उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
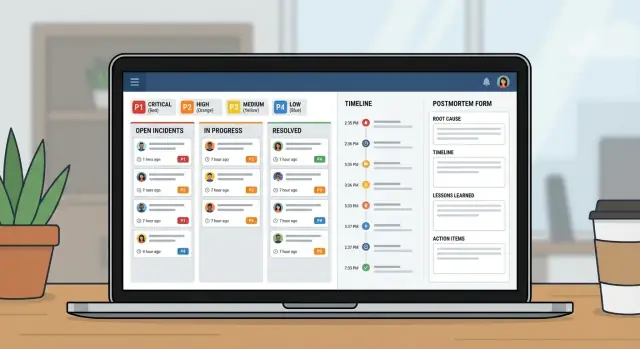
गंभीरता वर्कफ़्लोज़, स्पष्ट जिम्मेदारी, टाइमलाइन और पोस्टमॉर्टम को एक ही आंतरिक टूल में शामिल करके IT टीमों के लिए एक इन्सिडेंट मैनेजमेंट ऐप प्लान और बनाएं।
जब आउटेज आता है, तो ज्यादातर टीमें जो कुछ खुला मिलता है वहीं पकड़ लेती हैं: एक चैट थ्रेड, ईमेल चेन, या शायद कोई स्प्रेडशीट जिसे कोई मौके पर अपडेट करता है। दबाव में, वही सेटअप हर बार एक ही तरह टूटता है: स्वामित्व धुंधला हो जाता है, टाइमस्टैम्प गायब हो जाते हैं, और निर्णय स्क्रोल में खो जाते हैं।
एक सरल इन्सिडेंट मैनेजमेंट ऐप बुनियादी चीजें ठीक कर देता है। यह आपको एक जगह देता है जहां घटना रहती है, एक स्पष्ट मालिक के साथ, एक ऐसी गंभीरता जो सब सहमत हों, और क्या हुआ और कब हुआ इसका टाइमलाइन। यह एकल रिकॉर्ड मायने रखता है क्योंकि हर इन्सिडेंट में वही सवाल उभरते हैं: कौन नेतृत्व कर रहा है? यह कब शुरू हुआ? वर्तमान स्थिति क्या है? पहले क्या कोशिश की गई?
उस साझा रिकॉर्ड के बिना, हैंडऑफ़ समय बर्बाद करते हैं। सपोर्ट ग्राहकों को कुछ कहता है जबकि इंजीनियरिंग कुछ और कर रही होती है। मैनेजर अपडेट माँगते हैं जो रिस्पॉन्डरों को फिक्स से हटाते हैं। बाद में, कोई भरोसे के साथ टाइमलाइन पुनर्निर्माण नहीं कर पाता, तो पोस्टमॉर्टम अनुमान पर बन जाता है।
लक्ष्य यह नहीं है कि आपका मॉनिटरिंग, चैट या टिकटिंग बदल दिया जाए। अलर्ट अभी भी अन्य स्थानों से आ सकते हैं। उद्देश्य निर्णय-ट्रेल को कैप्चर करना और लोगों को समान पृष्ठ पर रखना है।
IT ऑपरेशन्स और ऑन-कॉल इंजीनियर इसे समन्वय के लिए उपयोग करते हैं। सपोर्ट इसका उपयोग तेज़ और सही अपडेट देने के लिए करता है। मैनेजर बिना रिस्पॉन्डरों को बाधित किए प्रगति देख पाते हैं।
सुबह 9:12 पर, मॉनिटरिंग ग्राहक पोर्टल पर 500 त्रुटियों में spike दिखाती है। एक सपोर्ट एजेंट भी रिपोर्ट करता है, “ज्यादातर उपयोगकर्ताओं के लिए लॉगिन फेल हो रहा है।” ऑन-कॉल IT लीड इन्सिडेंट ऐप में एक P1 इन्सिडेंट खोलता है और पहली अलर्ट के साथ सपोर्ट का स्क्रीनशॉट अटैच करता है।
P1 के साथ व्यवहार तेजी से बदलता है। इन्सिडेंट मालिक बैकएंड ओwner, डेटाबेस ओwner और एक सपोर्ट लियाज़न को बुलाता है। गैर-आवश्यक कार्य रोके जाते हैं। नियोजित डिप्लॉयमेंट्स बंद कर दिए जाते हैं। टीम एक अपडेट कैडेंस पर सहमत होती है (उदाहरण के लिए हर 15 मिनट)। एक साझा कॉल शुरू होती है, पर इन्सिडेंट रिकॉर्ड सत्य का स्रोत बना रहता है।
9:18 तक किसी ने पूछा, “क्या बदला?” टाइमलाइन में 8:57 का एक डिप्लॉय दिखता है, पर यह नहीं बताता कि क्या डिप्लॉय किया गया था। बैकएंड ओwner फिर भी रोलबैक कर देता है। त्रुटियाँ घटती हैं, फिर लौट आती हैं। अब टीम डेटाबेस पर शक करती है।
अधिकतर देरी कुछ पूर्वानुमेय जगहों पर दिखती है: अस्पष्ट हैंडऑफ़ (“मुझे लगा तुम देख रहे थे”), गुम संदर्भ (हालिया परिवर्तन, ज्ञात जोखिम, वर्तमान मालिक), और चैट, टिकट, और ईमेल में बिखरे अपडेट।
9:41 AM पर डेटाबेस ओwner एक runaway query पाता है जो शेड्यूल्ड जॉब ने शुरू की थी। वे जॉब को अक्षम करते हैं, प्रभावित सर्विस को रीस्टार्ट करते हैं, और रिकवरी की पुष्टि करते हैं। निगरानी के लिए गंभीरता P2 में डाउनग्रेड की जाती है।
अच्छा क्लोजर सिर्फ “फिर काम कर रहा है” नहीं है। यह एक साफ रिकॉर्ड होता है: मिनट-दर-मिनट टाइमलाइन, अंतिम रूट कारण, किसने कौन सा निर्णय लिया, क्या रोका गया था, और फॉलो-अप कार्य जिनके मालिक और नियत तिथियाँ हों। इसी तरह तनावपूर्ण P1 सीख में बदल जाता है बजाए बार-बार दर्द के।
एक अच्छा इन्सिडेंट टूल ज़्यादातर एक अच्छा डेटा मॉडल है। अगर रिकॉर्ड अस्पष्ट होंगे, लोग बहस करेंगे कि इन्सिडेंट क्या है, कब शुरू हुआ, और क्या खुला है।
कोर एंटिटीज़ को ऐसे रखें जैसे IT टीमें पहले से ही बोलती हैं:
भविष्य में भ्रम से बचने के लिए, Incident को कुछ संरचित फ़ील्ड दें जो हमेशा भरे जाएँ। फ्री टेक्स्ट मदद करता है, पर यह अकेला सत्य स्त्रोत नहीं होना चाहिए। व्यावहारिक न्यूनतम है: एक स्पष्ट शीर्षक, प्रभाव (उपयोगकर्ता क्या अनुभव कर रहे हैं), प्रभावित सेवाएँ, प्रारंभ समय, वर्तमान स्थिति, और गंभीरता।
रिलेशनशिप्स अतिरिक्त फ़ील्ड्स से ज़्यादा मायने रखते हैं। एक इन्सिडेंट में कई अपडेट्स और कई टास्क होने चाहिए, साथ ही सेवाओं के साथ many-to-many लिंक होना चाहिए (क्योंकि आउटेज अक्सर कई सिस्टम को प्रभावित करते हैं)। एक पोस्टमॉर्टम का संबंध एक-से-एक होना चाहिए, ताकि एक ही अंतिम कहानी रहे।
उदाहरण: “Checkout errors” इन्सिडेंट Services “Payments API” और “PostgreSQL” से लिंक है, हर 15 मिनट पर अपडेट्स हैं, और टास्क जैसे “Roll back deploy” और “Add retry guard” हैं। बाद में पोस्टमॉर्टम रूट कारण कैप्चर करता है और लॉन्ग-टर्म टास्क बनाता है।
तनाव में लोग साधारण लेबल चाहते हैं जिनका हर किसी को एक ही मतलब निकले। P1 से P4 को साधारण भाषा में परिभाषित करें और परिभाषा कोSeverity फ़ील्ड के पास दिखाएँ।
रिस्पांस टारगेट्स वचन की तरह पढ़ने चाहिए। एक सरल बेसलाइन (अपनी वास्तविकता के अनुसार समायोजित करें):
| Severity | First response (ack) | First update | Update frequency |
|---|---|---|---|
| P1 | 5 min | 15 min | every 30 min |
| P2 | 15 min | 30 min | every 60 min |
| P3 | 4 hours | 1 business day | daily |
| P4 | 2 business days | 1 week | weekly |
एस्केलेशन नियमों को यांत्रिक रखें। अगर P2 अपनी अपडेट कैडेंस मिस कर देता है या प्रभाव बढ़ता है, सिस्टम को गंभीरता की समीक्षा का संकेत देना चाहिए। थ्रैश से बचने के लिए सीमित करें कि कौन गंभीरता बदल सकता है (अक्सर इन्सिडेंट मालिक या इन्सिडेंट कमांडर), पर किसी को भी कमेंट में समीक्षा का अनुरोध करने दें।
एक त्वरित इम्पैक्ट मैट्रिक्स टीमों को तेज़ी सेSeverity चुनने में मदद करता है। इसे कुछ आवश्यक फ़ील्ड्स के रूप में कैप्चर करें: प्रभावित उपयोगकर्ता, राजस्व जोखिम, सुरक्षा/कॉनप्लायंस, और क्या वर्कअराउंड मौजूद है।
इन्सिडेंट के दौरान, लोगों को और विकल्पों की ज़रूरत नहीं होती। उन्हें कुछ सीमित अवस्थाएँ चाहिए जो अगले कदम को स्पष्ट कर दें।
अपने उन कदमों से शुरू करें जिन्हें आप अच्छे दिन पर पहले ही फॉलो करते हैं, फिर सूची को छोटा रखें। अगर आपके पास 6 या 7 से अधिक अवस्थाएँ हैं, टीमें शब्दावली पर बहस करेंगी बजाय समस्या ठीक करने के।
एक व्यावहारिक सेट:
हर स्टेट के लिए स्पष्ट एंट्री और एग्ज़िट नियम चाहिए। उदाहरण के लिए:
ट्रांज़िशन उन फ़ील्ड्स को लागू करने के लिए इस्तेमाल करें जिन्हें लोग भूल जाते हैं। एक सामान्य नियम: आप इन्सिडेंट बंद नहीं कर सकते बिना एक छोटा रूट कारण सार और कम से कम एक फॉलो-अप आइटम के। अगर "RCA: TBD" को अनुमति दी जाती है, तो वह अक्सर वैसा ही रहता है।
इन्सिडेंट पेज तीन सवालों का जवाब एक झलक में दे: किसका स्वामित्व है, अगला कदम क्या है, और आखिरी अपडेट कब पोस्ट हुआ।
जब इन्सिडेंट शोरगुल वाला हो, सबसे तेज़ तरीका समय खोने का अस्पष्ट स्वामित्व है। आपका ऐप एक व्यक्ति को स्पष्ट रूप से जिम्मेदार बनाना चाहिए, जबकि दूसरों के लिए मदद करना आसान होना चाहिए।
एक साधारण पैटर्न जो टिकता है:
असाइनमेंट स्पष्ट और ऑडिटेबल होना चाहिए। ट्रैक करें कि किसने मालिक सेट किया, किसने स्वीकार किया, और उसके बाद हर बदलाव। “स्वीकार किया” मायने रखता है, क्योंकि किसी को असाइन करना जो सो रहा है या ऑफ़लाइन है वास्तविक स्वामित्व नहीं है।
ऑन-कॉल बनाम टीम-आधारित असाइनमेंट आमतौर परSeverity पर निर्भर करता है। P1/P2 के लिए, डिफ़ॉल्ट ऑन-कॉल रोटेशन रखें ताकि हमेशा एक नामित मालिक हो। कम गंभीरता के लिए टीम-आधारित असाइनमेंट काम कर सकता है, पर एकल प्राथमिक मालिक की आवश्यकता एक छोटे समय में रखें।
अपनी मानव प्रक्रिया में छुट्टियाँ और आउटेज के लिए योजना बनाएं, सिर्फ सिस्टम में नहीं। अगर असाइन किए गए व्यक्ति को अनुपलब्ध चिह्नित किया गया है, तो सेकेंडरी ऑन-कॉल या टीम लीड को रूट करें। इसे स्वचालित पर रखें, पर दृश्य रखें ताकि तेज़ी से ठीक किया जा सके।
एस्केलेशन को गंभीरता और सन्नाटा दोनों पर ट्रिगर करना चाहिए। एक उपयोगी शुरुआती बिंदु:
एक अच्छी टाइमलाइन साझा स्मृति है। इन्सिडेंट के दौरान संदर्भ तेज़ी से गायब होते हैं। अगर आप सही पलों को एक जगह कैप्चर करें, हैंडऑफ़ आसान हो जाते हैं और पोस्टमॉर्टम अधिकांशतः तब तक लिखी हुई होती है जब कोई दस्तावेज़ खोलता है।
टाइमलाइन के प्रति राय रखें। इसे चैट लॉग मत बनाइए। अधिकांश टीमें कुछ एंट्रीज़ पर भरोसा करती हैं: डिटेक्शन, एक्सनोलॉजमेंट, प्रमुख मिटीगेशन स्टेप्स, रिस्टोर, और क्लोजर।
हर एंट्री में टाइमस्टैम्प, लेखक और एक संक्षिप्त स्पष्ट विवरण होना चाहिए। देर से जुड़ने वाला व्यक्ति पाँच एंट्रीयाँ पढ़कर समझ जाना चाहिए कि क्या हो रहा है।
विभिन्न अपडेट विभिन्न दर्शकों के लिए होते हैं। जब एंट्रीज़ का एक प्रकार हो, जैसे internal note (कच्चे विवरण), customer-facing update (सुरक्षित शब्दावली), decision (क्यों विकल्प A चुना गया), और handoff (अगले व्यक्ति को क्या जानना चाहिए), तो मदद मिलती है।
रिमाइंडर्सSeverity के अनुसार होने चाहिए, व्यक्तिगत पसंद के अनुसार नहीं। अगर टाइमर हिट कर दे, पहले वर्तमान मालिक को पिंग करें, फिर बार-बार मिस होने पर एस्केलेट करें।
नोटिफिकेशन लक्षित और पूर्वानुमान योग्य होने चाहिए। एक छोटा नियम सेट अक्सर पर्याप्त होता है: निर्माण पर,Severity बदलने पर, रिस्टोर पर, और ओवरड्यू अपडेट पर नोटिफाई करें। पूरी कंपनी को हर बदलाव के लिए नोटिफाई करने से बचें।
पोस्टमॉर्टम के दो काम होने चाहिए: सरल भाषा में बताना कि क्या हुआ, और अगली बार वही विफलता कम होने की कोशिश करना।
राइट-अप को छोटा रखें, और आउटपुट को क्रियाओं में मजबूर करें। एक व्यावहारिक संरचना: सारांश, ग्राहक प्रभाव, रूट कारण, लागू किए गए फिक्स, और फॉलो-अप्स।
फॉलो-अप्स ही मूल बिंदु हैं। उन्हें अंत में पैराग्राफ के रूप में न छोड़ें। हर फॉलो-अप को एक ट्रैक किए गए टास्क में बदल दें जिसका एक मालिक और ड्यू डेट हो, भले ही ड्यू डेट “अगला स्प्रिंट” हो। यही फर्क है “हमें मॉनिटरिंग बेहतर करनी चाहिए” और “Alex शुक्रवार तक DB कनेक्शन सैचुरेशन अलर्ट जोड़ता है” के बीच।
टैग पोस्टमॉर्टम को बाद में उपयोगी बनाते हैं। हर इन्सिडेंट में 1 से 3 थीम जोड़ें (monitoring gap, deployment, capacity, process)। एक महीने बाद आप बुनियादी सवालों के जवाब दे पाएँगे, जैसे ज्यादातर P1 रिलीज़ से आते हैं या अलर्ट्स के अभाव से।
सबूत अटैच करना आसान होना चाहिए, पर अनिवार्य नहीं। स्क्रीनशॉट, लॉग स्निपेट, और बाहरी सिस्टम संदर्भ (टिकट ID, चैट थ्रेड, vendor केस नंबर) के लिए वैकल्पिक फ़ील्ड रखें। इसे हल्का रखें ताकि लोग वास्तव में भरें।
इसे एक छोटे प्रोडक्ट की तरह ट्रीट करें, स्प्रेडशीट में एक्स्ट्रा कॉलम की तरह नहीं। एक अच्छा इन्सिडेंट ऐप वास्तव में तीन व्यूज़ है: अभी क्या हो रहा है, अगला क्या करना है, और बाद में क्या सीखना है।
लोग दबाव में खोलेंगे ऐसे स्क्रीन स्केच करके शुरू करें:
डेटा मॉडल और अनुमतियाँ साथ में बनाएं। अगर हर कोई सब कुछ एडिट कर सकता है, तो हिस्ट्री गड़बड़ हो जाएगी। एक सामान्य दृष्टिकोण है: IT के लिए व्यापक व्यू एक्सेस, स्टेट/सेवेरिटी चेंज नियंत्रित, रिस्पॉन्डर अपडेट जोड़ सकते हैं, और पोस्टमॉर्टम अप्रूवल के लिए واضح मालिक।
फिर वर्कफ़्लो नियम जोड़ें जो आधे भरे इन्सिडेंट्स को रोकें। आवश्यक फ़ील्ड्स स्टेट पर निर्भर होने चाहिए। आप “New” की अनुमति दे सकते हैं सिर्फ शीर्षक और रिपोर्टर के साथ, पर “Mitigating” को प्रभाव सारांश आवश्यक करना, और “Resolved” को रूट कारण सार + कम से कम एक फॉलो-अप टास्क आवश्यक करना बेहतर है।
अंत में, 2 से 3 पिछले इन्सिडेंट्स को फिर से चलाकर टेस्ट करें। एक व्यक्ति इन्सिडेंट कमांडर बने और एक रिस्पॉन्डर बने। आप जल्दी देखेंगे कौन से स्टेट्स अस्पष्ट हैं, कौन से फ़ील्ड लोग छोड़ते हैं, और कहाँ बेहतर डिफॉल्ट चाहिए।
अधिकांश इन्सिडेंट सिस्टम साधारण कारणों से फेल होते हैं: लोग तनाव में नियम याद नहीं रख पाते, और ऐप वह तथ्य नहीं पकड़ता जो बाद में चाहिए।
अगर आपके पास छह गंभीरता स्तर और दस स्टेट्स हैं, लोग अनुमान लगाएंगे।Severity को 3-4 रखें और अवस्थाएँ अगले कदम पर केंद्रित रखें।
जब हर कोई “देख रहा” होता है, कोई आगे नहीं बढ़ता। इन्सिडेंट आगे बढ़ने से पहले एक नामित मालिक अनिवार्य करें, और हैंडऑफ़ को स्पष्ट बनाएं।
अगर “क्या कब हुआ” चैट हिस्ट्री पर निर्भर करता है, पोस्टमॉर्टम तर्क बन जाता है। ओपन, स्वीकार, मिटीगेट, और रेज़ॉल्व टाइमस्टैम्प ऑटो-कैप्चर करें, और टाइमलाइन एंट्रीज़ को छोटा रखें।
साथ ही अस्पष्ट रूट कारण नोट्स जैसे “नेटवर्क इश्यू” से बचें। एक स्पष्ट रूट कारण वाक्य और कम से कम एक ठोस अगला कदम अनिवार्य करें।
पूरे IT संगठन में रोल आउट करने से पहले, बेसिक्स को स्ट्रेस टेस्ट करें। अगर लोग पहले दो मिनट में सही बटन नहीं ढूँढ पाते, तो वे फिर चैट थ्रेड्स और स्प्रेडशीट्स पर लौट आएँगे।
लॉन्च चेक्स पर ध्यान दें: रोल्स और परमिशन, स्पष्टSeverity परिभाषाएँ, प्रवर्तन योग्य स्वामित्व, रिमाइंडर नियम, और रिस्पॉन्स टारगेट मिस होने पर एस्केलेशन पाथ।
एक टीम और कुछ सेवाओं के साथ पायलट करें जो अक्सर अलर्ट जेनरेट करती हैं। इसे दो हफ्ते चलाएँ, फिर वास्तविक इन्सिडेंट्स के आधार पर समायोजित करें।
यदि आप इसे अलग-अलग स्प्रेडशीट्स और अलग ऐप्स को जोड़कर नहीं बल्कि एक ही आंतरिक टूल के रूप में बनाना चाहते हैं, तो AppMaster (appmaster.io) एक विकल्प है। यह आपको एक ही जगह डेटा मॉडल, वर्कफ़्लो नियम, और वेब/मोबाइल इंटरफेस बनाने देता है, जो इन्सिडेंट क्यू, इन्सिडेंट पेज, और पोस्टमॉर्टम ट्रैकिंग के साथ अच्छा मेल खाता है।
यह बिखरी हुई अपडेट्स को एक साझा रिकॉर्ड से बदल देता है जो जल्दी से मूल बातों का जवाब देता है: किसका स्वामित्व है, उपयोगकर्ता क्या देख रहे हैं, क्या-क्या कोशिश की गई, और आगे क्या होगा। इससे हैंडऑफ़, विरोधाभासी संदेश और “क्या सार दे सकते हो?” जैसे व्यवधान कम होते हैं।
जैसे ही आपको वास्तविक ग्राहक या व्यापारिक प्रभाव होने का शक हो, इन्सिडेंट खोल दें — भले ही रूट कारण अभी स्पष्ट न हो। आप एक ड्राफ्ट शीर्षक और “प्रभाव अज्ञात” के साथ खोलकर बाद मेंSeverity और स्कोप पक्के कर सकते हैं।
न्यूनतम फ़ील्ड छोटे और संरचित रखें: स्पष्ट शीर्षक, प्रभाव सारांश, प्रभावित सेवा(यां), आरम्भ समय, वर्तमान स्थिति, गंभीरता, और एकल जिम्मेदार। स्थिति बदलने पर अपडेट और टास्क जोड़ें, पर मुख्य जानकारी के लिए सिर्फ फ्री टेक्स्ट पर निर्भर न रहें।
3 से 4 लेवल रखें और सरल परिभाषाएँ दें ताकि बहस न हो। डिफ़ॉल्ट के रूप में: P1 - कोर आउटेज या डेटा लॉस का जोखिम, P2 - बड़े फीचर पर असर लेकिन वर्कअराउंड संभव, P3 - छोटा प्रभाव, P4 - कॉस्मेटिक/माइनर।
उन लक्ष्यों को ट्रैक करें जो वचन जैसी लगती हों: स्वीकार करने का समय, पहली अपडेट का समय, और अपडेट आवृत्ति। फिर जब कैडेंस मिस हो तो रिमाइंडर और एस्केलेशन ट्रिगर करें — क्योंकि “सन्नाटा” अक्सर ही असल विफलता होती है।
लगभग छह स्टेटस का लक्ष्य रखें: New, Acknowledged, Investigating, Mitigating, Monitoring, और Resolved. हर स्टेट का अगला कदम स्पष्ट होना चाहिए और ट्रांज़िशन उन फ़ील्ड्स को जबरदस्त करें जिन्हें लोग तनाव में भूल जाते हैं — जैसे Acknowledged पर मालिक होना अनिवार्य करना या बंद करने से पहले रूट कारण चाहिए होना।
एक प्राथमिक मालिक सुनिश्चित करें जो रिस्पॉन्स का नेतृत्व करे और अपडेट पोस्ट करे। स्वीकार्यता (accepted) को रिकॉर्ड करें ताकि आप किसी ऐसे व्यक्ति को असाइन न कर दें जो ऑफ़लाइन या सो रहा हो। हैंडऑफ़ को भी लिखित इवेंट बनाएं।
टाइमलाइन में केवल वे क्षण कैप्चर करें जो मायने रखते हैं: डिटेक्शन, एक्सनोलॉड्जमेंट, प्रमुख फैसले, मिटीगेशन स्टेप्स, रिस्टोर और क्लोजर — हर एक में टाइमस्टैम्प और लेखक। इसे चैट ट्रांसक्रिप्ट न बनाएं, बल्कि साझा मेमोरी बनाएं ताकि बाद में कोई भी जल्दी समझ सके।
पोस्टमॉर्टम को छोटा और एक्शन-फोकस्ड रखें: क्या हुआ, ग्राहक पर प्रभाव, रूट कारण, मिटीगेशन के दौरान क्या बदला गया, और फॉलो-अप आइटम्स जिनके मालिक और ड्यू डेट हों। रिपोर्ट उपयोगी है, पर असली बदलाव ट्रैक किए गए टास्क से आते हैं।
हाँ — अगर आप घटनाओं, अपडेट्स, टास्क, सेवाओं और पोस्टमॉर्टम को डेटा के रूप में मॉडल करें और ऐप में वर्कफ़्लो नियम लागू करें। AppMaster (appmaster.io) जैसी चीज़ों से आप उसी जगह डेटा मॉडल, वेब/मोबाइल स्क्रीन और स्टेट-आधारित वेलिडेशन बना सकते हैं, ताकि प्रक्रिया फिर स्प्रेडशीट्स पर न लौटे।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


