उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
एडमिन पैनलों के लिए इंडेक्सिंग: वास्तविक क्वेरी पैटर्न के आधार पर उन फ़िल्टरों को अनुकूलित करें जिन पर उपयोगकर्ता सबसे ज़्यादा क्लिक करते हैं — status, assignee, date ranges, और text search।
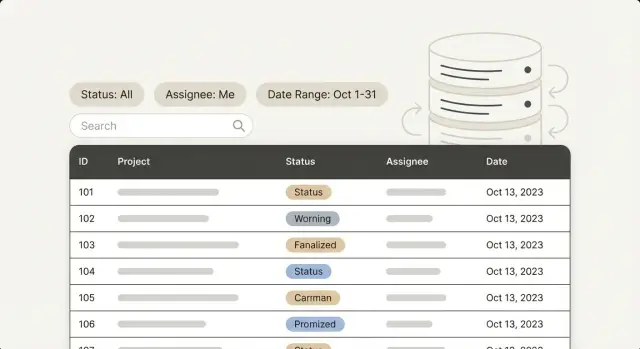
एडमिन पैनल अक्सर शुरुआत में तेज़ लगते हैं। आप एक लिस्ट खोलते हैं, स्क्रॉल करते हैं, एक रिकॉर्ड पर क्लिक करते हैं और आगे बढ़ जाते हैं। असल धीमापन तब दिखता है जब लोग उसी तरह फ़िल्टर करते हैं जैसे वे रोज़ काम करते हैं: "Only open tickets", "Assigned to Maya", "Created last week", "Order ID contains 1047"। हर क्लिक पर इंतज़ार होता है, और लिस्ट चिपचिपी लगने लगती है।
एक ही तालिका एक फ़िल्टर के लिए तेज़ हो सकती है और दूसरे के लिए दर्दनाक रूप से धीमी। एक status फ़िल्टर शायद कुछ ही पंक्तियों को छुए और जल्दी लौट आए। एक "created between two dates" फ़िल्टर बड़ा रेंज पढ़ने पर मजबूर कर सकता है। एक assignee फ़िल्टर अकेले ठीक चल सकता है, लेकिन status के साथ और sorting जोड़ने पर धीमा पड़ सकता है।
इंडेक्स वह शॉर्टकट है जिसे डेटाबेस मिलान करने वाली पंक्तियों को पूरे टेबल पढ़े बिना ढूँढने के लिए उपयोग करता है। लेकिन इंडेक्स मुफ्त नहीं होते। वे जगह लेते हैं, और inserts/updates को थोड़ा धीमा कर देते हैं। बहुत अधिक इंडेक्स जोड़ने से लिखने की गति गिर सकती है और फिर भी असली बॉटलनेक सही नहीं होता।
सब कुछ इंडेक्स करने की बजाय, उन फ़िल्टरों को प्राथमिकता दें जो:
यह लेख जानबूझकर संकुचित है। एडमिन लिस्ट्स में पहला प्रदर्शन-सम्बंधी शिकायतें अक्सर उन्हीं चार फ़िल्टर प्रकारों से आती हैं: status, assignee, date ranges, और text fields। जब आप समझ जाते हैं कि ये अलग-अलग कैसे व्यवहार करते हैं, तो अगले कदम साफ़ हो जाते हैं: वास्तविक क्वेरी पैटर्न देखें, उन पर मैच करने वाला सबसे छोटा इंडेक्स जोड़ें, और पुष्टि करें कि आपने स्लो पाथ सुधारा बिना नए समस्याएँ बनाए।
एडमिन पैनल शायद ही कभी किसी एक बड़े रिपोर्ट की वजह से धीमे होते हैं। वे धीमे होते हैं क्योंकि कुछ स्क्रीन दिन भर उपयोग होती हैं, और वे स्क्रीन बार-बार कई छोटी क्वेरियाँ चलाती हैं।
Ops टीमें आमतौर पर कुछ वर्क क्यूज़ में रहती हैं: tickets, orders, users, approvals, internal requests। इन पेजों पर फ़िल्टर रिपीट होते हैं:
डेटाबेस का काम इरादे पर निर्भर करता है:
एडमिन पैनल अक्सर फ़िल्टर संयोजित करते हैं: "Open + Unassigned", "Pending + Assigned to me", या "Completed in the last 30 days"। इंडेक्स तब सबसे अच्छा काम करते हैं जब वे उन वास्तविक क्वेरी शेप्स से मिलते हैं, न कि केवल कॉलम की सूची से।
यदि आप AppMaster में एडमिन टूल बनाते हैं, तो ये पैटर्न अक्सर सबसे-उपयोग किए जाने वाले लिस्ट स्क्रीन और उनके डिफ़ॉल्ट फ़िल्टर देखकर ही दिख जाते हैं। इससे उस चीज़ पर इंडेक्स करना आसान हो जाता है जो वास्तव में दैनिक काम चलाती है, न कि सिर्फ़ कागज़ पर अच्छा दिखने वाली चीज़।
इंडेक्सिंग को ट्रियाज की तरह ट्रीट करें। हर उस कॉलम को इंडेक्स करने से शुरू न करें जो फ़िल्टर ड्रॉपडाउन में दिखाई देता है। उन कुछ क्वेरियों से शुरू करें जो लगातार चलती हैं और लोगों को सबसे ज्यादा परेशान करती हैं।
ऐसा फ़िल्टर ऑप्टिमाइज़ करना बेकार है जो कोई छुआ तक नहीं। वास्तविक हॉट पाथ्स खोजने के लिए संकेतों को मिलाएँ:
कई टीमों में वह डिफ़ॉल्ट दृश्य कुछ ऐसा होता है जैसे "Open tickets" या "New orders"। यह हर बार चलता है जब कोई रिफ्रेश करता है, टैब बदलता है, या रिप्लाई के बाद वापस आता है।
इंडेक्स जोड़ने से पहले, अपनी सामान्य क्वेरियों को उनके व्यवहार के अनुसार समूहित करें। अधिकतर एडमिन लिस्ट क्वेरियाँ कुछ बकेट में आती हैं:
status = 'open', assignee_id = 42created_at between two datesORDER BY created_at DESC और पेज 2 लानाहर टॉप स्क्रीन के लिए WHERE, ORDER BY, और pagination सहित शेप लिखें। दो क्वेरियाँ जो UI में समान दिखती हैं, डेटाबेस में बहुत अलग व्यवहार कर सकती हैं।
एक प्राथमिक लक्ष्य से शुरू करें: वह डिफ़ॉल्ट लिस्ट क्वेरी जो पहले लोड होती है। फिर 2 या 3 और high-frequency क्वेरियाँ चुनें। आमतौर पर यहीं से सबसे बड़ा अंतर आता है बिना डेटाबेस को इंडेक्स म्यूज़ियम बनाने के।
उदाहरण: एक सपोर्ट टीम Tickets लिस्ट खोलती है जो status = 'open' से फ़िल्टर्ड है, सबसे नए अनुसार सॉर्ट की जाती है, और वैकल्पिक assignee और date range हो सकते हैं। पहले उसी संयोजन को ऑप्टिमाइज़ करें। एक बार वह तेज़ हो जाए, अगला स्क्रीन उपयोग के आधार पर चुनें।
Status उन पहले फ़िल्टरों में से एक है जो अक्सर जोड़े जाते हैं, और इसे ऐसे तरह इंडेक्स करना आसान है जो मदद न भी करे।
अधिकांश status फील्ड्स low-cardinality होते हैं: सिर्फ कुछ मान (open, pending, closed)। इंडेक्स तब सबसे ज़्यादा मदद करता है जब यह परिणामों को टेबल के एक छोटे हिस्से तक सीमित कर दे। यदि 80% से 95% पंक्तियाँ एक ही status साझा करती हैं, तो सिर्फ़ status पर इंडेक्स अक्सर ज्यादा फर्क नहीं करता। डेटाबेस को फिर भी बड़ी मात्रा की पंक्तियाँ पढ़नी पड़ सकती हैं, और इंडेक्स ओवरहेड जोड़ता है।
आप आमतौर पर तब लाभ महसूस करते हैं जब:
एक सामान्य पैटर्न है "मुझे open आइटम दिखाओ, newest पहले." उस स्थिति में, फ़िल्टर और सॉर्ट दोनों को मिलाकर इंडेक्स बनाना अक्सर सिर्फ़ status अकेले इंडेक्स से बेहतर होता है।
वे संयोजन जो पहली बार लाभ देते हैं:
status + updated_at (status से फ़िल्टर, हालिया बदलावों के अनुसार सॉर्ट)status + assignee_id (वर्क क्यू व्यूज़)status + updated_at + assignee_id (सिर्फ़ तभी जब वही व्यू भारी रूप से उपयोग होता हो)Partial indexes तब एक अच्छा मध्य मार्ग होते हैं जब एक status बहुमत में हो। यदि "open" मुख्य व्यू है, तो केवल open पंक्तियों को इंडेक्स करें। इंडेक्स छोटा रहता है, और लिखने की लागत कम रहती है。
-- PostgreSQL example: index only open rows, optimized for newest-first lists
CREATE INDEX CONCURRENTLY tickets_open_updated_idx
ON tickets (updated_at DESC)
WHERE status = 'open';
एक व्यावहारिक परीक्षण: धीमी एडमिन क्वेरी को status फ़िल्टर के साथ और बिना चलाकर देखें। यदि यह किसी भी तरह से धीमा है, तो केवल status-ऑनली इंडेक्स इसे नहीं बचाएगा। सॉर्ट और दूसरा वह फ़िल्टर जिनसे सूची वास्तविक में छोटी होती है, उन पर फोकस करें।
अधिकतर एडमिन पैनलों में assignee रिकॉर्ड पर एक user ID के रूप में स्टोर होता है: एक foreign key जैसे assignee_id। यह एक क्लासिक equality फ़िल्टर है, और साधारण इंडेक्स से अक्सर तुरंत लाभ मिलता है।
Assignee अक्सर अन्य फ़िल्टरों के साथ भी दिखता है क्योंकि यह काम करने के तरीके से मिलता है। एक सपोर्ट लीड "Assigned to Alex" फ़िल्टर कर सकता है और फिर "Open" तक सीमित कर सकता है ताकि देख सके क्या अभी भी ध्यान चाहिए। यदि यह व्यू धीमा है, तो अक्सर single-column से ज़्यादा चाहिए होता है।
एक अच्छा आरम्भिक कदम एक कंपोजिट इंडेक्स है जो सामान्य फ़िल्टर कॉम्बो से मेल खाता है:
(assignee_id, status) "my open items" के लिए(assignee_id, status, updated_at) यदि लिस्ट हाल की गतिविधि के अनुसार सॉर्ट भी होती हैकंपोजिट इंडेक्स में क्रम मायने रखता है। equality फ़िल्टर को पहले रखें (अक्सर assignee_id, फिर status), और सॉर्ट या range कॉलम को आख़िर में रखें (updated_at)। इससे डेटाबेस इसे प्रभावी रूप से उपयोग कर पाता है।
Unassigned आइटम एक सामान्य गोटचा हैं। कई सिस्टम "unassigned" को NULL के रूप में दर्शाते हैं, और मैनेजर्स अक्सर इसके लिए फ़िल्टर करते हैं। आपके डेटाबेस और क्वेरी शेप के आधार पर, NULL मान प्लान को बदल सकते हैं ताकि एक इंडेक्स जो assigned आइटम के लिए बढ़िया काम करे, unassigned के लिए बेकार लगने लगे।
यदि unassigned वर्कफ़्लो महत्वपूर्ण है, तो एक स्पष्ट दृष्टिकोण चुनें और टेस्ट करें:
assignee_id nullable रखें, लेकिन सुनिश्चित करें कि WHERE assignee_id IS NULL विशेष रूप से टेस्ट और इंडेक्स किया गया हो जब ज़रूरत हो।यदि आप AppMaster में एडमिन पैनल बना रहे हैं, तो यह मदद करता है कि आप अपनी टीम सबसे ज़्यादा कौन से फ़िल्टर और सॉर्ट्स उपयोग करती है, उन्हें लॉग करें और उन पैटर्न को छोटे, चुने हुए इंडेक्स के साथ मिरर करें बजाय हर उपलब्ध फ़ील्ड को इंडेक्स करने के।
तिथि फ़िल्टर अक्सर "last 7 days" या "last 30 days" जैसे शॉर्टकट के रूप में और एक कस्टम पिकर के साथ दिखते हैं। ये सरल दिखते हैं, लेकिन बड़े टेबल्स पर ये बहुत अलग डेटाबेस काम ट्रिगर कर सकते हैं।
पहले स्पष्ट करें कि लोग वास्तव में किस timestamp कॉलम का मतलब रखते हैं। उपयोग करें:
created_at "new items" व्यूज़ के लिएupdated_at "recently changed" व्यूज़ के लिएउस कॉलम पर सामान्य btree इंडेक्स रखें। इसके बिना हर "last 30 days" क्लिक फुल टेबल स्कैन बन सकता है।
Preset ranges अक्सर दिखते हैं जैसे created_at \u003e= now() - interval '30 days'। यह range कंडीशन है, और created_at पर इंडेक्स इसे प्रभावी रूप से उपयोग कर सकता है। अगर UI newest-first सॉर्ट भी करता है, तो सॉर्ट दिशा (उदाहरण के लिए PostgreSQL में created_at DESC) से मेल खाने वाला इंडेक्स भारी उपयोग वाले लिस्ट्स पर मदद कर सकता है।
जब date ranges दूसरे फ़िल्टरों (status, assignee) के साथ मिलते हैं, तो सेलेक्टिव रहें। कंपोजिट इंडेक्स तब शानदार होते हैं जब कॉम्बो सामान्य हो। अन्यथा वे लिखने की लागत बढ़ाते हैं बिना प्रतिफल दिए।
व्यावहारिक नियम:
(status, created_at) मदद कर सकता है।created_at इंडेक्स रखें और बहुत सारे कंपोजिट से बचें।Timezone और बाउंड्रीज़ अक्सर "missing records" बग का कारण होते हैं। अगर यूज़र dates (समय नहीं) चुनते हैं, तो अंत तिथि को कैसे इंटरप्रेट करें यह तय करें। एक सुरक्षित पैटर्न है inclusive start और exclusive end: created_at \u003e= start और created_at \u003c end_next_day। timestamps को UTC में स्टोर करें और यूज़र इनपुट को UTC में बदलकर क्वेरी करें।
उदाहरण: एक ops एडमिन Jan 10 से Jan 12 चुनता है और उम्मीद करता है कि Jan 12 के सारे आइटम दिखेंगे। अगर आपकी क्वेरी \u003c= '2026-01-12 00:00' जैसा प्रयोग करती है, तो आप Jan 12 के अधिकांश आइटम खो देंगे। इंडेक्स ठीक होगा, लेकिन बाउंड्री लॉजिक गलत होगा।
टेक्स्ट सर्च वहां है जहाँ कई एडमिन पैनल धीमे पड़ जाते हैं, क्योंकि लोग एक बॉक्स से सब कुछ खोजने की उम्मीद करते हैं। पहला सुधार यह है कि दो अलग ज़रूरतों को अलग करें: exact match (तेज़ और अनुमानित) बनाम contains search (लचीला, पर भारी)।
Exact match फ़ील्ड्स में order ID, ticket number, email, phone, या कोई external reference शामिल हैं। ये सामान्य डेटाबेस इंडेक्स के लिए परफेक्ट हैं। यदि एडमिन अक्सर किसी ID या email को पेस्ट करते हैं, तो साधारण इंडेक्स और equality क्वेरी इसे तुरंत महसूस कराके दे सकते हैं।
Contains search तब होता है जब कोई ऐसा टुकड़ा टाइप करता है जैसे "refund" या "john" और नामों, नोट्स और विवरणों में मैच की उम्मीद करता है। अक्सर यह LIKE %term% के रूप में लागू किया जाता है। लीडिंग वाइल्डकार्ड का मतलब है कि सामान्य B-tree इंडेक्स खोज को संकुचित नहीं कर सकता, इसलिए डेटाबेस बहुत सारी पंक्तियाँ स्कैन कर देता है।
बिना डेटाबेस पर बोझ डाले सर्च बनाने का व्यावहारिक तरीका:
term%) के लिए एक सामान्य इंडेक्स मदद कर सकता है और अक्सर नामों के लिए ठीक लगता है।LIKE %term% को ठीक कर देगा।इनपुट नियम अधिकतर टीमों की अपेक्षा से ज़्यादा मायने रखते हैं। वे लोड घटाते हैं और परिणामों को सुसंगत बनाते हैं:
एक छोटा उदाहरण: एक सपोर्ट मैनेजर "ann" खोजता है। अगर आपका सिस्टम LIKE %ann% चलाता है नोट्स, नामों और एड्रेस पर, तो यह हजारों रिकॉर्ड स्कैन कर सकता है। अगर आप पहले exact फील्ड्स (email या customer ID) चेक करें और फिर ज़रूरत पर स्मार्ट टेक्स्ट इंडेक्स पर जाएँ, तो सर्च तेज़ रहती है बिना हर क्वेरी को भारी बनाए।
इंडेक्स जोड़ना आसान है और पछताने में भी आसान। एक सुरक्षित वर्कफ़्लो आपको उन फ़िल्टरों पर ध्यान केंद्रित रखने में मदद करता जिन पर आपके एडमिन निर्भर करते हैं, और आपको "शायद उपयोगी" इंडेक्सों से बचाता है जो बाद में writes को धीमा कर दें।
वास्तविक उपयोग से शुरू करें। शीर्ष क्वेरियाँ दो तरीकों से निकालें:
एडमिन पैनलों के लिए, ये आमतौर पर फ़िल्टर और सॉर्टिंग वाले लिस्ट पेज होते हैं।
अगला, डेटाबेस को जैसी क्वेरी दिखती है वैसा ही क्वेरी शेप पकड़ें। सटीक WHERE और ORDER BY लिखें, सॉर्ट दिशा और सामान्य संयोजनों सहित (उदा.: status = 'open' AND assignee_id = 42 ORDER BY created_at DESC)। छोटे अंतर भी तय कर सकते हैं कि कौन सा इंडेक्स मदद करेगा।
एक सरल लूप का उपयोग करें:
Pagination के लिए अलग से जाँच ज़रूरी है। Offset-based pagination (OFFSET 20000) गहराई में जाने पर अक्सर धीमा होता है, भले ही इंडेक्स मौजूद हो। यदि उपयोगकर्ता बहुत गहरे पन्नों पर नियमित रूप से जाते हैं, तो cursor-style pagination ("show items before this timestamp/id") पर विचार करें ताकि इंडेक्स बड़े टेबल्स पर सुसंगत काम करे।
अंत में, एक छोटा रिकॉर्ड रखें ताकि महीनों बाद भी आपकी इंडेक्स सूची समझ में आए: इंडेक्स नाम, तालिका, कॉलम (और क्रम), और क्वेरी जिसे वह समर्थन करता है।
बिना यह देखे कि लोग वास्तव में कैसे फ़िल्टर करते, सॉर्ट और पेज करते हैं, इंडेक्स जोड़ना सबसे तेज़ रास्ता है जिससे एडमिन पैनल धीमा महसूस हो। इंडेक्स जगह लेते हैं और हर insert/update पर काम बढ़ाते हैं।
ये पैटर्न सबसे ज़्यादा समस्याएँ पैदा करते हैं:
LIKE '%term%' जैसे contains सर्च को ठीक होने की उम्मीद रखना।एक सामान्य परिदृश्य: सपोर्ट टीम Tickets को Status = Open से फ़िल्टर करती है, updated time के अनुसार सॉर्ट करती है, और पेज करती है। यदि आपने केवल status पर इंडेक्स जोड़ा है, तो डेटाबेस को सभी open टिकट इकठ्ठा करने और उन्हें सॉर्ट करने की ज़रूरत पड़ सकती है। ऐसा इंडेक्स जो फ़िल्टर और सॉर्ट दोनों से मेल खाता हो, पेज 1 को जल्दी लौट सकता है।
एडमिन UI बदलावों से पहले और बाद में एक छोटा रिव्यू करें:
WHERE + ORDER BY पैटर्न से मेल खाने वाला इंडेक्स है।LIKE '%term%') के लिए जाँच करें और तय करें कि क्या contains search वाकई ज़रूरी है।यदि आप AppMaster पर PostgreSQL में एडमिन पैनल बनाते हैं, तो यह समीक्षा नए स्क्रीन शिप करने का हिस्सा बनाएं। सही इंडेक्स अक्सर उन्हीं फ़िल्टरों और सॉर्ट ऑर्डर्स से सीधे निकलते हैं जो आपका UI उपयोग करता है।
और इंडेक्स जोड़ने से पहले, पुष्टि करें कि आपके पास जो इंडेक्स पहले से हैं वे उन सटीक फ़िल्टरों में मदद कर रहे हैं जिन्हें लोग रोज़ उपयोग करते हैं। एक अच्छा एडमिन पैनल सामान्य पाथ्स पर तुरंत महसूस होना चाहिए, न कि दुर्लभ सर्च पर।
कुछ चेक जो अधिकांश समस्याएँ पकड़ लेते हैं:
WHERE और ORDER BY दोनों से मेल खाती है, सिर्फ़ एक से नहीं।एक व्यावहारिक अगला कदम है अपने गोल्डन पाथ्स को साधारण वाक्यों में लिखना, जैसे: "Support agents filter open tickets, assigned to me, last 7 days, sorted by newest." इन वाक्यों का उपयोग करके एक छोटा सेट इंडेक्स डिजाइन करें जो उन्हें स्पष्ट रूप से सपोर्ट करे।
यदि आप अभी भी बिल्ड के शुरुआती चरण में हैं, तो स्क्रीन बहुत बनाने से पहले अपने डेटा और डिफ़ॉल्ट फ़िल्टर मॉडल करना मददगार होता है। AppMaster (appmaster.io) के साथ आप एडमिन व्यूज़ पर जल्दी इटरेट कर सकते हैं, और फिर असली उपयोग दिखने पर उन कुछ इंडेक्सों को जोड़ें जो वास्तविक हॉट पाथ्स का समर्थन करते हैं।
शुरुआत उन क्वेरियों से करें जो लगातार चलती रहती हैं: वह डिफ़ॉल्ट लिस्ट व्यू जो एडमिन सबसे पहले देखते हैं, और वे 2–3 फ़िल्टर जिन पर वे बार-बार क्लिक करते हैं। उपयोग की आवृत्ति और दर्द (सबसे धीमी और सबसे अधिक उपयोग वाली) को मापें, फिर केवल उन्हीं पर इंडेक्स बनाएं जो वास्तविक क्वेरी शेप्स में स्पष्ट रूप से प्रतीक्षा समय घटाते हों।
क्योंकि अलग-अलग फ़िल्टर अलग मात्रा में काम करवाते हैं। कुछ फ़िल्टर बहुत कम रोज़ाना मिलान करते हैं और जल्दी लौट आते हैं, जबकि दूसरे बड़े रेंज को पढ़ने या बड़े रिज़ल्ट सेट को सॉर्ट करने के लिए मजबूर करते हैं। एक क्वेरी अच्छा इंडेक्स उपयोग कर सकती है और दूसरी फिर भी स्कैन और सॉर्टिंग में फँस सकती है।
नहीं। यदि अधिकांश पंक्तियाँ किसी एक ही status में हैं, तो सिर्फ़ status पर इंडेक्स डालने से ज़्यादा फर्क नहीं पड़ेगा। यह तब उपयोगी होता है जब कोई status दुर्लभ हो, या जब आप उसे ऐसे दूसरे कंडीशन के साथ मिलाएँ जो परिणाम सेट को वास्तव में छोटा कर दे।
ऐसा कंपोजिट इंडेक्स बनाएं जो लोगों के वास्तविक उपयोग को मैच करे — जैसे status द्वारा फ़िल्टर और recent activity द्वारा सॉर्ट। PostgreSQL में partial index एक साफ़ समाधान हो सकता है जब एक status प्रमुख होगा, क्योंकि इससे इंडेक्स छोटा और फोकस्ड रहता है।
एक साधारण इंडेक्स assignee_id पर अक्सर त्वरित जीत देता है, क्योंकि यह equality फ़िल्टर है। अगर “my open items” एक मुख्य वर्कफ़्लो है, तो एक कंपोजिट इंडेक्स जो assignee_id से शुरू हो और फिर status (और ज़रूरत हो तो सॉर्ट कॉलम) शामिल करे, आमतौर पर अलग-अलग single-column इंडेक्सों से बेहतर करता है।
असाइन नहीं किए गए आइटम अक्सर NULL के रूप में स्टोर होते हैं, और WHERE assignee_id IS NULL का व्यवहार WHERE assignee_id = 123 से अलग हो सकता है। यदि unassigned क्यूज़ महत्वपूर्ण हैं, तो उस क्वेरी को विशेष रूप से टेस्ट करें और आवश्यक होने पर partial index जैसी रणनीति अपनाएँ।
लोग जो timestamp फ़िल्टर करते हैं, अक्सर created_at के लिए “new items” और updated_at के लिए “recently changed” का मतलब रखते हैं। उन कॉलमों पर सामान्य btree इंडेक्स रखें; बिना इंडेक्स के last 30 days जैसा क्लिक अक्सर फुल टेबल स्कैन बन सकता है। अगर UI सबसे नया दिखाने के लिए सॉर्ट भी करता है, तो soring direction को मैच करना फायदे में हो सकता है।
ज़्यादातर missing-record बग डेट बाउंड्रीज़ से आते हैं, इंडेक्स से नहीं। एक भरोसेमंद पैटर्न है inclusive start और exclusive end: उपयोगकर्ता द्वारा चुनी गई तारीखों को UTC में बदलें और क्वेरी करें \u003e= start और \u003c end_next_day ताकि आप अंत की तारीख के बाद होने वाली घटनाओं को गलती से न हटाएँ।
क्योंकि LIKE %term% जैसे contains क्वेरीज एक सामान्य btree इंडेक्स का उपयोग नहीं कर पातीं, इसलिए वे बहुत सी पंक्तियों को स्कैन कर देती हैं। सटीक लुकअप (ID, email, order number) को प्राथमिक रखें, और केवल तभी contains search जोड़ें जब लॉग्स या शिकायतें दिखाएँ कि यह ज़रूरी है — और तब PostgreSQL full-text search या trigram इंडेक्स जैसा सही टूल उपयोग करें।
बहुत सारे इंडेक्स जोड़ने से स्टोरेज बढ़ता है और inserts/updates धीमे होते हैं, और यदि इंडेक्स WHERE + ORDER BY पैटर्न से मेल नहीं खाता तो असली बॉटलनेक नहीं मिलता। एक सुरक्षित तरीका है: एक समय में एक इंडेक्स बदलें, उसी धीमी क्वेरी के साथ पुनःमाप करें, और केवल वे परिवर्तन रखें जो स्पष्ट रूप से हॉट पाथ को बेहतर बनाएँ।\n\nअगर आप AppMaster में एडमिन स्क्रीन बनाते हैं, तो टीम जिन फ़िल्टरों और सॉर्ट्स का सबसे ज्यादा उपयोग करती है उन्हें लॉग करें और उन्हीं वास्तविक व्यूज़ के लिए छोटा सेट इंडेक्स बनाएँ बजाय हर फ़ील्ड को इंडेक्स करने के।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


