उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
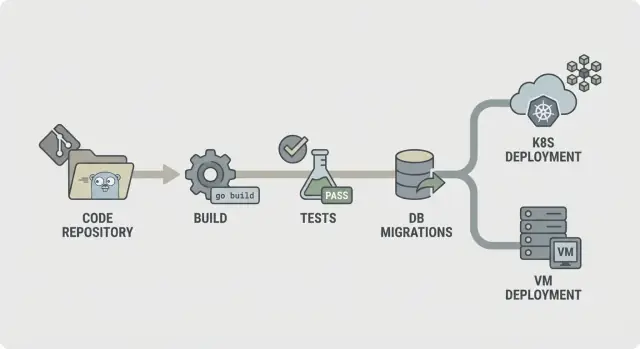
Go बैकएंड्स के लिए CI/CD: बिल्ड, टेस्ट, माइग्रेशन और Kubernetes या VMs पर सुरक्षित डिप्लॉय के व्यावहारिक पाइपलाइन कदम।
मैनुअल डिप्लॉयमेंट अक्सर नीरस, बार-बार होने वाली गलतियों से फेल होते हैं। कोई अपने लैपटॉप पर अलग Go वर्शन से बनाता है, कोई env वेरिएबल भूल जाता है, कोई माइग्रेशन छोड़ देता है, या गलती से गलत सर्विस रीस्टार्ट कर देता है। रिलीज़ “मेरे पास काम करता है”, पर प्रोडक्शन में नहीं चलता — और आपको यह तब पता चलता है जब यूज़र प्रभावित होते हैं।
जनरेट किए गए कोड से रिलीज़ डिसिप्लिन की ज़रूरत खत्म नहीं होती। जब आप आवश्यकताओं बदलने के बाद बैकएंड को रीजनरेट करते हैं, तो नए एंडपॉइंट, नए डेटा शेप या नई डिपेंडेंसी आ सकती हैं, भले ही आपने हाथ से कोड नहीं छुआ हो। ऐसे समय में पाइपलाइन सुरक्षा रेल की तरह काम आए: हर बदलाव हर बार एक जैसे चेक से गुजरे।
प्रीडिक्टेबल एन्वायरनमेंट का मतलब है कि आपका बिल्ड और डिप्लॉय स्टेप उस स्थिति में चलते हैं जिसे आप नाम दे कर दोहरा सकते हैं। कुछ नियम ज्यादातर मामलों को कवर कर देते हैं:
CI/CD का उद्देश्य सिर्फ ऑटोमेशन नहीं है। इसका मकसद कम तनाव के साथ रेप्रीडिकेटेबल रिलीज़ हैं: रीजनरेट करें, पाइपलाइन चलाएँ, और भरोसा करें कि जो निकले वह डिप्लॉय करने योग्य है।
अगर आप AppMaster जैसी जनरेटर का उपयोग करते हैं जो Go बैकएंड बनाता है, तो यह और भी महत्वपूर्ण हो जाता है। रीजनरेशन एक फीचर है, पर यह तभी सुरक्षित महसूस होता है जब बदलाव से प्रोडक्शन तक का रास्ता लगातार, टेस्टेड और पूर्वानुमेय हो।
“प्रीडिक्टेबल” का मतलब है कि वही इनपुट कभी भी, कहीं भी एक जैसा परिणाम दे। Go बैकएंड्स के लिए CI/CD में यह तय करना शुरू में ज़रूरी है कि dev, staging और prod में क्या चीज़ें बिल्कुल समान रहनी चाहिए।
सामान्य अस्वीकार्य चीज़ें हैं: Go वर्शन, आपका बेस OS इमेज, बिल्ड फ्लैग्स, और कॉन्फ़िग लोड करने का तरीका। अगर इनमें से कोई चीज़ environment के अनुसार बदलती है तो आपको TLS व्यवहार में अंतर, मिसिंग सिस्टम पैकेज, या ऐसे बग मिल सकते हैं जो सिर्फ प्रोडक्शन में दिखें।
ज़्यादातर एन्वायरनमेंट ड्रिफ्ट वहीँ दिखती है:
Kubernetes और VMs के बीच चुनाव “सबसे अच्छा” की तुलना में इस बात पर निर्भर करता है कि आपकी टीम किसे शांतिपूर्वक चला सकती है।
Kubernetes तब अच्छा है जब आपको autoscaling, rolling updates और कई सर्विसेस चलाने का एक मानक तरीका चाहिए। यह स्थिरता भी लागू करता है क्योंकि पाड्स एक ही इमेज से चलते हैं। VMs तब ठीक रहते हैं जब आपके पास एक या कुछ ही सर्विस हैं, टीम छोटी है और आप कम मूविंग पार्ट्स चाहते हैं।
पाइपलाइन को समान बनाए रखना संभव है भले ही रनटाइम अलग हों: आर्टिफैक्ट और उसके कॉन्ट्रैक्ट को स्टैण्डर्ड करें। उदाहरण के लिए: CI में हमेशा वही कंटेनर इमेज बनाएं, वही टेस्ट स्टेप्स चलाएँ, और वही माइग्रेशन बंडल प्रकाशित करें। तब सिर्फ़ deploy स्टेप बदलेगा: Kubernetes नया इमेज टैग लगाता है, जबकि VMs इमेज खींचकर सर्विस रीस्टार्ट करते हैं।
व्यावहारिक उदाहरण: एक टीम AppMaster से जनरेटेड Go बैकएंड को staging पर Kubernetes में और production में VM पर डिप्लॉय करती है। अगर दोनों बिल्कुल वही इमेज खींचते हैं और समान तरह के सीक्रेट स्टोर से कॉन्फ़िग लोड करते हैं, तो “अलग रनटाइम” केवल डिप्लॉयमेंट का विवरण बन जाता है, बग का स्रोत नहीं। AppMaster (appmaster.io) उपयोग करने पर यह मॉडल अच्छी तरह फिट करता है क्योंकि आप managed cloud targets पर डिप्लॉय कर सकते हैं या स्रोत को एक्सपोर्ट करके अपने इंफ्रास्ट्रक्चर पर वही पाइपलाइन चला सकते हैं।
प्रीडिक्टेबल पाइपलाइन को समझाने में आसान होना चाहिए: कोड चेक करें, बनाएं, साबित करें कि यह काम करता है, वही चीज़ शिप करें जिसे आपने टेस्ट किया, फिर हर बार उसी तरह डिप्लॉय करें। यह स्पष्टता तब और महत्वपूर्ण हो जाती है जब आपका बैकएंड रीजनरेट होता है (उदाहरण के लिए, AppMaster से), क्योंकि बदलाव कई फाइलों को छू सकते हैं और आप तेज़, लगातार फ़ीडबैक चाहते हैं।
एक सीधा सा CI/CD फ्लो आम तौर पर इस तरह दिखता है:
इसे इस तरह बनाएं कि फ़ेलियर जल्दी रुक जाएँ। अगर lint फेल हो तो आगे कुछ भी न चले। अगर build फेल हो तो integration checks के लिए डेटाबेस स्टार्ट करके समय न गंवाएँ। इससे लागत कम रहती है और पाइपलाइन त्वरित महसूस होती है।
हर स्टेप हर कमिट पर चलना ज़रूरी नहीं। एक आम विभाजन है:
निर्धारित करें कि आप क्या आर्टिफैक्ट के रूप में रखते हैं। आम तौर पर वो compiled binary या container image होता है (जिसे आप डिप्लॉय करते हैं), साथ में माइग्रेशन लॉग और टेस्ट रिपोर्ट। इन्हें रखने से रोलबैक और ऑडिट आसान होते हैं क्योंकि आप बता सकते हैं कि किसे टेस्ट और प्रमोट किया गया था।
बिल्ड स्टेज का एक सवाल होना चाहिए: क्या हम आज, कल और किसी दूसरे रनर पर वही बाइनरी बना सकते हैं? अगर यह सही नहीं है, तो आगे के स्टेप्स (टेस्ट, माइग्रेशन, डिप्लॉय) पर भरोसा करना मुश्किल हो जाएगा।
शुरूआत environment को पिन करने से करें। फिक्स्ड Go वर्शन (उदा. 1.22.x) और फिक्स्ड रनर इमेज (Linux distro और पैकेज वर्शन) का उपयोग करें। "latest" टैग्स से बचें। libc, Git या Go टूलचेन में छोटे बदलाव "मेरे मशीन पर चलता था" जैसी गलतियों का कारण बन सकते हैं जिन्हें डिबग करना दर्दनाक होता है।
मॉड्यूल कैशिंग मदद करती है, पर इसे स्पीड बूस्ट की तरह ही समझें, ट्रूथ का स्रोत नहीं। Go build cache और मॉड्यूल डाउनलोड कैश को कैश करें, पर इसे go.sum से की करें (या जब deps बदलें तो main पर साफ़ करें) ताकि नई डिपेंडेंसीज़ पर क्लीन डाउनलोड ट्रिगर हो।
कम्पाइलेशन से पहले एक तेज़ गेट जोड़ें। इसे उतना तेज़ रखें ताकि डेवेलपर इसे बाईपास न करें। आम सेट है gofmt चेक्स, go vet, और यदि तेज़ रहे तो staticcheck। साथ ही मिसिंग या stale generated फाइलों पर फेल करें — यह रीजनरेटेड कोडबेस में आम समस्या है।
रिप्रोड्यूसिबली तरीके से कम्पाइल करें और वर्शन जानकारी एम्बेड करें। -trimpath जैसे फ़्लैग्स मदद करते हैं, और आप -ldflags से commit SHA और build time डाल सकते हैं। प्रति सर्विस एक नामित आर्टिफैक्ट बनाएं। इससे Kubernetes या VM पर क्या चल रहा है, ट्रेस करना आसान हो जाता है, खासकर जब आपका बैकएंड रीजनरेट हो रहा हो।
टेस्ट तब ही मदद करते हैं जब वे हर बार एक ही तरह चलें। पहले तेज़ फ़ीडबैक पर ध्यान दें, फिर गहराई वाले चेक जोड़ें जो अभी भी एक पूर्वानुमेय समय में खत्म हों।
हर कमिट पर यूनिट टेस्ट्स से शुरू करें। एक सख्त टाइमआउट रखें ताकि अटके हुए टेस्ट्स पाइपलाइन को हैंग न कर दें। यह भी तय करें कि टीम के लिए “पर्याप्त” कवरेज क्या है। कवरेज ट्रॉफी नहीं है, पर एक न्यूनतम बार गुणवत्ता सलोफ़्ट ड्रिफ्ट को रोकती है।
एक स्थिर टेस्ट स्टेज आमतौर पर शामिल करता है:
go test ./... को प्रति-पैकेज टाइमआउट और ग्लोबल जॉब टाइमआउट के साथ चलाएँ।रेस डिटेक्टर उपयोगी है, पर यह बिल्ड को काफी धीमा कर सकता है। अच्छा समझौता है PRs और नाइटली बिल्ड्स पर इसे चलाना, या केवल चुने हुए पैकेजेस पर चलाना, हर पुश पर नहीं।
फ्लेकी टेस्ट्स को बिल्ड फेल करना चाहिए। यदि किसी टेस्ट को क्वारंटीन करना ही पड़े तो उसे विजिबल रखें: उसे अलग जॉब में ले जाएँ जो फिर भी रन होकर रेड रिपोर्ट करे, और उसके लिए एक owner और डेडलाइन आवश्यक रखें।
डिबगिंग के लिए टेस्ट आउटपुट स्टोर करें ताकि सब कुछ दुबारा चलाना न पड़े। रॉ लॉग्स के साथ एक सरल रिपोर्ट (पास/फेल, अवधि, और सबसे धीमे टेस्ट) सेव करें। यह रीजनरेटेड बदलावों से प्रभावित होने पर रिग्रेशन पकड़ने में सहायक होगा।
यूनिट टेस्ट्स बताते हैं कि आपका कोड अलग होकर काम करता है। इंटीग्रेशन चेक्स बताते हैं कि जब सर्विस बूट होती है, रियल सर्विसेज से कनेक्ट करती है और रिक्वेस्ट हैंडल करती है तो व्यवहार कैसा रहता है। यह वह सुरक्षा नेट है जो उन मुद्दों को पकड़ता है जो सिर्फ़ सब कुछ जुड़ने पर दिखते हैं।
यदि आपके कोड को स्टार्ट होने के लिए कुछ चाहिए तो एपhemeral डिपेंडेंसीज़ का इस्तेमाल करें। नौकरी के लिए सिर्फ़ एक अस्थायी PostgreSQL (और जरूरत हो तो Redis) पर्याप्त होता है। वर्शन प्रोडक्शन के करीब रखें, पर हर प्रोडक्शन डिटेल कॉपी करने की कोशिश न करें।
एक अच्छा इंटीग्रेशन स्टेज जानबूझकर छोटा होता है:
API कॉन्ट्रैक्ट चेक्स के लिए उन एंडपॉइंट्स पर ध्यान दें जो टूटने से सबसे ज़्यादा नुकसान होगा। आपको पूरा end-to-end सूट नहीं चाहिए। कुछ request/response सत्याएँ पर्याप्त हैं: आवश्यक फ़ील्ड्स 400 से रिजेक्ट हों, auth माँगने पर 401 लौटे, और हैप्पी-पाथ रिक्वेस्ट 200 के साथ अपेक्षित JSON कीज़ दे।
इंटीग्रेशन टेस्ट्स को बार-बार चलाने योग्य रखने के लिए स्कोप को सीमित रखें और क्लॉक को नियंत्रित करें। एक छोटा डेटाबेस रखें, कुछ ही रिक्वेस्ट्स चलाएँ, और सख्त टाइमआउट सेट करें ताकि स्टक बूट सेकंड्स में फेल हो, मिनटों में नहीं।
यदि आप अपना बैकएंड रीजनरेट करते हैं (उदा. AppMaster के साथ), तब ये चेक्स और भी ज़्यादा वजन रखते हैं। ये पुष्टि करते हैं कि रीजनरेटेड सर्विस साफ़ तरीके से शुरू होती है और वह API बोलती है जिसकी आपकी वेब/मोबाइल ऐप को उम्मीद है।
पहले तय करें कि माइग्रेशन कहाँ चलेंगे। CI में उन्हें चलाना शुरुआती त्रुटियाँ पकड़ने के लिए अच्छा है, पर CI को आम तौर पर प्रोडक्शन तक नहीं छूना चाहिए। अधिकांश टीमें माइग्रेशन को डिप्लॉय के दौरान (एक समर्पित स्टेप) चलाती हैं या एक अलग “migrate” जॉब के रूप में जो नए वर्शन के शुरू होने से पहले पूरा होना चाहिए।
एक व्यावहारिक नियम: CI में बिल्ड और टेस्ट करें, फिर माइग्रेशन को प्रोडक्शन के जितना पास हो सके उतना पास चलाएँ, प्रोडक्शन क्रेडेंशियल्स और प्रोडक्शन-जैसे लिमिट्स के साथ। Kubernetes में यह अक्सर एक one-off Job होता है। VMs पर यह रिलीज़ स्टेप में एक स्क्रिप्टेड कमांड हो सकता है।
ऑर्डरिंग अपेक्षा से ज़्यादा मायने रखती है। टाइमस्टैम्पेड फाइलें (या सीक्वेंशियल नंबर) इस्तेमाल करें और “ठीक उसी क्रम में, एक बार लागू करें” का पालन कराएं। जहाँ संभव हो माइग्रेशन को idempotent बनाएं, ताकि retry करने पर डुप्लिकेट न बने या आधा‑आधा क्रैश न हो।
माइग्रेशन रणनीति सरल रखें:
कुछ चलाने से पहले एक सुरक्षा गेट जोड़ें। यह एक डेटाबेस लॉक हो सकता है ताकि एक समय में सिर्फ़ एक माइग्रेशन चले, और एक नीति जैसे “बिन अनुमोदन के कोई destructive बदलाव नहीं” लागू करें। उदाहरण के लिए, पाइपलाइन फेल कर दें अगर माइग्रेशन में DROP TABLE या DROP COLUMN है जब तक मैन्युअल गेट अप्रूव न हो।
रोलबैक कठोर सच्चाई है: कई स्कीमा बदलाव reversible नहीं होते। कॉलम ड्रॉप करने पर डेटा वापस नहीं लाया जा सकता। रोलबैक की योजना आगे की मरम्मत के इर्द‑गिर्द रखें: केवल तभी down माइग्रेशन रखें जब यह सच में सुरक्षित हो, अन्यथा बैकअप और आगे की माइग्रेशन पर भरोसा रखें।
हर माइग्रेशन के साथ एक रिकवरी प्लान जोड़ें: अगर यह बीच में फेल हो तो क्या करना है, और अगर ऐप को रोलबैक करना पड़े तो क्या प्रक्रिया होगी। यदि आप Go बैकएंड रीजनरेट करते हैं (उदा. AppMaster से), तो माइग्रेशन को अपनी रिलीज़ कॉन्ट्रैक्ट का हिस्सा मानें ताकि रीजनरेटेड कोड और स्कीमा सिंक में रहें।
पाइपलाइन तभी पूर्वानुमेय लगती है जब आप जो डिप्लॉय कर रहे हैं वही चीज़ हो जिसे आपने टेस्ट किया। यह पैकेजिंग और कॉन्फ़िग का मामला है। बिल्ड आउटपुट को सील्ड आर्टिफैक्ट मानें और सभी environment भिन्नताएँ उसके बाहर रखें।
पैकेजिंग आमतौर पर दो रास्तों में से एक होती है। Kubernetes पर डिप्लॉय करने के लिए container image डिफ़ॉल्ट है क्योंकि यह OS लेयर पिन करता है और रोलआउट को सुसंगत बनाता है। जब आपको VMs की ज़रुरत हो तो VM बंडल उतना ही भरोसेमंद हो सकता है अगर इसमें compiled binary और रनटाइम के लिए ज़रूरी छोटी फाइलें (CA certs, टेम्पलेट्स, स्टैटिक असेट्स) शामिल हों और आप हर बार उसे एक ही तरह डिप्लॉय करें।
कॉन्फ़िग बाहरी होनी चाहिए, बाइनरी में नहीं। ज़्यादातर सेटिंग्स (पोर्ट्स, DB host, फीचर फ्लैग्स) के लिए environment variables का उपयोग करें। जहाँ मान लंबे या संरचित हों, वहां कॉन्फ़िग फाइल रखें और उसे environment-विशेष बनाएं। अगर आप कोई कॉन्फ़िग सर्विस उपयोग करते हैं तो उसे एक dependency की तरह ट्रीट करें: लॉक्ड परमिशन, ऑडिट लॉग्स और क्लियर फॉलबैक प्लान रखें।
सीक्रेट्स वह रेखा है जिसे आप पार मत करें। वे repo, इमेज या CI लॉग्स में नहीं जाते। स्टार्टअप पर कनेक्शन स्ट्रिंग प्रिंट करने से बचें। सीक्रेट्स को अपने CI के सीक्रेट स्टोर में रखें और डिप्लॉय के समय इंजेक्ट करें।
आर्टिफैक्ट्स को ट्रेसेबल बनाने के लिए हर बिल्ड में पहचान बेक करें: आर्टिफैक्ट को वर्शन और commit hash के साथ टैग करें, बिल्ड मेटाडेटा (वर्शन, commit, build time) info endpoint में डालें, और अपने डिप्लॉयमेंट लॉग में आर्टिफैक्ट टैग रिकॉर्ड करें। इससे एक कमांड या डैशबोर्ड से “कौन चल रहा है” का जवाब आसान हो जाता है।
यदि आप Go बैकएंड जनरेट करते हैं (उदा. AppMaster), तो यह डिसिप्लिन और भी मायने रखती है: रीजनरेशन तभी सुरक्षित है जब आपका आर्टिफैक्ट नामकरण और कॉन्फ़िग नियम हर रिलीज़ को फिर से बनाना आसान करें।
ज़्यादातर डिप्लॉय फेलियर “खराब कोड” की वजह से नहीं होते। वे एन्वायरनमेंट के mismatch से होते हैं: अलग कॉन्फ़िग, मिसिंग सीक्रेट्स, या सर्विस जो शुरू तो होती है पर वास्तव में ready नहीं होती। लक्ष्य सरल है: वही आर्टिफैक्ट हर जगह डिप्लॉय करें, और केवल कॉन्फ़िग बदलें।
Kubernetes पर नियंत्रित रोलआउट का लक्ष्य रखें। rolling updates उपयोग करें ताकि आप पाड्स को धीरे-धीरे बदलें, और readiness और liveness चेक्स जोड़ें ताकि प्लेटफ़ॉर्म जान सके कब ट्रैफ़िक भेजना है और कब अटकी कंटेनर को रीस्टार्ट करना है। Resource requests और limits भी मायने रखते हैं, क्योंकि एक बड़ा CI रनर पर काम करने वाली Go सर्विस छोटे नोड पर OOM‑kill हो सकती है।
इमेज और कॉन्फ़िग को अलग रखें। हर commit पर एक इमेज बनाएं, फिर डिप्लॉय टाइम पर environment-विशेष सेटिंग्स इंजेक्ट करें (ConfigMaps, Secrets या आपका secret manager)। इस तरह staging और production एक ही बिट्स चलाते हैं।
अगर आप VMs पर डिप्लॉय करते हैं, तो systemd आपका “छोटा ऑर्केस्ट्रेटर” हो सकता है। एक यूनिट फाइल बनाएं जिसमें स्पष्ट working directory, environment file और restart policy हो। लॉग्स को predictable बनाएं—stdout/stderr को अपने लॉग कलेक्टर या journald पर भेजें ताकि incidents SSH scavenger hunts में न बदलें।
क्लस्टर के बिना भी आप सुरक्षित रोलआउट कर सकते हैं। एक सादा blue/green सेटअप काम करता है: दो डायरेक्टरी (या दो VMs) रखें, load balancer स्विच करें और पिछला वर्शन तेज़ रोलबैक के लिए तैयार रखें। Canary भी इसी तरह है: नए वर्शन को पहले थोड़ी ट्रैफ़िक भेजें।
एक डिप्लॉय को “किया गया” चिह्नित करने से पहले हर जगह वही पोस्ट‑डिप्लॉय स्मोक चेक चलाएँ:
यदि आप बैकएंड रीजनरेट करते हैं (उदा. AppMaster से), तो यह तरीका स्थिर रहता है: एक बार बिल्ड करें, आर्टिफैक्ट डिप्लॉय करें, और environment कॉन्फिग ad-hoc स्क्रिप्ट्स नहीं बल्कि इच्छित भिन्नताएँ चलाएँ।
ज्यादातर टूटे हुए रिलीज़ “खराब कोड” की बजाए पाइपलाइन के अलग-अलग व्यवहार से होते हैं। अगर आप चाहते हैं कि Go बैकएंड्स के लिए CI/CD शांत और पूर्वानुमेय महसूस हो, तो इन पैटर्न्स से सावधान रहें।
बिना गार्ड्रेल के हर डिप्लॉय पर डेटाबेस माइग्रेशन चलाना क्लासिक है। कोई माइग्रेशन जो टेबल लॉक कर दे, एक व्यस्त सर्विस को डाउन कर सकता है। प्रोडक्शन के लिए अनुमोदन आवश्यक रखें और माइग्रेशन को सुरक्षित तरीके से दोहराने योग्य बनाएं।
latest टैग्स या अनपिन्ड बेस इमेजेस का उपयोग एक और आसान तरीका है जिससे मिस्ट्री फेल्यो होते हैं। Docker इमेज और Go वर्ज़न पिन करें ताकि आपका बिल्ड एन्वायरनमेंट ड्रिफ्ट न करे।
अस्थायी तौर पर विभाजित एक डेटाबेस साझा करना अक्सर स्थायी बन जाता है, और यह टेस्ट डेटा के स्टेजिंग में लीक होने या स्टेजिंग स्क्रिप्ट के प्रोडक्शन को हिट करने का कारण बनता है। एन्वायरनमेंट‑विशेष डेटाबेस (और क्रेडेंशियल्स) रखें।
हेल्थ और readiness चेक्स का अभाव एक डिप्लॉय को "सफल" बना देता है जबकि सर्विस टूट चुकी होती है और ट्रैफ़िक बहुत जल्दी रूट हो जाता है। ऐसे चेक जोड़ें जो वास्तविक व्यवहार से मेल खाते हों: क्या ऐप स्टार्ट कर सकता है, डेटाबेस से कनेक्ट कर सकता है, और रिक्वेस्ट सर्व कर सकता है।
अंत में, सीक्रेट्स, कॉन्फ़िग और एक्सेस के लिए अस्पष्ट ओनरशिप रिलीज़ को अटकने वाली स्थिति बना देती है। किसी को यह जिम्मेदारी लेनी चाहिए कि सीक्रेट्स कैसे बनाए, रोटेट किए और इंजेक्ट किए जाएँ।
एक यथार्थवादी विफलता: टीम ने बदलाव मर्ज किया, पाइपलाइन ने डिप्लॉय किया, और एक ऑटोमैटिक माइग्रेशन पहले चला। यह स्टेजिंग में छोटे डेटा पर पूरा हो गया, पर प्रोडक्शन में टाइमआउट हो गया। पिन्ड इमेजेस, अलग एन्वायरनमेंट और गेटेड माइग्रेशन स्टेप होने पर यह डिप्लॉय सुरक्षित तरीके से रुक जाता।
अगर आप Go बैकएंड्स जनरेट करते हैं (उदा. AppMaster से), तो ये नियम और भी ज़रूरी हो जाते हैं क्योंकि रीजनरेशन कई फाइलों को एक साथ छू सकता है। प्रीडिक्टेबल इनपुट और स्पष्ट गेट्स बड़े बदलावों को जोखिम भरा रिलीज़ बनने से रोकते हैं।
इसे Go बैकएंड्स के लिए CI/CD का एक गट‑चेक समझें। अगर आप हर पॉइंट का स्पष्ट “हां” दे सकते हैं तो रिलीज़ आसान हो जाएंगे।
प्रोडक्शन एक्सेस सीमित और ऑडिटेबल रखें। CI को डिप्लॉय के लिए एक समर्पित सर्विस अकाउंट का उपयोग करना चाहिए, सीक्रेट्स केंद्रीकृत रूप से मैनेज हों, और कोई भी मैन्युअल प्रोडक्शन कार्रवाई स्पष्ट ट्रेल छोड़ दे (कौन, क्या, कब)।
चार सदस्य की एक छोटी ops टीम सप्ताह में एक बार शिप करती है। वे अक्सर अपना Go बैकएंड रीजनरेट करते हैं क्योंकि प्रोडक्ट टीम वर्कफ़्लोज़ संशोधित करती रहती है। उनका लक्ष्य सरल है: रात में आने वाली कम कॉल्स और ऐसे रिलीज़ जो किसी को हैरान न करें।
एक सामान्य शुक्रवार का बदलाव: वे customers में एक नया फ़ील्ड जोड़ते हैं (schema change) और API को अपडेट करते हैं जो इसे लिखता है (code change)। पाइपलाइन इनको एक रिलीज़ मानती है। यह एक आर्टिफैक्ट बनाती है, उसी आर्टिफैक्ट के खिलाफ टेस्ट चलाती है, और तभी माइग्रेशन लागू करके डिप्लॉय करती है। इस तरह डेटाबेस कभी उस कोड से आगे नहीं होता जिसकी उसे उम्मीद है, और कोड कभी उसके मैचिंग स्कीमा के बिना डिप्लॉय नहीं होता।
जब स्कीमा बदलाव शामिल होता है, पाइपलाइन एक सुरक्षा गेट जोड़ती है। यह जाँचती है कि माइग्रेशन additive है (जैसे nullable कॉलम जोड़ना) और जोखिम भरे एक्शंस (जैसे कॉलम ड्रॉप या बड़े टेबल की री‑राइट) को फ्लैग करती है। अगर माइग्रेशन जोखिम भरा है, तो रिलीज़ प्रोडक्शन से पहले रुक जाती है। टीम या तो माइग्रेशन को सुरक्षित बनाती है या एक नियोजित विंडो शेड्यूल करती है।
अगर टेस्ट फेल होते हैं तो कुछ भी आगे नहीं बढ़ता। यह प्री‑प्रोडक्शन एनवायरनमेंट में माइग्रेशन फेल होने पर भी सच्चा है। पाइपलाइन "बस इसे एक बार" करके बदलाव नहीं पास करने की कोशिश नहीं करनी चाहिए।
अधिकतर टीमों के लिए काम करने वाले कुछ सरल अगले कदम:
अगर आप AppMaster से बैकएंड जनरेट कर रहे हैं, तो रीजनरेशन को वही पाइपलाइन स्टेजेज़ में रखें: regenerate, build, test, migrate सुरक्षित एन्वायरनमेंट में, फिर deploy। जनरेट किए गए स्रोत को किसी अन्य स्रोत की तरह ट्रीट करें। हर रिलीज़ को एक टैग्ड वर्शन से पुनर्निर्मित किया जा सके और हर बार एक ही स्टेप्स हों।
अपनी Go वर्शन और बिल्ड वातावरण को पिन करें ताकि एक ही इनपुट हमेशा एक ही बाइनरी या इमेज बनाए। इससे “मेरे मशीन पर चलता है” जैसी समस्याएँ कम होंगी और फेल होना फिर से बनाना आसान होगा।
रेजनरेशन से एन्डपॉइंट, डेटाबेस मॉडल और डिपेंडेंसी बदल सकते हैं, भले ही किसी ने कोड हाथ से न छुआ हो। एक पाइपलाइन उन सभी परिवर्तनों को हर बार एक ही चेक से गुजारती है, जिससे रेजनरेट करना सुरक्षित रहता है।
एक बार बिल्ड करें, फिर वही आर्टिफैक्ट dev, staging और prod में प्रमोट करें। हर environment के लिए अलग से बिल्ड करने पर आप कुछ ऐसा भेज सकते हैं जिसे आपने कभी टेस्ट नहीं किया।
हर PR/commit पर तेज़ गेट्स चलाएँ: फॉर्मेटिंग, बेसिक स्टैटिक चेक, बिल्ड और यूनिट टेस्ट्स (टाइमआउट के साथ)। इसे इतना तेज़ रखें कि लोग इसे बypass न करें, और इतना सख्त रखें कि गलत बदलाव जल्द रोके जाएँ।
एक छोटा इंटीग्रेशन स्टेज रखें जो सर्विस को प्रोडक्शन-जैसी कॉन्फ़िग के साथ बूट करें और रियल डिपेंडेंसीज़ (जैसे PostgreSQL) से बात करे। उद्देश्य यह है कि “कंपाइल तो हो गया लेकिन स्टार्ट नहीं होता” जैसी समस्याएँ पकड़ी जा सकें बिना CI को घंटों का बनाया।
माइग्रेशन को एक नियंत्रित रिलीज़ स्टेप की तरह देखें, न कि हर डिप्लॉय के साथ अपने आप चलने वाला कुछ। स्पष्ट लॉग, सिंगल-रन लॉक और प्रोडक्शन के लिए अनुमोदन आवश्यक रखें—कई स्कीमा परिवर्तन सरल रोलबैक योग्य नहीं होते।
रीडिनेस चेक्स रखें ताकि ट्रैफ़िक केवल उसी पॉड/इंसटेंस पर जाए जो तैयार है। इसके अलावा लिवनेस चेक्स रखें ताकि अटकी हुई कंटेनर रीस्टार्ट हो जाएँ। रीयलिस्टिक resource requests/limits सेट करें ताकि CI पर पास होने वाला सर्विस प्रोडक्शन में OOM ना खा जाए।
एक सादा systemd यूनिट और एक स्थिर रिलीज़ स्क्रिप्ट अक्सर VMs पर शांत डिप्लॉय के लिए काफी होते हैं। संभव हो तो वही आर्टिफैक्ट मॉडल रखें जो कंटेनरों के लिए है, और हर डिप्लॉय पर एक छोटा पोस्ट‑डिप्लॉय स्मोक चेक चलाएँ।
सिक्योर स्टोर में रखें—रिपॉजिटरी, इमेज या CI लॉग्स में नहीं। डिप्लॉय टाइम पर इन्हें इंजेक्ट करें, पढ़ने की सीमाएँ रखें और रोटेशन को नियमित प्रक्रिया बनाएं। स्टार्टअप पर कनेक्शन स्ट्रिंग्स प्रिंट करने से बचें।
रेजनरेशन को उसी पाइपलाइन के अंदर रखें जैसे अन्य बदलाव: regenerate, build, test, package, फिर migrate और deploy गेट्स के साथ। AppMaster से जनरेट कर रहे हैं तो यह तरीका आपको तेज़ी से और भरोसेमंद तरीके से रिलीज़ करने में मदद करेगा।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


