दूसरे सर्विसेज़ के स्वस्थ रहने, क्रेडेंशियल्स के वैध रहने, और डेटा के अपेक्षित आकार में बने रहने पर निर्भर करते हैं।
सबसे सामान्य विफलता मोड इस तरह दिखते हैं: टाइमआउट और धीमे निर्भर (एक पार्टनर API आज 40 सेकंड ले रहा है), आंशिक अपडेट (रिकॉर्ड A बना, रिकॉर्ड B नहीं बना, और आप सुरक्षित रूप से फिर से चला नहीं सकते), निर्भरता आउटेज (ईमेल/SMS प्रदाता, पेमेंट गेटवे, रख-रखाव विंडो), खोए हुए कॉलबैक और मिस्ड शेड्यूल (एक वेबहुक कभी नहीं आया, एक टाइमर जॉब नहीं चला), और मानव कदम जो अटक जाते हैं (अनुमोदन दिनों तक पेंडिंग रहता है और फिर पुराने अनुमान के साथ फिर से शुरू होता है)।
कठिन भाग है स्टेट। एक “तेज़ अनुरोध” स्टेट को मेमोरी में तब तक रख सकता है जब तक वह पूरा न हो जाए। एक वर्कफ़्लो ऐसा नहीं कर सकता। उसे स्टेप्स के बीच स्टेट को परसेव करना होता है और रिस्टार्ट, डिप्लॉय या क्रैश के बाद फिर से रेज़्यूम करने के लिए तैयार रहना होता है। उसे यह भी संभालना होता है कि उसी स्टेप को दो बार ट्रिगर किया जाए (रीट्राइज़, डुप्लिकेट वेबहुक, ऑपरेटर रीप्ले)।
व्यवहार में “भरोसेमंद” का मतलब हमेशा न फेल होना नहीं बल्कि पूर्वानुमेय, समझाने योग्य, पुनर्प्राप्त करने योग्य और स्पष्ट रूप से किसी की ज़िम्मेदारी में होना है।
पूर्वानुमेय होने का अर्थ है कि वर्कफ़्लो हर बार एक ही तरह से प्रतिक्रिया दे जब कोई निर्भरता फेल हो। समझाने योग्य होने का अर्थ है कि कोई ऑपरेटर एक मिनट में जवाब दे सके—“यह किस पर अटका है और क्यों?” पुनर्प्राप्त करने योग्य का अर्थ है कि आप सुरक्षित रूप से फिर से प्रयास या जारी कर सकें बिना नुकसान किए। स्पष्ट स्वामित्व का मतलब है कि हर अटके हुए आइटम के पास एक स्पष्ट अगला कदम हो: प्रतीक्षा, रिट्राई, डेटा ठीक करना, या किसी व्यक्ति को सौंपना।
सरल उदाहरण: एक onboarding ऑटोमेशन ग्राहक रिकॉर्ड बनाता है, एक्सेस प्रोविजन करता है, और वेलकम संदेश भेजता है। अगर प्रोविजन सफल हो लेकिन मेसेजिंग फेल हो क्योंकि ईमेल प्रोवाइडर डाउन है, तो एक भरोसेमंद वर्कफ़्लो "Provisioned, message pending" रिकॉर्ड करता है और रिट्राई शेड्यूल करता है। यह अंधाधुंध प्रोविजनिंग को फिर से नहीं चलाता।
टूल्स इससे आसान बना सकते हैं जब वर्कफ़्लो लॉजिक और परसिस्टेंट डेटा पास-पास रखें। उदाहरण के लिए, AppMaster आपको Data Designer के ज़रिए वर्कफ़्लो स्टेट मॉडल करने और Business Processes से अपडेट करने देता है। लेकिन भरोसेमंदी पैटर्न से आती है, टूल से नहीं: लंबे वर्कफ़्लो को ऐसे टिकाऊ स्टेट्स की श्रेणी मानें जो समय, विफलताओं और मानव हस्तक्षेप से बच सकें।
लंबे वर्कफ़्लो अक्सर दोहराए जाने योग्य तरीकों से फेल होते हैं: तीसरे पक्ष का API धीमा हो जाता है, किसी ने मंज़ूरी नहीं दी, या कोई जॉब कतार में इंतजार कर रहा है। स्पष्ट स्टेट्स उन स्थितियों को तुरंत स्पष्ट कर देते हैं, ताकि लोग “समय लग रहा है” को “टूटा हुआ” न समझें।
एक छोटे सेट के साथ शुरू करें जो एक सवाल का जवाब दे: अभी क्या हो रहा है? अगर आपके पास 30 स्टेट्स हैं, तो कोई उन्हें याद नहीं रखेगा। लगभग 5 से 8 के साथ ऑन-कॉल व्यक्ति सूची स्कैन कर के समझ सकता है।
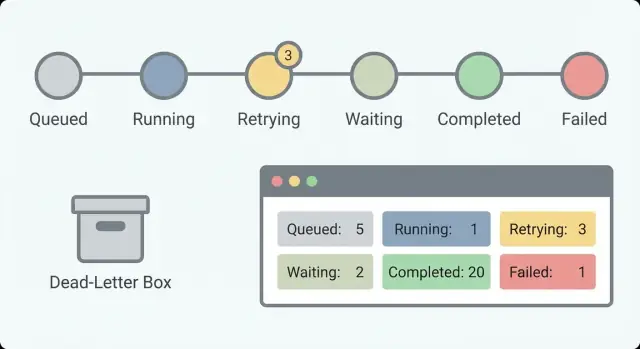
कई वर्कफ़्लो के लिए काम करने वाला व्यावहारिक स्टेट सेट:\n
Queued (बना हुआ पर शुरू नहीं हुआ)\n- Running (सक्रिय रूप से काम कर रहा)\n- Waiting (टाइमर, कॉलबैक, या मानव इनपुट पर रुका हुआ)\n- Succeeded (पूरा हुआ)\n- Failed (त्रुटि के साथ रूका हुआ)\n
Waiting और Running को अलग रखना मायने रखता है। “Waiting for customer response” स्वस्थ है। “Running for 6 hours” संभवत: फंसा हुआ है। बिना इस विभाजन के आप झूठे अलार्म पीछा करेंगे और असली को मिस करेंगे।एक स्टेट नाम पर्याप्त नहीं है। स्थिति को क्रियाशील बनाने के लिए कुछ फ़ील्ड जोड़ें:\n
स्टेट नामों को API जैसा व्यवहार दें। अगर आप हर महीने उन्हें रीनाम करेंगे तो डैशबोर्ड, अलर्ट, और सपोर्ट प्लेबुक जल्दी भ्रमित हो जाएँगे। अगर नए अर्थ की जरूरत है, तो नया स्टेट जोड़ने पर विचार करें और पुराने को मौजूदा रिकॉर्ड के लिए रहने दें।
AppMaster में आप Data Designer में इन स्टेट्स को मॉडल कर सकते हैं और Business Process लॉजिक से उन्हें अपडेट कर सकते हैं। इससे स्टेट लॉग्स में दबे रहने के बजाय आपकी ऐप में दिखाई देगा और सुसंगत रहेगा।
रिट्राइज़ मददगार होते हैं जब तक वे असली समस्या छुपा न दें। लक्ष्य "कभी न फेल होना" नहीं है। लक्ष्य है "ऐसा फेल होना जिसे लोग समझ सकें और ठीक कर सकें"। यह स्पष्ट नियम से शुरू होता है कि क्या retry करने योग्य है और क्या नहीं।
एक नियम जो अधिकांश टीमें अपना सकती हैं: उन त्रुटियों को retry करें जो संभवतः अस्थायी हैं (नेटवर्क टाइमआउट, रेट लिमिट, छोटे तीसरे-पक्ष आउटेज)। उन त्रुटियों को retry न करें जो स्पष्ट रूप से स्थायी हैं (invalid input, missing permissions, “account closed”, “card declined”)। अगर आप बता नहीं पा रहे कि कौन से बकेट में त्रुटि आती है, तो सीखने तक उसे गैर-रीट्रायबल मानें।
retry काउंटर प्रति स्टेप (या प्रत्येक बाहरी कॉल के लिए) ट्रैक करें, न कि पूरे वर्कफ़्लो के लिए एक ही काउंटर। एक वर्कफ़्लो में दस स्टेप हो सकते हैं और केवल एक ही flaky हो सकता है। स्टेप-स्तरीय काउंटर बाद के स्टेप को पहले वाले प्रयास चोरी करने से रोकते हैं।
उदाहरण के लिए, "Upload document" कॉल को कुछ बार retry किया जा सकता है, जबकि "Send welcome email" को अनिश्चितकाल तक retry नहीं किया जाना चाहिए सिर्फ इसलिए कि अपलोड ने पहले प्रयासों को ख़त्म कर दिया।
जो जोखिम है उसके अनुरूप बैकऑफ पैटर्न चुनें। सरल, कम-खर्च रिट्राईज़ के लिए फिक्स्ड डिले ठीक हो सकते हैं। एक्सपोनेंशियल बैकऑफ रेट-लिमिट्स के मामले में मदद करता है। प्रतीक्षाएँ अनंत न होँ इसलिए कैप रखें, और रिट्राई स्टॉर्म से बचने के लिए थोड़ा jitter जोड़ें।
फिर तय करें कब रुकना है। अच्छे स्टॉप कंडीशंस स्पष्ट होते हैं: अधिकतम प्रयास, अधिकतम कुल समय, या कुछ त्रुटि-कोड्स पर “हाथ खड़ा कर देना”। जैसे पेमेंट गेटवे “invalid card” लौटाए तो तुरंत रुक जाना चाहिए भले ही आप आमतौर पर पांच प्रयास की अनुमति देते हैं।
ऑपरेटरों को यह भी जानना चाहिए कि अगला क्या होगा। अगली retry समय और कारण रिकॉर्ड करें (उदाहरण के लिए, “Retry 3/5 at 14:32 due to timeout”)। AppMaster में आप इसे वर्कफ़्लो रिकॉर्ड पर स्टोर कर सकते हैं ताकि डैशबोर्ड अनुमान न लगाए और सीधे “waiting until” दिखा सके।
एक अच्छा retry पॉलिसी एक ट्रेल छोड़ती है: क्या फेल हुआ, कितनी बार कोशिश की गई, अगली बार कब कोशिश होगी, और कब यह रुककर डेड-लेट्टर हैंडलिंग को सौंप दिया जाएगा।
घंटों या दिनों तक चलने वाले वर्कफ़्लो में retries सामान्य हैं। जोखिम यह है कि एक ऐसा स्टेप जो पहले ही सफल हो गया उसे दोबारा चलाया जाना। आइडेम्पोटेंसी वह नियम है जो इसे सुरक्षित बनाता है: एक स्टेप आइडेम्पोटेंट तब है जब उसे दो बार चलाने से वही प्रभाव हो जैसे एक बार चलाने से होता।
एक क्लासिक विफलता: आप कार्ड चार्ज करते हैं, फिर वर्कफ़्लो क्रैश करता है पहले कि यह “payment succeeded” सेव कर पाए। retry पर यह फिर से चार्ज कर देता है। यह डबल-राइट समस्या है: बाहरी दुनिया बदल गई, पर आपका वर्कफ़्लो स्टेट नहीं।
सबसे सुरक्षित पैटर्न है कि हर साइड-इफेक्टिंग स्टेप के लिए एक स्थिर idempotency key बनाएं, उसे बाहरी कॉल के साथ भेजें, और परिणाम मिलते ही स्टेप रिज़ल्ट सेव कर लें। कई पेमेंट प्रोवाइडर्स और वेबहुक रिसीवर idempotency keys सपोर्ट करते हैं (उदाहरण के लिए, OrderID से चार्ज करना)। यदि स्टेप दोहराया जाता है तो प्रोवाइडर मूल परिणाम देता है बजाय कार्रवाई को फिर से करने के।
अपने वर्कफ़्लो इंजन के अंदर हर स्टेप को दोहराया जा सकता मानें। AppMaster में अक्सर इसका मतलब है कि स्टेप आउटपुट्स को अपने डेटाबेस मॉडल में सेव करना और किसी इंटीग्रेशन को फिर से कॉल करने से पहले Business Process में उन्हें चेक करना। अगर “Send welcome email” का पहले से MessageID रिकॉर्ड है तो retry उसे रीयूज़ कर के आगे बढ़ना चाहिए।
एक व्यवहारिक डुप्लिकेट-सेफ तरीका:\n
डुप्लिकेट्स अभी भी होते हैं, खासकर इनबाउंड वेबहुक्स या जब उपयोगकर्ता बार-बार वही बटन दबाए। इवेंट टाइप के अनुसार पॉलिसी तय करें: सटीक डुप्लिकेट्स (समान idempotency key) को इग्नोर करें, संगत अपडेट्स को मर्ज करें (जैसे प्रोफ़ाइल फ़ील्ड के लिए last-write-wins), या जब पैसे या अनुपालन का जोखिम हो तो समीक्षा के लिए फ्लैग करें।
डेड-लेट्टर वह वर्कफ़्लो आइटम है जिसे आप जानबूझकर सामान्य पथ से हटाते हैं ताकि वह बाकी सबको ब्लॉक न करे। मकसद यह है कि यह समझना और तय करना आसान हो कि क्या हुआ, क्या ठीक हो सकता है, और सुरक्षित तरीके से पुनःप्रोसेस कैसे करें।
सबसे बड़ी गलती केवल एक एरर मैसेज सेव करना है। जब कोई बाद में डेड-लेट्टर देखेगा, तो उसे समस्या को बिना अनुमान लगाए पुन:उत्पादित करने के लिए पर्याप्त संदर्भ चाहिए।
एक उपयोगी डेड-लेट्टर एंट्री में शामिल हो:\n
रिप्रोसेसिंग नियंत्रित होनी चाहिए। मकसद दोहराव से होने वाले नुकसान—जैसे दो बार चार्ज करना या ईमेल स्पैम करना—को रोकना है। तय करें कौन retry कर सकता है, कब retry किया जा सकता है, क्या बदला जा सकता है (निश्चित फ़ील्ड संपादित करना, दस्तावेज़ जोड़ना, टोकन रीफ्रेश करना), और क्या अपरिवर्तनीय रहना चाहिए (request ID और डाउनस्ट्रीम idempotency keys)।
डेड-लेट्टर आइटम को स्थिर पहचानकर्ताओं से searchable बनाएं। जब एक ऑपरेटर "order 18422" टाइप कर के सही स्टेप, इनपुट्स, और प्रयास इतिहास देख सके तो सुधार तेज और सुसंगत बनता है।
अगर आप इसे AppMaster में बनाते हैं, तो डेड-लेट्टर को एक first-class डेटाबेस मॉडल मानें और स्टेट, प्रयास, और पहचानकर्ताओं को फ़ील्ड के रूप में स्टोर करें। इस तरह आपका आंतरिक डैशबोर्ड क्वेरी, फ़िल्टर और नियंत्रित रीप्रोसेस कार्रवाई ट्रिगर कर सकेगा।
लंबे वर्कफ़्लो धीमी, भ्रमित करने वाली विफलताओं में फेल हो सकते हैं: एक स्टेप ईमेल उत्तर का इंतजार कर रहा है, पेमेंट प्रोवाइडर टाइमआउट दे रहा है, या एक वेबहुक दो बार आया। अगर आप देख नहीं सकते कि वर्कफ़्लो अभी क्या कर रहा है, तो आप अनुमान लगाने लगते हैं। अच्छी दृश्यता “यह टूट गया है” को एक स्पष्ट उत्तर में बदल देती है: कौन सा वर्कफ़्लो, कौन सा स्टेप, कौन सा स्टेट, और अगला क्या कदम है।
हर स्टेप से एक समान छोटा सेट फ़ील्ड्स उत्सर्जित करवाना शुरू करें ताकि ऑपरेटर जल्दी स्कैन कर सके:\n
Started, completed, failed, retrying, और waiting को समय के साथ ट्रैक करें। एक छोटा waiting नंबर सामान्य हो सकता है (मानव अनुमोदन)। एक बढ़ता हुआ waiting काउंट सामान्यतः यह बताता है कि कुछ ब्लॉक है। एक बढ़ता हुआ retrying काउंट अक्सर किसी प्रोवाइडर समस्या या उसी एरर को बार-बार हिट करने वाले बग की ओर इशारा करता है।
अलार्म्स को उन लक्षणों के अनुसार मैच करें जिन्हें ऑपरेटर अनुभव करते हैं। "त्रुटि हुई" के बजाय संकेतों पर अलर्ट करें: बढ़ती बैकलॉग (started minus completed लगातार बढ़ रहा है), अपेक्षित समय से अधिक समय तक स्टक हुए वर्कफ़्लो, किसी विशिष्ट स्टेप के लिए उच्च retry दर, या रिलीज़/कॉनफ़िग परिवर्तन के तुरंत बाद फ़ेल स्पाइक।
हर वर्कफ़्लो के लिए एक इवेंट ट्रेल रखें ताकि “क्या हुआ?” एक दृश्य में जवाबी हो। उपयोगी ट्रेल में टाइमस्टैम्प, स्टेट ट्रांज़िशन्स, इनपुट्स और आउटपुट्स के सार (संपूर्ण संवेदनशील पेलोड नहीं), और retry या फेल का कारण शामिल होना चाहिए। उदाहरण: “Charge card: retry 3/5, timeout from provider, next attempt in 10m.”
Correlation IDs गोंद का काम करते हैं। अगर ग्राहक कहता है “मेरी payment दो बार चार्ज हुई,” तो आपको अपने वर्कफ़्लो इवेंट्स को पेमेंट प्रोवाइडर के चार्ज ID और अपनी आंतरिक ऑर्डर ID से कनेक्ट करना होगा। AppMaster में, आप Business Process लॉजिक में correlation IDs जनरेट और पास करके यह मानकीकृत कर सकते हैं ताकि डैशबोर्ड और लॉग्स मेल खाएँ।
जब वर्कफ़्लो घंटे या दिन चलता है, तो विफलताएँ सामान्य हैं। जो चीजें सामान्य विफलताओं को आउटेज में बदल देती हैं वे हैं डैशबोर्ड जो सिर्फ "Failed" कहता है और कुछ नहीं। लक्ष्य है कि ऑपरेटर तीन सवालों का जल्दी उत्तर पा सके: क्या हो रहा है, क्यों हो रहा है, और वे सुरक्षित रूप से अगला क्या कर सकते हैं।
एक वर्कफ़्लो सूची से शुरू करें जो महत्वपूर्ण आइटम्स ढूँढना आसान बनाए। फ़िल्टर्स भय और अनावश्यक चैट को कम करते हैं क्योंकि कोई भी व्यू जल्दी संकुचित कर सकता है।
उपयोगी फ़िल्टरों में शामिल हैं: state, age (started time और current state में समय), owner (team/customer/responsible operator), type (workflow name/version), और priority अगर ग्राहक-सम्बद्ध कदम हों।
अगला, स्थिति के पास ही “क्यों” दिखाएँ न कि लॉग में छिपाएँ। एक स्थिति पिल तब ही मददगार है जब वह आख़िरी एरर मैसेज, एक छोटा एरर श्रेणी, और सिस्टम अगला क्या करने की योजना बना रहा है भी दिखाए। दो फ़ील्ड अधिकांश काम करते हैं: last error और next retry time। अगर next retry खाली है, तो स्पष्ट करें कि वर्कफ़्लो मानव के लिए इंतजार कर रहा है, paused है, या स्थायी रूप से फेल है।
ऑपरेटर एक्शन्स डिफ़ॉल्ट रूप से सुरक्षित होने चाहिए। लोगों को पहले कम-जोखिम वाले एक्शन्स की ओर मार्गदर्शन करें और जोखिमभरे एक्शन्स को स्पष्ट बनाएं:\n
ऑपरेटर के हर काम का ऑډिट रखें। रिकॉर्ड करें किसने क्या किया, कब किया, before/after स्टेट, और कारण नोट। अगर आप आंतरिक टूल AppMaster में बनाते हैं तो इस ऑडिट ट्रेल को first-class टेबल के रूप में रखें और वर्कफ़्लो डिटेल पेज पर दिखाएँ ताकि हैंडऑफ़ साफ़ रहें।
यह पैटर्न वर्कफ़्लो को पूर्वानुमेय रखता है: हर आइटम हमेशा एक स्पष्ट स्टेट में रहता है, हर विफलता का एक ठोस रास्ता होता है, और ऑपरेटर बिना अनुमान लगाए कार्रवाई कर सकता है।
Step 1: स्टेट्स और allowed transitions परिभाषित करें। एक छोटा सेट लिखें जिसे कोई समझ सके (उदा: Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter) और तय करें कौन से मूव्स कानूनी हैं ताकि काम limbo में न फँसे।
Step 2: काम को छोटे स्टेप्स में बाँटें जिनके स्पष्ट इनपुट और आउटपुट हों। हर स्टेप एक परिभाषित इनपुट ले और एक आउटपुट (या स्पष्ट एरर) दे। अगर मानव निर्णय या बाहरी API कॉल की जरूरत है तो उसे अलग स्टेप बनाएं ताकि वह आराम से.pause और resume कर सके।
Step 3: हर स्टेप पर retry पॉलिसी जोड़ें। प्रयास सीमा, प्रयासों के बीच देरी, और उन्हीं कारणों को चुनें जिन पर कभी retry नहीं होगा (invalid data, permission denied, missing required fields)। प्रत्येक स्टेप के लिए retry काउंटर स्टोर करें ताकि ऑपरेटर ठीक से देख सके क्या अटका है।
Step 4: हर स्टेप के पूरा होने के बाद प्रगति परसेव करें। स्टेप खत्म होने के बाद नया स्टेट और प्रमुख आउटपुट सेव करें। अगर प्रोसेस रिस्टार्ट हो तो इसे आख़िरी पूरा किये गए स्टेप से जारी होना चाहिए, न कि फिर से शुरू होना चाहिए।
Step 5: retries समाप्त होने पर डेड-लेट्टर रिकॉर्ड पर रूट करें और रीप्रोसेसिंग का समर्थन रखें। जब retries खत्म हों तो आइटम को डेड-लेट्टर स्टेट में भेजें और पूरा संदर्भ रखें: इनपुट्स, आख़िरी त्रुटि, स्टेप नाम, प्रयास काउंट और टाइमस्टैम्प। रीप्रोसेसिंग इरादतन होनी चाहिए: पहले डेटा या कॉन्फ़िग ठीक करें, फिर किसी विशेष स्टेप से फिर से कतार में डालें।
Step 6: डैशबोर्ड फ़ील्ड और ऑपरेटर एक्शन्स परिभाषित करें। एक अच्छा डैशबोर्ड पूछता है “क्या फेल हुआ, कहाँ, और मैं क्या कर सकता हूँ?” AppMaster में आप इसे अपने वर्कफ़्लो टेबल्स से बैक करके एक सरल एडमिन वेब ऐप बना सकते हैं।
शामिल प्रमुख फ़ील्ड और एक्शन्स:\n
कर्मचारी onboarding एक अच्छा स्ट्रेस टेस्ट है। इसमें अनुमोदन, बाहरी सिस्टम, और ऐसे लोग शामिल होते हैं जो ऑफ़लाइन हो सकते हैं। सरल फ्लो हो सकता है: HR नया हायर फॉर्म सबमिट करता है, मैनेजर approve करता है, IT अकाउंट बनते हैं, और नया हायर वेलकम मेसेज पाता है।
स्टेट्स को पठनीय रखें। जब कोई रिकॉर्ड खोले तो उसे तुरंत “Waiting for approval” और “Retrying account setup” के बीच फर्क दिखना चाहिए। एक पंक्ति की स्पष्टता अक्सर एक घंटे का अनुमान बचा सकती है।
UI में दिखाने के लिए स्पष्ट स्टेट्स का सेट:\n
डेड-लेट्टर हैंडलिंग उन समस्याओं के लिए है जो स्वयं ठीक नहीं होंगी: फॉर्म पर कोई मैनेजर नहीं, invalid email address, या एक्सेस अनुरोध जो नीति से टकराता है। जब आप किसी रन को डेड-लेट्टर करते हैं तो संदर्भ स्टोर करें: कौन सा फ़ील्ड वेलिडेशन में फेल हुआ, आख़िरी API रिस्पॉन्स, और किसे ओवरराइड करने का अधिकार है।
ऑपरेटर के पास छोटे और सरल एक्शन्स होने चाहिए: डेटा ठीक करें (मैनेजर जोड़ें, ईमेल सही करें), केवल एक फेल स्टेप को फिर से चलाएँ (संपूर्ण वर्कफ़्लो नहीं), या साफ़-सुथरा कैंसिल करें (आवश्यक हो तो आंशिक सेटअप को undo करें)।
AppMaster के साथ, आप इसे Business Process Editor में मॉडल कर सकते हैं, retry काउंट को डेटा में रख सकते हैं, और वेब UI बिल्डर में एक ऑपरेटर स्क्रीन बना सकते हैं जो स्टेट, आख़िरी एरर, और failed step को retry करने का बटन दिखाता है।
अधिकांश भरोसेमंदी समस्याएँ अनुमानित होती हैं: एक स्टेप दो बार चलता है, retries रात को 2 बजे स्पिन करते हैं, या एक “stuck” आइटम के पास कोई सुराग नहीं होता कि आख़िरी बार क्या हुआ। एक चेकलिस्ट इसे अनुमान से बचाती है।
जल्दी पकड़ने के लिए त्वरित चेक्स:\n
एक व्यावहारिक ऑपरेटर व्यू में शामिल होना चाहिए: वर्तमान स्टेट, आख़िरी एरर मैसेज, प्रयास काउंट, अगली retry समय, और एक स्पष्ट एक्शन (retry now, mark as resolved, या send to manual review)। डिफ़ॉल्ट सेफ्टी रखें: एक स्टेप को फिर से चलाएँ, न कि पूरा वर्कफ़्लो।
अगले कदम:\n
इसे एक जीवित चेकलिस्ट मानें। जब भी आप कोई नया स्टेप जोड़ें, प्रोडक्शन में पहुँचने से पहले इन चेक्स को चलाएँ।
लंबे-समय वाले वर्कफ़्लो कई घंटों तक सही चले और फिर अंत में फेल हो सकते हैं, जिससे आंशिक बदलाव छोड़ जाते हैं। ये ऐसे घटकों पर निर्भर होते हैं जो बीच में बदल सकते हैं—तीसरे पक्ष की सेवाएँ, प्रमाण-पत्र, डेटा का स्वरूप, या मानव प्रतिक्रिया का समय।
राज़दार और छोटा सेट रखें ताकि ऑपरेटर एक नज़र में समझ सके। एक अच्छा डिफ़ॉल्ट सेट है: queued, running, waiting, succeeded, और failed। ‘Waiting’ को ‘Running’ से अलग रखें ताकि स्वस्थ विराम और फंसा हुआ चरण अलग दिखे।
स्थिति को कार्यशील बनाने के लिए पर्याप्त जानकारी रखें: वर्तमान स्टेट, आख़िरी बार कब बदला, पिछले स्टेट क्या था, और यदि वेटिंग या फेल हुआ है तो एक छोटा कारण। यदि आप retry करते हैं तो प्रयास गिनती और अगली योजना की समय-सूची भी रखें।
यह झूठे अलार्म और खोये हुए घटनाओं को रोकता है। “Waiting for approval” या “waiting for a webhook” स्वस्थ हो सकते हैं, जबकि “running for six hours” एक फंसा हुआ चरण हो सकता है—इन्हें अलग स्टेट में रखना बेहतर निर्णय और अलर्ट देता है।
वह त्रुटियाँ जो अस्थायी हो सकती हैं—नेटवर्क टाइमआउट, रेट-लिमिट, छोटे आउटेज—उनको पुनःप्रयास करें। जिन त्रुटियों से स्पष्ट रूप से पता चलता है कि वे स्थायी हैं (जैसे invalid input, missing permissions, या declined payment), उनका पुनःप्रयास न करें। यदि स्पष्ट न हो तो शुरुआत में गैर-रीट्रायबल मानें।
स्टेप-स्तरीय retries एक उस समय की समस्या को रोकते हैं जहाँ एक खराब स्टेप पूरे वर्कफ़्लो के सभी प्रयास खा जाता है। इससे पता लगाना भी आसान होता है कि कौन सा स्टेप फेल हो रहा है और कितनी बार कोशिश की गई।
जो जोखिम आप सामना कर रहे हैं उसके अनुसार सरल बैकऑफ चुनें, और हमेशा एक कैप रखें ताकि प्रतीक्षाएँ अनंत न हो जाएँ। रोकने के नियम स्पष्ट रखें—जैसे अधिकतम प्रयास, अधिकतम कुल समय, या कुछ त्रुटि कोड्स पर तुरंत रुकना। अगली शेड्यूल्ड retry और असफलता का कारण रिकॉर्ड करें ताकि जिम्मेदारी स्पष्ट हो।
हर स्टेप को इस तरह डिज़ाइन करें कि उसे दोहराने से नुकसान न हो। सामान्य तरीका: हर साइड-इफेक्टिंग स्टेप के लिए एक स्थिर idempotency key बनाएं, “step started” रिकॉर्ड लिखें, सफल होने पर रिस्पॉन्स सेव करें ताकि पुनःप्रयास पर वही परिणाम वापिस मिले और न कि कार्रवाई दोहराई जाए।
डेड-लेट्टर उस आइटम को दर्शाता है जिसे सामान्य पथ से हटाकर रखा गया है ताकि वह बाकी को ब्लॉक न करे। ऐसा रिकॉर्ड रखें जिसमें पहचानकर्ता, इनपुट (या सुरक्षित स्नैपशॉट), जहाँ फेल हुआ, प्रयासों का इतिहास, और निर्भरता का त्रुटि उत्तर शामिल हो—सिर्फ एक संक्षिप्त संदेश नहीं।
डैशबोर्ड को यह जल्दी बताना चाहिए: कहाँ है, क्यों है, और आगे क्या होगा। लगातार फ़ील्ड जैसे workflow ID, current step, state, time in state, last error और correlation IDs दिखाएँ। ऑपरेटर के लिए सुरक्षित एक्शन दें—जैसे किसी एक स्टेप का रिट्राई—और जोखिमभरे एक्शन स्पष्ट रूप से लेबल करें ताकि “ठीक” करते हुए और नुकसान न हो।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


