उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
आंतरिक उपकरणों के लिए व्यावहारिक ऑडिट लॉगिंग: हर CRUD परिवर्तन पर यह ट्रैक करें कि किसने क्या और कब किया, बदलावों के अंतर (diffs) सुरक्षित रखें, और एक एडमिन गतिविधि फ़ीड दिखाएँ।
ज़्यादातर टीमें तब ऑडिट लॉग जोड़ती हैं जब कुछ गलत हो चुका होता है। कोई ग्राहक किसी परिवर्तन पर विवाद करता है, कोई फ़ाइनेंस नंबर हिलता है, या ऑडिटर पूछता है, "यह किसने मंज़ूर किया?" अगर आप तभी शुरू करते हैं तो आपको आंशिक सुरागों से अतीत को फिर से reconstruct करना पड़ता है: डेटाबेस टाइमस्टैम्प्स, Slack संदेश और अनुमान।
ज्यादातर आंतरिक ऐप्स के लिए "कम्प्लायंस के लिए काफी" का मतलब परफ़ेक्ट फॉरेंसिक सिस्टम नहीं होता। इसका मतलब है कि आप कुछ छोटे सवालों का तेज़ और सुसंगत जवाब दे सकें: किसने बदलाव किया, कौन सा रिकॉर्ड प्रभावित हुआ, क्या बदला, कब हुआ, और कहाँ से आया (UI, import, API, automation)। यही स्पष्टता है जो ऑडिट लॉग पर भरोसा बनाती है।
जहाँ ऑडिट लॉग अक्सर फेल होते हैं वह डेटाबेस नहीं, बल्कि कवरेज है। इतिहास सादे एडिट्स के लिए ठीक दिखता है, लेकिन जैसे ही काम तेज़ी से होता है गैप दिखाई देते हैं। आम दोषी हैं: बल्क एडिट्स, इम्पोर्ट्स, शेड्यूल्ड जॉब्स, एडमिन क्रियाएँ जो सामान्य स्क्रीन बायपास करती हैं (जैसे पासवर्ड रीसेट या रोल बदलना), और डिलीट्स (ख़ासकर हार्ड डिलीट)।
एक और सामान्य विफलता डिबग लॉग्स और ऑडिट लॉग्स को मिलाना है। डिबग लॉग डेवलपर्स के लिए होते हैं: शोर वाले, तकनीकी और अक्सर अनियमित। ऑडिट लॉग जवाबदेही के लिए होते हैं: सुसंगत फ़ील्ड, स्पष्ट शब्दावली और एक स्थिर फ़ॉर्मैट जिसे आप गैर-इंजीनियर को भी दिखा सकें।
एक व्यावहारिक उदाहरण: एक सपोर्ट मैनेजर ग्राहक की योजना बदलता है, फिर बाद में एक ऑटोमेशन बिलिंग विवरण अपडेट कर देता है। अगर आपने सिर्फ "updated customer" लॉग किया है, तो आप नहीं बता पाएँगे कि किसने किया—इंसान ने, वर्कफ़्लो ने, या किसी इम्पोर्ट ने ओवरराइट किया।
अच्छा ऑडिट लॉग एक लक्ष्य से शुरू होता है: किसी व्यक्ति को एक एंट्री पढ़कर अंदाज़ा लगाए बिना समझ आना चाहिए कि क्या हुआ।
हर परिवर्तन के लिए एक स्पष्ट actor स्टोर करें। अधिकांश टीमें केवल "user id" तक रुक जाती हैं, लेकिन आंतरिक टूल अक्सर डेटा को एक से अधिक रास्ते से बदलते हैं।
actor_type और actor_identifier शामिल करें ताकि आप स्टाफ सदस्य, सर्विस अकाउन्ट, या एक्सटर्नल इंटीग्रेशन में फर्क बता सकें। अगर आपकी ऐप में टीमें या टेनेंट्स हैं, तो organization या workspace id भी स्टोर करें ताकि घटनाएँ कभी मिक्स न हों।
एक्शन (create, update, delete, restore) के साथ टारगेट को कैप्चर करें। "Target" दोनों मानव-पठनीय और सटीक होना चाहिए: तालिका या एंटिटी नाम, रिकॉर्ड id, और आदर्श रूप में एक छोटा लेबल (जैसे order नंबर) जल्दी स्कैनिंग के लिए।
एक व्यावहारिक न्यूनतम फ़ील्ड सेट:
टाइमस्टैम्प हमेशा UTC में स्टोर करें। फिर एडमिन UI में इसे व्यूअर के लोकल समय में दिखाएँ। इससे समीक्षा के दौरान "दो लोगों ने अलग समय देखा" जैसे तर्क बचते हैं।
यदि आप उच्च जोखिम की क्रियाएँ संभालते हैं जैसे रोल चेंज, रिफंड या डेटा एक्सपोर्ट, तो एक "reason" फ़ील्ड जोड़ें। एक छोटा नोट भी—"Ticket 1842 में मैनेजर ने मंज़ूर किया"—ऑडिट ट्रेल को शोर से सबूत में बदल सकता है।
पहला डिज़ाइन विकल्प यह है कि परिवर्तन इतिहास की "सच्चाई" कहाँ रहती है। अधिकांश टीमें दो मॉडलों में से एक पर आती हैं: एक append-only इवेंट लॉग, या प्रति-एंटिटी वर्शन हिस्ट्री टेबल्स।
इवेंट लॉग एक सिंगल टेबल है जो हर क्रिया को एक नई पंक्ति के रूप में रिकॉर्ड करती है। हर पंक्ति बताती है किसने किया, कब हुआ, किस एंटिटी को छुआ गया, और एक payload (अकसर JSON) जो परिवर्तन का विवरण देता है।
यह मॉडल जोड़ने में सीधा और आपके डेटा मॉडल के विकसित होने पर लचीला होता है। यह एडमिन गतिविधि फ़ीड से भी नैचुरल मैप करता है क्योंकि फ़ीड मूलतः "न्यूएस्ट इवेंट्स पहले" होता है।
वर्शनड हिस्ट्री अप्रोच प्रति एंटिटी हिस्ट्री टेबल बनाती है, जैसे Order_history या User_versions, जहाँ हर अपडेट एक नया पूरा स्नैपशॉट (या बदले गए फ़ील्ड्स का संरचित सेट) बनाता है और एक वर्शन नंबर जुड़ता है।
यह पॉइंट-इन-टाइम रिपोर्टिंग को आसान बनाता है ("यह रिकॉर्ड पिछले मंगलवार को कैसा दिखता था?")। यह ऑडिटर्स के लिए भी साफ़ लग सकता है क्योंकि हर रिकॉर्ड की टाइमलाइन स्वयं में संपूर्ण रहती है।
चुनने का व्यावहारिक तरीका:
जिसे भी आप चुनें, ऑडिट एंट्रीज़ को immutable रखें: कोई updates, कोई deletes नहीं। अगर कुछ गलत हुआ था, तो एक नई एंट्री जोड़ें जो सुधार की व्याख्या करे।
एक correlation_id (या operation id) जोड़ना भी विचार करें। एक उपयोगकर्ता कार्रवाई अक्सर कई परिवर्तनों को ट्रिगर करती है (उदाहरण: "Deactivate user" यूज़र को अपडेट करता है, सत्र रिवोक करता है, और पेंडिंग टास्क रद्द करता है)। एक साझा correlation id उन पंक्तियों को एक पठनीय ऑपरेशन में समूहित करने देता है।
विश्वसनीय ऑडिट लॉगिंग एक नियम से शुरू होती है: हर write एक ही पथ से होकर जाए जो ऑडिट इवेंट भी लिखता है। अगर कुछ अपडेट बैकग्राउंड जॉब, इम्पोर्ट या तेज़-एडिट स्क्रीन में होते हैं जो सामान्य सेव फ़्लो को बायपास करते हैं, तो आपके लॉग्स में छेद होंगे।
Creates के लिए actor और source (UI, API, import) रिकॉर्ड करें। इम्पोर्ट्स वह जगह हैं जहाँ टीमें अक्सर "किसने किया" खो देती हैं, इसलिए एक स्पष्ट "performed by" मान स्टोर करें भले ही डेटा फ़ाइल या इंटीग्रेशन से आया हो। प्रारंभिक मान (या तो पूरा स्नैपशॉट या कुछ प्रमुख फ़ील्ड्स) स्टोर करना भी उपयोगी होता है ताकि आप बता सकें कि रिकॉर्ड क्यों मौजूद है।
Updates ज़्यादा झटिल हैं। आप केवल बदले हुए फ़ील्ड्स लॉग कर सकते हैं (छोटा, पठनीय और तेज़), या हर सेव के बाद एक पूरा स्नैपशॉट स्टोर कर सकते हैं (बाद में क्वेरी करने में सरल, पर भारी)। एक व्यावहारिक मध्य मार्ग यह है कि सामान्य संपादनों के लिए diffs स्टोर करें और संवेदनशील ऑब्जेक्ट्स (जैसे permissions, बैंक विवरण, या प्राइसिंग नियम) के लिए सिर्फ़ स्नैपशॉट रखें।
Deletes साक्ष्य मिटाना नहीं चाहिए। एक soft delete पसंद करें (एक is_deleted फ़्लैग प्लस एक ऑडिट एंट्री)। अगर आपको हार्ड डिलीट करनी ही है, तो पहले ऑडिट इवेंट लिखें और रिकॉर्ड का एक स्नैपशॉट शामिल करें ताकि आप साबित कर सकें कि क्या हटाया गया था।
Undelete को अपनी एक अलग कार्रवाई मानें। "Restore" को "Update" के समान न समझें—इन्हें अलग रखने से समीक्षा और अनुपालन जांच आसान होती है।
बल्क एडिट्स के लिए, एक अस्पष्ट एंट्री जैसे "updated 500 records" से बचें। बाद में यह जवाब देना ज़रूरी होगा कि "कौन से रिकॉर्ड्स बदले?" एक व्यावहारिक पैटर्न पैरेंट इवेंट और प्रति-रिकॉर्ड चाइल्ड इवेंट है:
उदाहरण: एक सपोर्ट लीड 120 टिकट्स बल्क-क्लोज़ करता है। पैरेंट एंट्री में फ़िल्टर कैप्चर होता है "status=open, older than 30 days," और प्रत्येक टिकट को एक चाइल्ड एंट्री मिलती है जो दिखाती है status open -> closed।
ऑडिट लॉग तब जल्दी बेकार बन जाते हैं जब वे या तो बहुत ज़्यादा स्टोर करते हैं (हर पूरा रिकॉर्ड, हमेशा) या बहुत कम (सिर्फ "edited user")। लक्ष्य ऐसा रिकॉर्ड होना चाहिए जो अनुपालन के लिए बचाव योग्य और एडमिन द्वारा पठनीय हो।
एक व्यावहारिक डिफ़ॉल्ट यह है कि अधिकांश अपडेट्स के लिए फ़ील्ड-स्तरीय diff स्टोर करें। केवल बदले गए फ़ील्ड स्टोर करें, साथ में "before" और "after" वैल्यू। इससे स्टोरेज कम रहता है और एक्टिविटी फ़ीड स्कैन करना आसान होता है: "Status: Pending -> Approved" बड़ी blob की तुलना में स्पष्ट है।
वो क्षण जब फर्क पड़ता है—creates, deletes और बड़े वर्कफ़्लो ट्रांज़िशन्स—उनके लिए पूर्ण स्नैपशॉट रखें। स्नैपशॉट भारी होते हैं, पर जब कोई पूछे "ग्राहक प्रोफ़ाइल हटने से पहले बिल्कुल कैसी दिखती थी?" तब वे सुरक्षा करते हैं।
संवेदनशील डेटा के लिए मास्किंग नियम लागू करें, नहीं तो आपकी ऑडिट तालिका राज़ों से भर जाएगी। सामान्य नियम:
स्कीमा चेंजेस भी ऑडिट इतिहास तोड़ सकते हैं। यदि बाद में कोई फ़ील्ड रीनैम या रिमूव हो जाता है, तो एक सुरक्षित फॉलबैक रखें जैसे "unknown field" साथ ही ओरिजिनल फ़ील्ड की-। हटाए गए फ़ील्ड्स के लिए अंतिम ज्ञात मान रखें पर उसे "field removed from schema" चिह्नित करें ताकि फ़ीड ईमानदार रहे।
अंत में, एंट्रीज़ को मानव-पठनीय बनाएं। raw keys ("assignee_id") के साथ डिस्प्ले लेबल ("Assigned to") रखें, और मानों को फ़ॉर्मैट करें (तिथियाँ, मुद्रा, स्टेटस नाम)।
एक भरोसेमंद ऑडिट ट्रेल ज्यादा लॉग करने के बारे में नहीं है। यह हर जगह एक ही दोहराए जाने योग्य पैटर्न का उपयोग करने के बारे में है ताकि आप गैप्स जैसे "बल्क इम्पोर्ट लॉग नहीं हुआ" या "मोबाइल एडिट्स अनाम दिखते हैं" से बच सकें।
अपने डेटा मॉडल में शुरू करें और एक छोटा सेट टेबल बनाएं जो किसी भी परिवर्तन का वर्णन कर सके।
इसे सरल रखें: एक टेबल इवेंट के लिए, एक टेबल बदले गए फ़ील्ड्स के लिए, और एक छोटा actor context।
एक पुन:उपयोगी सब-प्रोसेस बनाएं जो:
कठोर नियम: हर write पाथ को इस ही सब-प्रोसेस को कॉल करना चाहिए। इसमें UI बटन, API एंडपॉइंट्स, शेड्यूल्ड ऑटोमेशन्स और इंटीग्रेशन्स शामिल हैं।
"किसने" और "कब" के लिए ब्राउज़र पर भरोसा न करें। actor को अपने auth session से पढ़ें, और टाइमस्टैम्प सर्वर-साइड जनरेट करें। अगर कोई ऑटोमेशन चल रही है, तो actor_type को system सेट करें और जॉब का नाम actor label के रूप में स्टोर करें।
एक रिकॉर्ड चुनें (जैसे ग्राहक टिकट): इसे बनाएं, दो फ़ील्ड संपादित करें (status और assignee), फिर डिलीट करें, और फिर restore करें। आपका ऑडिट फ़ीड पाँच इवेंट दिखाना चाहिए, एडिट इवेंट के तहत दो update आइटम, और हर बार actor और टाइमस्टैम्प उसी तरह भरे होने चाहिए।
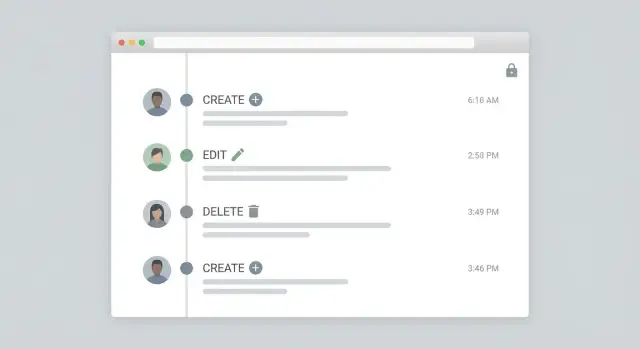
एक ऑडिट लॉग तभी उपयोगी है जब कोई समीक्षा या घटना के दौरान उसे तेज़ी से पढ़ सके। एडमिन फ़ीड का लक्ष्य सरल है: एक नज़र में "क्या हुआ?" का जवाब दें, फिर बिना लोगों को कच्चे JSON में डुबोए गहराई से देखने की अनुमति दें।
टाइमलाइन लेआउट से शुरू करें: न्यूएस्ट पहले, एक पंक्ति प्रति इवेंट, और स्पष्ट क्रियाएँ जैसे Created, Updated, Deleted, Restored। हर रो में actor (व्यक्ति या सिस्टम), टारगेट (रिकॉर्ड टाइप और मानव-पठनीय नाम), और समय दिखाएँ।
एक व्यावहारिक रो फ़ॉर्मैट:
"क्या बदला" को संक्षिप्त रखें। 1–3 फ़ील्ड इनलाइन दिखाएँ, फिर एक ड्रिल-डाउन पैनल (drawer/modal) दें जो पूर्ण विवरण प्रकट करे: before/after वैल्यूज़, request source (web, mobile, API), और कोई reason/comment फ़ील्ड।
फ़िल्टरिंग फ़ीड को पहले सप्ताह के बाद उपयोगी बनाती है। उन फ़िल्टर्स पर ध्यान दें जो असली सवालों से मेल खाते हैं:
लिंकिंग मायने रखती है, पर केवल जब अनुमति हो। अगर व्यूअर को प्रभावित रिकॉर्ड का एक्सेस है, तो "View record" एक्शन दिखाएँ। अगर नहीं, तो एक सुरक्षित प्लेसहोल्डर दिखाएँ (उदा., "Restricted record") जबकि ऑडिट एंट्री दिखाई देती रहे।
सिस्टम एक्शन्स को स्पष्ट बनाएं। शेड्यूल्ड जॉब्स और इंटीग्रेशन्स को अलग लेबल करें ताकि एडमिन्स बता सकें "Dana ने हटाया" और "Nightly billing sync ने अपडेट किया" में फर्क।
ऑडिट लॉग सबूत होते हैं, पर वे संवेदनशील डेटा भी होते हैं। ऑडिट लॉगिंग को अपनी ऐप के अंदर एक अलग प्रोडक्ट की तरह ट्रीट करें: स्पष्ट एक्सेस नियम, स्पष्ट सीमाएँ, और व्यक्तिगत जानकारी का सावधानीपूर्वक हैंडलिंग।
निर्धारित करें कि कौन क्या देख सकता है। एक सामान्य विभाजन ऐसा हो सकता है: सिस्टम एडमिन सब कुछ देख सकते हैं; विभागीय मैनेजर अपनी टीम के इवेंट्स देख सकते हैं; रिकॉर्ड मालिक केवल उन रिकॉर्ड्स के इवेंट्स देख सकते हैं जिनका वे पहले से एक्सेस रखते हैं। अगर आप गतिविधि फ़ीड दिखाते हैं, तो हर रो पर वही नियम लागू करें, न कि सिर्फ़ स्क्रीन पर।
मल्टी-टेनेंट या क्रॉस-डिपार्टमेंट टूल्स में रो-स्तरीय दृश्यता सबसे ज़रूरी है। आपकी ऑडिट तालिका में वही स्कोपिंग कीज़ होनी चाहिए जो बिज़नेस डेटा में (tenant_id, department_id, project_id), ताकि आप लगातार फ़िल्टर कर सकें। उदाहरण: एक सपोर्ट मैनेजर अपने क्यू के टिकट्स के बदलाव देख सके, पर HR में हुए सैलरी समायोजनों को नहीं, भले ही दोनों उसी ऐप में हों।
एक सरल नीति जो व्यवहार में काम करती है:
प्राइवेसी नीति इसका दूसरा हिस्सा है। साबित करने के लिए पर्याप्त स्टोर करें, पर लॉग को अपनी डेटाबेस की दूसरी कॉपी न बनाएं। संवेदनशील फ़ील्ड्स (SSNs, मेडिकल नोट्स, पेमेंट डिटेल्स) के लिए रेडैक्शन पसंद करें: बताइए कि फ़ील्ड बदला पर पुरानी/नई वैल्यू स्टोर न करें। आप "email changed" लॉग कर सकते हैं जबकि वास्तविक वैल्यू मास्क की हुई हो, या सत्यापन के लिए एक हैश्ड फ़िंगरप्रिंट रख सकते हैं।
सिक्योरिटी इवेंट्स को बिज़नेस रिकॉर्ड परिवर्तनों से अलग रखें। लॉगिन प्रयास, MFA रीसेट, API की क्रिएशन और रोल चेंजलॉग्स tighter access और लंबी retenion वाले security_audit स्ट्रीम में जाएँ। बिज़नेस एडिट्स (status updates, approvals, workflow changes) सामान्य audit स्ट्रीम में रह सकते हैं।
जब कोई व्यक्तिगत डेटा हटाने की मांग करे, तो पूरा ऑडिट ट्रेल मिटाएँ मत। इसके बजाय:
एक उपयोगी ऑडिट लॉग सिर्फ़ "हम इवेंट रिकॉर्ड करते हैं" से आगे जाता है। अनुपालन के लिए आपको तीन बातों को साबित करना होगा: आपने डेटा पर्याप्त समय तक रखा, उसे बाद में बदला नहीं गया, और जब पूछा जाए तो आप जल्दी निकाल सकें।
अपने जोखिम के अनुसार एक सरल नियम से शुरू करें। कई टीमें दिन-प्रतिदिन ट्रबलशूटिंग के लिए 90 दिन, आंतरिक अनुपालन के लिए 1–3 साल और केवल विनियमन वाले रिकॉर्ड्स के लिए लंबा रखती हैं। लिखें कि क्लॉक क्या रीसेट करता है (अकसर: घटना का समय) और क्या बाहर रखा जाता है (उदा., वे लॉग्स जिनमें आप नहीं रखना चाहते)।
यदि आपके पास कई वातावरण हैं, तो वातावरण के अनुसार अलग रिटेंशन सेट करें। प्रोडक्शन लॉग्स को आमतौर पर सबसे लंबी रिटेंशन चाहिए; टेस्ट लॉग्स अक्सर जरूरी नहीं होते।
ऑडिट लॉग्स को append-only मानें। रॉज़ को अपडेट न करें, और सामान्य एडमिन्स को उन्हें डिलीट करने की अनुमति न दें। अगर किसी डिलीट की असली ज़रूरत है (कानूनी अनुरोध, डेटा क्लीनअप), तो उस क्रिया को भी एक इवेंट के रूप में रिकॉर्ड करें।
एक व्यावहारिक पैटर्न:
ऑडिटर्स अक्सर CSV या JSON मांगते हैं। एक ऐसा एक्सपोर्ट प्लान करें जो तारीख़ रेंज और ऑब्जेक्ट टाइप (जैसे Invoice, User, Ticket) द्वारा फ़िल्टर कर सके ताकि आप डेटाबेस को सबसे खराब समय पर हाथ से क्वेरी न कर रहे हों।
प्रदर्शन के लिए, उसी तरह इंडेक्स करें जिस तरह आप खोजते हैं:
साइलेंट फ़ेलियर पर नजर रखें। अगर ऑडिट राइट विफल हो रहा है, तो आप साक्ष्य खो देते हैं और अक्सर नोटिस नहीं करेंगे। एक साधारण अलर्ट जोड़ें: अगर ऐप लिखता है पर ऑडिट इवेंट्स एक अवधि के लिए शून्य पर गिर जाएँ, तो मालिकों को नोटिफ़ाई करें और एरर को जोर से लॉग करें।
सबसे तेज़ तरीका समय बर्बाद करने का है बहुत सी पंक्तियाँ इकट्ठा करना जो असली सवालों का जवाब नहीं देतीं: किसने क्या बदला, कब और कहाँ से।
एक सामान्य जाल केवल डेटाबेस ट्रिगर्स पर निर्भर करना है। ट्रिगर्स रिकॉर्ड कर सकते हैं कि एक पंक्ति बदली, पर वे अक्सर बिज़नेस संदर्भ चूक जाते हैं: उपयोगकर्ता ने कौन सा स्क्रीन इस्तेमाल किया, किस अनुरोध ने इसे किया, किस रोल के साथ था, और क्या यह सामान्य एडिट था या कोई ऑटोमेटेड नियम।
गलतियाँ जो सबसे ज़्यादा अनुपालन और दिन-प्रतिदिन उपयोगिता तोड़ती हैं:
प्रारंभ में अपने इवेंट शब्दावली को मानकीकृत करें (उदा.: user.created, user.updated, invoice.voided, access.granted) और हर write पाथ से एक इवेंट जारी करने की ज़रूरत रखें। ऑडिट डेटा को write-once मानें: अगर किसी ने गलत परिवर्तन किया, तो एक नया corrective action लॉग करें बजाय इतिहास को फिर से लिखने के।
खत्म कहने से पहले कुछ तेज़ जांचें। एक अच्छा ऑडिट लॉग सर्वश्रेष्ठ तरीके से बोरिंग होता है: पूरा, सुसंगत, और जब कुछ गलत हो तो पढ़ने में आसान।
रियलिस्टिक डेटा के साथ टेस्ट वातावरण में यह चेकलिस्ट चलाएँ:
अगर आप आंतरिक टूल AppMaster (appmaster.io) के साथ बना रहे हैं, तो कवरेज बनाए रखने का एक व्यावहारिक तरीका यह है कि UI एक्शन्स, API एंडपॉइंट्स, इम्पोर्ट्स और ऑटोमेशन्स को उसी Business Process पैटर्न के जरिए रूट करें जो डेटा परिवर्तन और ऑडिट इवेंट दोनों लिखता है। इस तरह आपका CRUD ऑडिट ट्रेल स्क्रीन और वर्कफ़्लोज़ बदलने पर भी सुसंगत रहता है।
एक workflow से छोटी शुरुआत करें जो मायने रखती है (tickets, approvals, billing changes), एक्टिविटी फ़ीड को पठनीय बनाएं, फिर तब तक बढ़ाएँ जब तक हर राइट पाथ एक पूर्वानुमेय, सर्चेबल ऑडिट इवेंट नहीं छोड़ता।
जब भी टूल वास्तविक डेटा बदल सकता हो, उसी समय ऑडिट लॉग जोड़ दें। पहला विवाद या ऑडिट अनुरोध अक्सर तब आता है जब आप सोचते हैं कि आप “तैयार” नहीं हैं, और बाद में इतिहास भरना ज्यादातर अंधाधुंध अनुमान होता है।
एक उपयोगी ऑडिट लॉग यह तुरंत बता सके कि किसने किया, कौन सा रिकॉर्ड प्रभावित हुआ, क्या बदला, कब हुआ, और कहाँ से आया (UI, API, import, या job)। अगर आप इन में से किसी का जल्दी जवाब नहीं दे पाते तो लोग लॉग पर भरोसा नहीं करेंगे।
डिबग लॉग डेवलपर्स के लिए होते हैं और अक्सर शोर वाले व अनियमित होते हैं। ऑडिट लॉग जवाबदेही के लिए होते हैं—इनमें स्थिर फ़ील्ड, स्पष्ट शब्दावली और एक ऐसा फ़ॉर्मैट होना चाहिए जो गैर-इंजीनियर्स के लिए भी समय के साथ पठनीय रहे।
कवरेज तब फेल होती है जब परिवर्तन सामान्य एडिट स्क्रीन के बाहर होते हैं। बल्क एडिट्स, इम्पोर्ट्स, शेड्यूल्ड जॉब्स, एडमिन शॉर्टकट और डिलीट्स वे आम जगहें हैं जहाँ टीम अक्सर ऑडिट इवेंट्स छोड़ देती है।
actor_type और actor identifier स्टोर करें, सिर्फ़ user ID नहीं। इससे आप एक स्टाफ सदस्य, सिस्टम जॉब, सर्विस अकाउन्ट या बाहरी इंटीग्रेशन में फर्क बता सकेंगे और “किसी ने किया” जैसी अस्पष्टता बच जाएगी।
डेटाबेस में timestamps UTC में स्टोर करें, और एडमिन UI में व्यूअर के लोकल टाइम में दिखाएँ। इससे टाइमज़ोन के विवाद बचते हैं और एक्सपोर्ट्स भी संगत रहते हैं।
एक स्थान पर खोज और आसान गतिविधि फ़ीड के लिए append-only event log चुनें। यदि आपको अक्सर किसी एक रिकॉर्ड का point-in-time दृश्य चाहिए तो per-entity versioned history चुनें; कई ऐप्स में field-level diffs के साथ event log अधिक सस्टेनेबल रहता है।
साक्ष्य मिटाने से बचने के लिए soft delete पसंद करें और delete क्रिया को स्पष्ट रूप से लॉग करें। यदि आपको hard delete करनी ही है तो पहले ऑडिट इवेंट लिखें और रिकॉर्ड का स्नैपशॉट या प्रमुख फ़ील्ड शामिल करें ताकि बाद में साबित किया जा सके क्या हटाया गया था।
अपडेट्स के लिए डिफ़ॉल्ट रूप से field-level diffs स्टोर करें और creates/deletes के लिए स्नैपशॉट रखें। संवेदनशील फ़ील्ड्स के लिए वैल्यू स्टोर करने के बजाय यह रिकॉर्ड करें कि वैल्यू बदली, और व्यक्तिगत डेटा को रेडैक्ट/मास्क करें ताकि ऑडिट लॉग आपकी डेटाबेस की दूसरी कॉपी न बन जाए।
एक साझा “write + audit” पाथ बनाएँ और हर राइट को उसी के ज़रिए होने पर ज़ोर दें—UI, API, इम्पोर्ट, बैकग्राउंड जॉब्स सहित। AppMaster में टीमें अक्सर यह एक पुन:उपयोगी Business Process के रूप में लागू करती हैं जो एक ही फ्लो में डेटा परिवर्तन और ऑडिट इवेंट दोनों लिखता है ताकि गैप न रहे।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


